目录
前言
内联函数
为什么声明和定义分离
为什么声明和定义分离后不出错
为什么内联函数不支持声明和定义分离
为什么内联函数支持声明和定义不分离
坚持声明和定义不分离的解决方法
static修饰函数
inline修饰函数
结论
声明和定义不分离的应用场景
前言
在C语言中可能会遇到频繁调用100次函数的情况,这就意味这需要频繁的创建和销毁栈帧一百次,无疑这会增加程序运行时的开销,对此C语言使用了宏来解决这一问题。但是宏是一个很容易犯错的概念,其中主要有以下几个方面:
- 宏不是函数,宏函数不需要参数参数
#define ADD(a,b) ((a)+(b)) //right#define ADD(int a,int b) ((a)+(b)) //wrong- 宏定义的结尾不需要分号
#define ADD(a,b) ((a)+(b)) //right#define ADD(a,b) ((a)+(b));//wrong- 要用括号控制优先级(运算符的优先级问题)
#define ADD(a,b) ((a)+(b)) //right//不加括号导致出错:
ADD(x | y,x & y); ——> (x | y + x & y),原本想要计算x|y与x&y之和,但是由于+的优先级高所以就变成了计算x | (y + x) & y
此外,宏也存在一些缺点:
- 语法复杂,坑很多,不容易控制(上面说过了)
- 不能调试
- 没有类型检查
关于宏的具体内容请查看:C语言关于预处理命令的理解
内联函数
问题描述:由于宏在处理频繁调用函数的问题中可能会出现各种各样的问题,C++摒弃了宏而采用inline关键字来解决该问题
内联展开:当使用 inline 关键字修饰函数时,编译器会尝试在每个调用该函数的地方直接将函数的代码插入到调用位置,而不是像普通函数那样通过跳转到另一个内存地址执行完后再返回
展开详解:当编译器遇到一个被声明为 inline 的函数并进行调用时,在生成最终的可执行程序时,并不会像普通函数一样创建一个新的栈帧、跳转到对应代码段执行完后再返回。相反,编译器会尽可能地将整个被标记为 inline 的函数体复制粘贴至每次调用该 inline 函数处。
优点:有助于减少因频繁调用小型简单操作而产生的额外开销(如参数传递、栈帧创建等),从而提高程序运行效率
