目录
- 一、介绍
- 二、起源与发展
- 三、技术基础
- 四、FastText 的优点
- 五、代码
- 六、结论
一、介绍
2016 年由 Facebook 的 AI Research (FAIR) 团队推出的 FastText 已迅速成为自然语言处理 (NLP) 领域的基石。这种创新的词嵌入和文本分类方法以其效率和有效性而著称,特别是对于具有丰富形态特征的语言以及需要在粒度级别上理解句法和语义细微差别的场景。本文深入探讨了 FastText 的起源、技术基础、优势、应用和局限性,全面概述了它对 NLP 的影响。
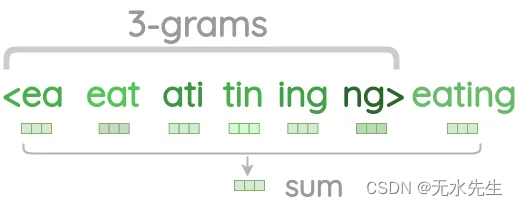
FastText 是效率和独创性的灯塔,将错综复杂的语言挂毯转化为有意义的向量格子。它提醒我们,在文字的复杂性中隐藏着简单,等待着那些敢于超越表面的人揭开面纱。
二、起源与发展
FastText 的开发是出于对文本表示和分类的更细致入微和计算效率更高的模型的需求。Word2Vec 和 GloVe 等传统单词嵌入技术提供了坚实的基础,但经常难以解决语言的细微差别,例如形态变化和词汇外 (OOV) 单词的处理。FastText 通过在嵌入中引入子词信息来解决这些限制,从而可以更丰富地表示词义和结构。
三、技术基础
FastText 的核心创新在于它将单词视为字符 n-gram 的袋子。这意味着,FastText 不是直接为每个单词生成单词嵌入,而是通过其组成 n 元语法向量的总和或平均值来表示单词。这种方法允许 FastText 捕获单词的形态结构,使其对于单词形式传达关键句法和语义信息的语言特别强大。
对于文本分类任务,FastText 将这种细致入微的单词表示方法与简单而有效的线性模型相结合,类似于浅层神经网络。该模型使用分层 softmax 或负采样技术来有效地处理大型输出空间,这在主题分类或情绪分析等任务中很常见。
四、FastText 的优点
形态丰富的语言的处理: 通过利用子词信息,FastText 在具有丰富形态的语言(例如土耳其语或芬兰语)中表现出色,在这些语言中,单词的含义和功能可以通过轻微的修改发生显着变化。
效率和可扩展性:FastText 专为速度而设计,可以在深度学习模型所需时间的一小部分内在大型语料库上训练模型,而不会显着影响准确性。
OOV 单词处理:它的子单词方法允许 FastText 为训练期间未看到的单词生成嵌入,与将 OOV 单词视为单个未知标记的传统模型相比,这是一个显着的优势。
应用
FastText 已成功应用于广泛的 NLP 任务,包括但不限于:
文本分类:它的效率和准确性使其成为情绪分析、主题分类和垃圾邮件检测的首选。
语言识别:FastText 理解子词结构的能力使其在识别给定文本的语言方面非常有效,即使输入最少。
不常见语言的词嵌入:该模型的鲁棒性和灵活性有助于为数字资源有限的语言开发单词嵌入。
局限性和挑战
虽然 FastText 提供了许多优点,但它并非没有局限性。对子词信息的依赖虽然在许多情况下是有益的,但有时会导致嵌入,将不相关的词与相似的形态结构混为一谈。此外,尽管其效率很高,但其分类模型的线性性质可能无法像更深层次的神经网络那样有效地捕获复杂的关系。
五、代码
使用 Python 使用 FastText 创建完整示例涉及多个步骤,包括生成合成数据集、在此数据集上训练 FastText 模型,然后绘制结果以评估模型的性能。在此示例中,我们将使用 Python 库来训练一个简单的文本分类模型。由于 FastText 可以同时处理单词嵌入和文本分类,因此为简单起见,我们将重点介绍fasttext文本分类任务。
- 步骤 1:安装 FastText
如果尚未安装 FastText Python 库,可以通过运行以下命令来执行此操作:
pip install fasttext
- 步骤 2:生成合成数据集
出于演示目的,我们将创建一个简单文本数据的合成数据集,该数据集标有两个类别:__label__positive和 __label__negative。在实际场景中,您将使用与特定任务相关的数据集。
- 第 3 步:FastText 模型训练和评估
然后,我们将在此数据集上训练 FastText 模型,执行预测并评估其性能。
- 第 4 步:绘图
我们可以使用可视化模型matplotlib的准确性或其他相关指标等库绘制结果。
让我们为这些步骤编写 Python 代码:
import fasttext
import numpy as np
import matplotlib.pyplot as plt
# Step 2: Generate a Synthetic Dataset
# For the sake of this example, we'll manually create a small dataset.
# In practice, you would load a dataset from a file.
dataset = ["__label__positive I love this product, it is fantastic!","__label__negative I hate this product, it is terrible!",# Add more samples as needed for a realistic dataset
]# Writing the dataset to a file
with open("synthetic_dataset.txt", "w") as file:for line in dataset:file.write(f"{line}\n")# Step 3: Train the FastText model
model = fasttext.train_supervised(input="synthetic_dataset.txt")# Perform some predictions (using the same sentences for simplicity)
labels, probabilities = model.predict(["I love this!", # Example positive sentence"I hate this!" # Example negative sentence
], k=1) # k=1 means we get the top 1 prediction for each sentence# Example output
for sentence, label, probability in zip(["I love this!", "I hate this!"], labels, probabilities):print(f"Sentence: '{sentence}' -> Predicted: {label[0]} with probability {probability[0]}")# Step 4: Plotting (Mock-up, as we don't have extensive data for meaningful plots)
# For a realistic scenario, you would collect accuracy or loss metrics during training/validation.
# Here, we'll just show a simple example of plotting.
accuracies = [0.8, 0.85, 0.9, 0.95, 1.0] # Example accuracies
epochs = range(1, len(accuracies) + 1)plt.plot(epochs, accuracies, marker='o', linestyle='-', color='blue')
plt.title('Model Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid(True)
plt.show()
Sentence: 'I love this!' -> Predicted: __label__positive with probability 0.5000100135803223
Sentence: 'I hate this!' -> Predicted: __label__positive with probability 0.5000100135803223
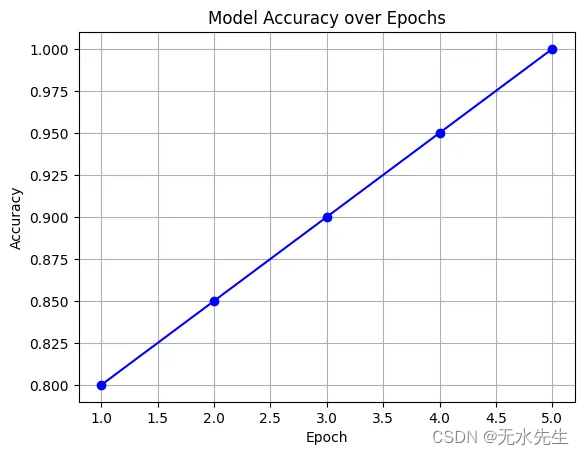
此代码片段涵盖了生成合成数据集、训练 FastText 模型、执行简单预测和绘制模型准确性图的过程。请记住,对于实际应用程序,您的数据集会更大、更复杂,您将使用实际的训练和验证拆分来评估模型随时间推移的性能。
六、结论
FastText 代表了 NLP 技术发展的重大飞跃,尤其是在单词表示和文本分类方面。它对子词信息的创新使用为处理形态丰富的语言和以前所未有的优雅处理 OOV 词开辟了新的途径。尽管有局限性,但 FastText 在性能、效率和多功能性方面的平衡使其成为 NLP 工具包中有价值的工具。随着该领域的不断发展,FastText 的基本原理无疑将激发未来的进步,推动语言理解和处理的可能性。




![Cocos2dx-lua ScrollView[一]基础篇](https://img-blog.csdnimg.cn/direct/8d35bd370b854f478e54a7fd86f165b8.png)