无inline关键字修饰函数:
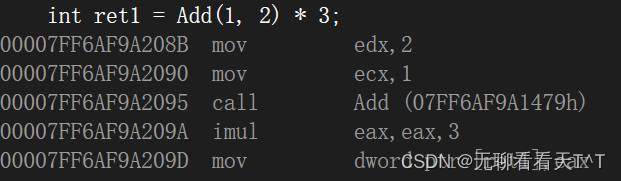
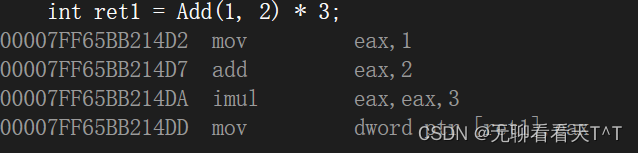
#include <iostream> using namespace std;int Add(int a, int b) {return a + b; }int main() {int ret1 = Add(1, 2) * 3;int x = 1, y = 2;int ret2 = Add(x | y, x & y);return 0; }
有inline关键字修饰函数:
#include <iostream> using namespace std;inline int Add(int a, int b) {return a + b; }int main() {int ret1 = Add(1, 2) * 3;int x = 1, y = 2;int ret2 = Add(x | y, x & y);return 0; }
1和2分别放入寄存器,接着将寄存器会将
eax中的值与 3 相乘,并将结果放回到eax寄存器
注意事项:
1、并非所有被声明为 inline 的函数都一定会被内联展开,在实际情况中编译器可能基于复杂性和其他因素做出选择性忽略某些内联请求:
- 在release模式下,可以直接查看编译器生成的汇编代码中是否存在call Add
- 在debug模式下,需要对编译器进行设置否则不会展开(debug模式下,编译器默认不会对代码进行优化)
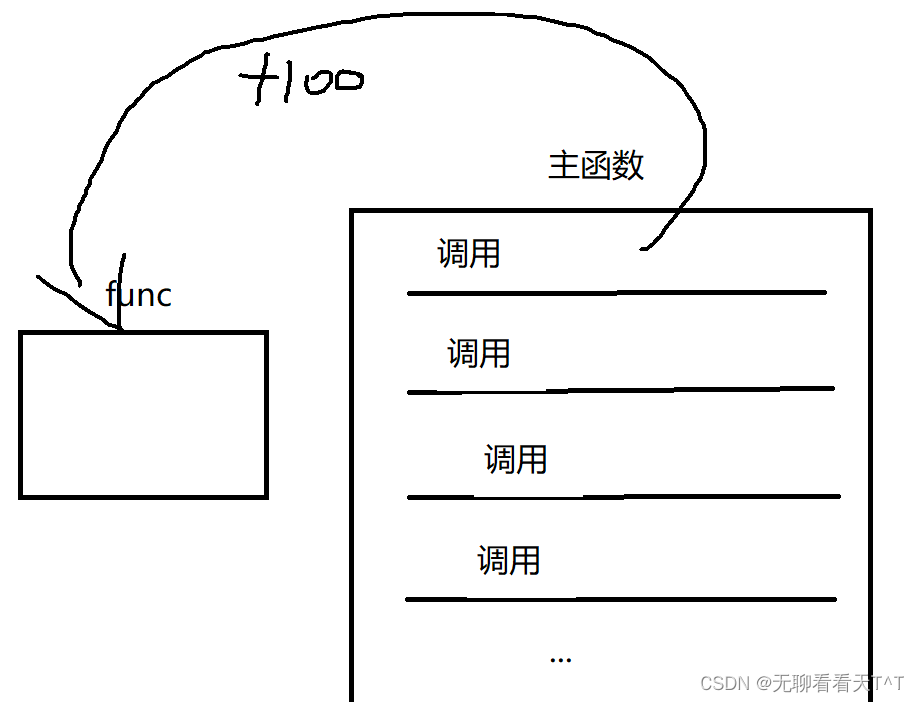
2、内联是一种以空间(编译好的可执行程序的大小)换时间的做法,如果所有函数都是内联函数,这可能会使目标文件变大

对于一个100行且需要调用1w次的func函数,如果采用内联的方法,可执行程序的代码增100*1w行,最终的可执行程序代码量剧增,代码的编译速度降低影响用户体验,如果不采用内联的办法,每次调用时都会跳转到该段代码运行,这就导致只有一份 func 函数代码存在于程序中,可执行程序实际上只会增加一百行的代码:
3、inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议是将函数规模较小(即函数不是很大)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性,《C++prime》第五版关于inline的建议如下:

为什么声明和定义分离
我们现在有一个Stack.h文件和Test.cpp文件和一个空的Stack.cpp文件,当我们直接在Stack.h中声明和定义一个函数,程序可以正常运行:
Stack.h文件
#pragma once
#include <iostream>
using namespace std;int Add(int a, int b)
{cout << "int Add(int a,int b)" << endl;return a + b;
}Test.cpp文件
#include "Stack.h"int main()
{Add(1, 2);return 0;
}但是当我们在空的Stack.cpp文件中也包含Stack.h文件,就会出现一个重定义的链接错误:
Stack.cpp文件
#include "Stack.h"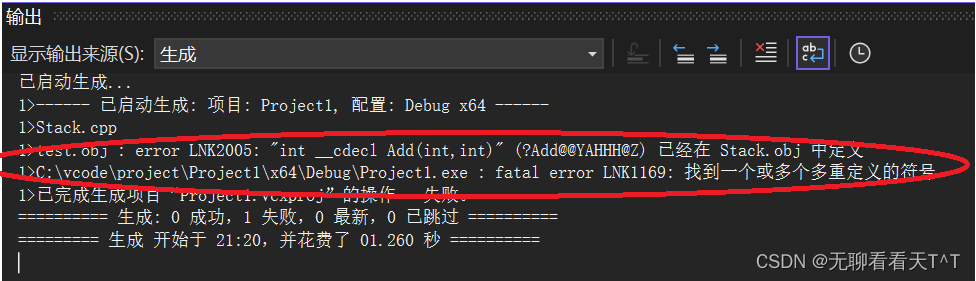
这是因为Stack.cpp和Test.cpp两个文件都包含了Add函数,且在编译的阶段检查时不满足函数重载的条件(两个文件中的Add函数的返回值类型、参数类型、顺序一致),当两个.cpp文件经过编译、链接和汇编形成的.o文件进行链接时,链接器就会检测出函数重定义的错误
#pragma once解决的问题是一个源文件同时包含多个一样的头文件
#include "Stack.h" #include "Stack.h" //wrongint main() {int i = 0;return 0; }
结论:如果将函数或变量的实现直接写在头文件中(声明和定义不分离),并且多个源文件包含了该头文件,在链接时就会出现多重定义错误
为什么声明和定义分离后不出错
采用函数声明与定义分离,即Stack.h文件中只有Add函数的声明,Stack.cpp文件中只有函数的定义,Test.cpp文件中只有调用函数,当程序进行编译时,.h文件会分别在两个.cpp文件中展开,Stack.cpp文件中既有函数的声明和定义,并且Add的函数名会被符号表统计,Test.cpp文件中只有函数的声明和调用,Test.cpp在链接前调用函数会生成类似call Add(?)的汇编指令(Test.cpp文件中没有函数的定义),所以链接器在链接阶段会去符号表依据函数名寻找该函数的地址,当找到该函数的地址后会将两个文件进行链接,此时汇编指令就变成了call Add(函数地址)

编译阶段:
- 头文件(Stack.h)被包含到两个源文件(Stack.cpp 和 Test.cpp)中
- Stack.cpp 中包含了 Add 函数的实现部分
- Test.cpp 中只包含了对 Add 函数的调用
链接阶段:
- 在编译过程中生成目标代码时,在 Test.cpp 文件里对 Add 函数进行调用时会生成类似
call Add(?)的汇编指令。因为此时并没有找到该函数具体实现所在地址,所以使用一个占位符“?”来表示需要填充该地址。符号解析和链接:
- 链接器会根据符号表查找具体实现位置,并将所有目标代码整合成可执行程序。
- 当链接器遇到
call Add(?)这样的指令时,在符号表找到相应函数名,并替换为正确地址后完成最终连接
为什么内联函数不支持声明和定义分离
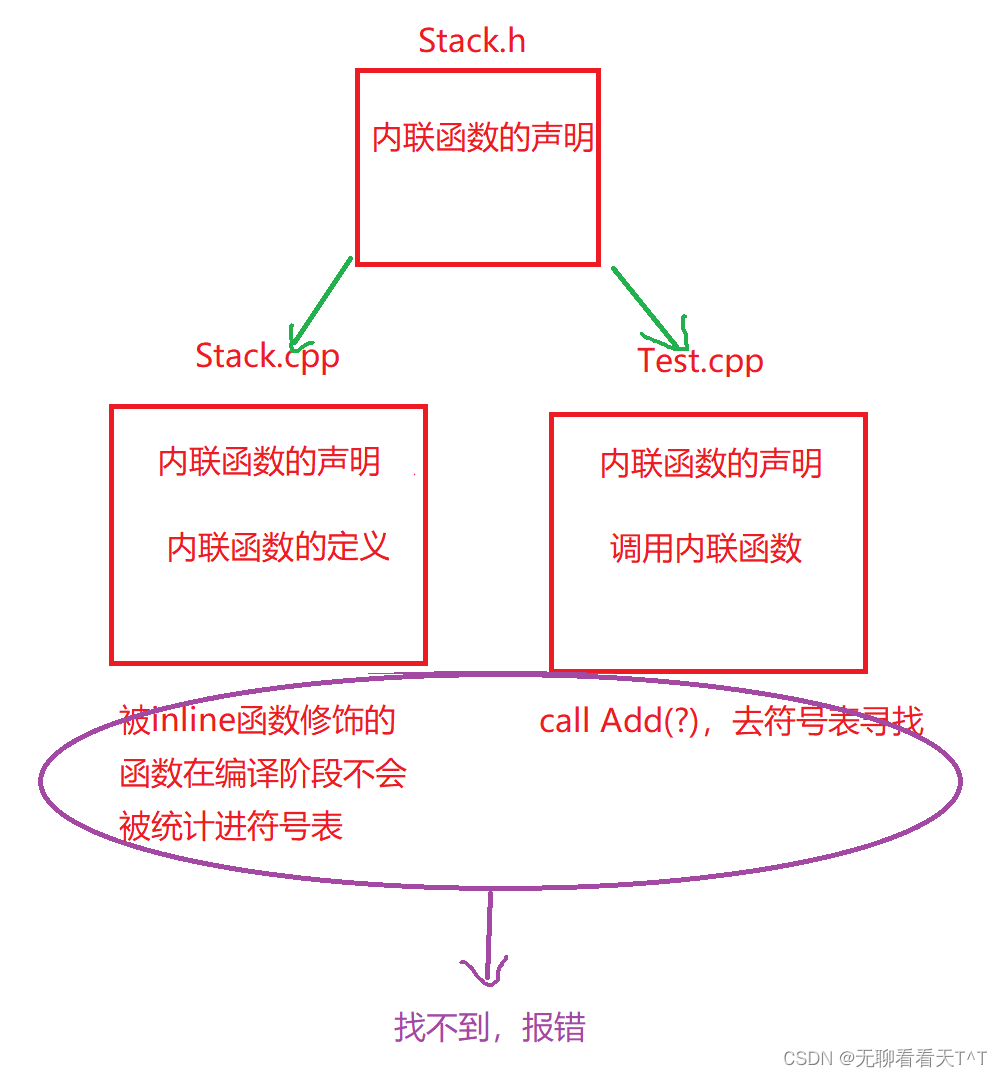
原因:被inline修饰的函数在编译阶段不会被统计进符号表中(前提是明确规定该函数可以展开)
函数声明和定义分离:
如果将inline修饰的函数放入Stack.cpp文件中且包含.h文件,Stack.h文件中只有函数的声明,Test.cpp文件中只有函数的调用且包含.h文件,在编译后会出现如下情况:
为什么内联函数支持声明和定义不分离
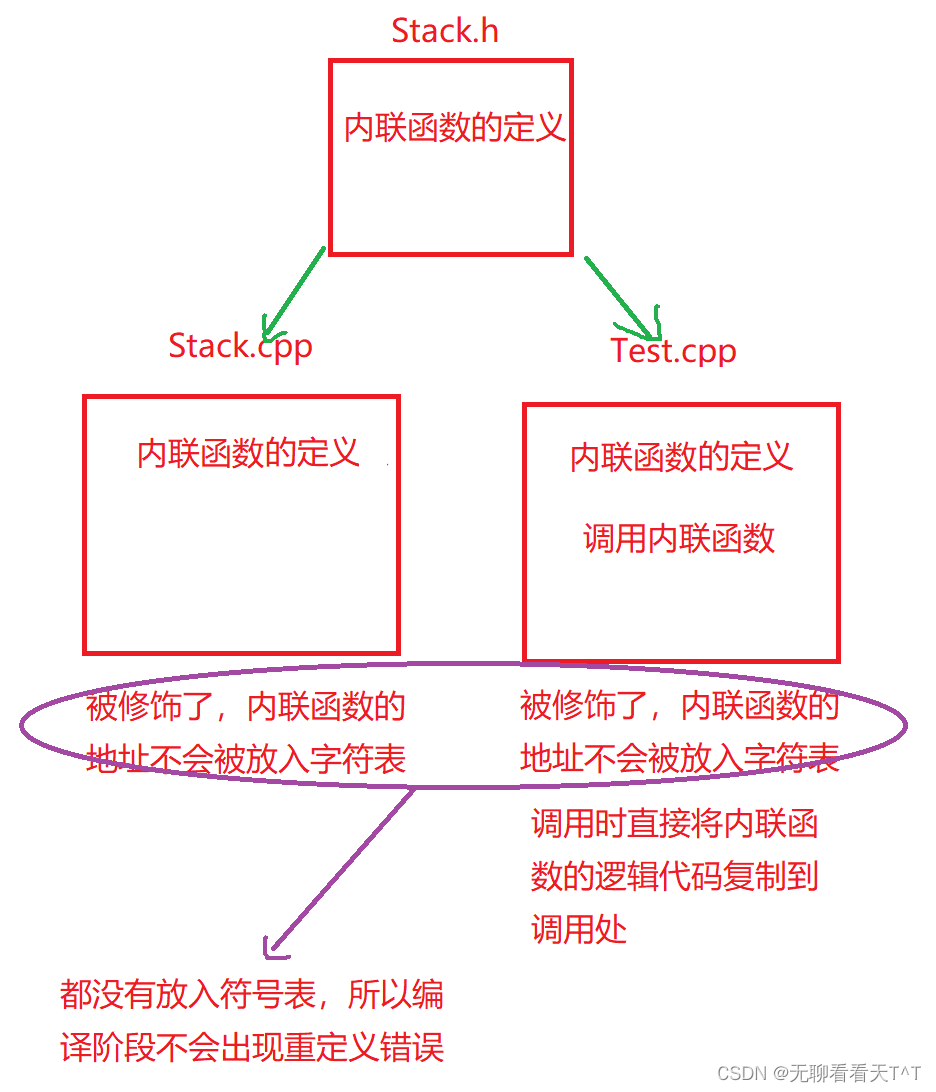
原因:被inline修饰的函数在编译阶段不会被统计进符号表中(前提是明确规定该函数可以展开)
函数声明和定义未分离:
如果将inline修饰的函数放入Stack.h文件中,Stack.cpp文件只有包含.h文件的#include "Stack.h"一行代码,Test.cpp文件中有函数的调用且包含.h文件,在编译后会出现如下情况:
坚持声明和定义不分离的解决方法
static修饰函数
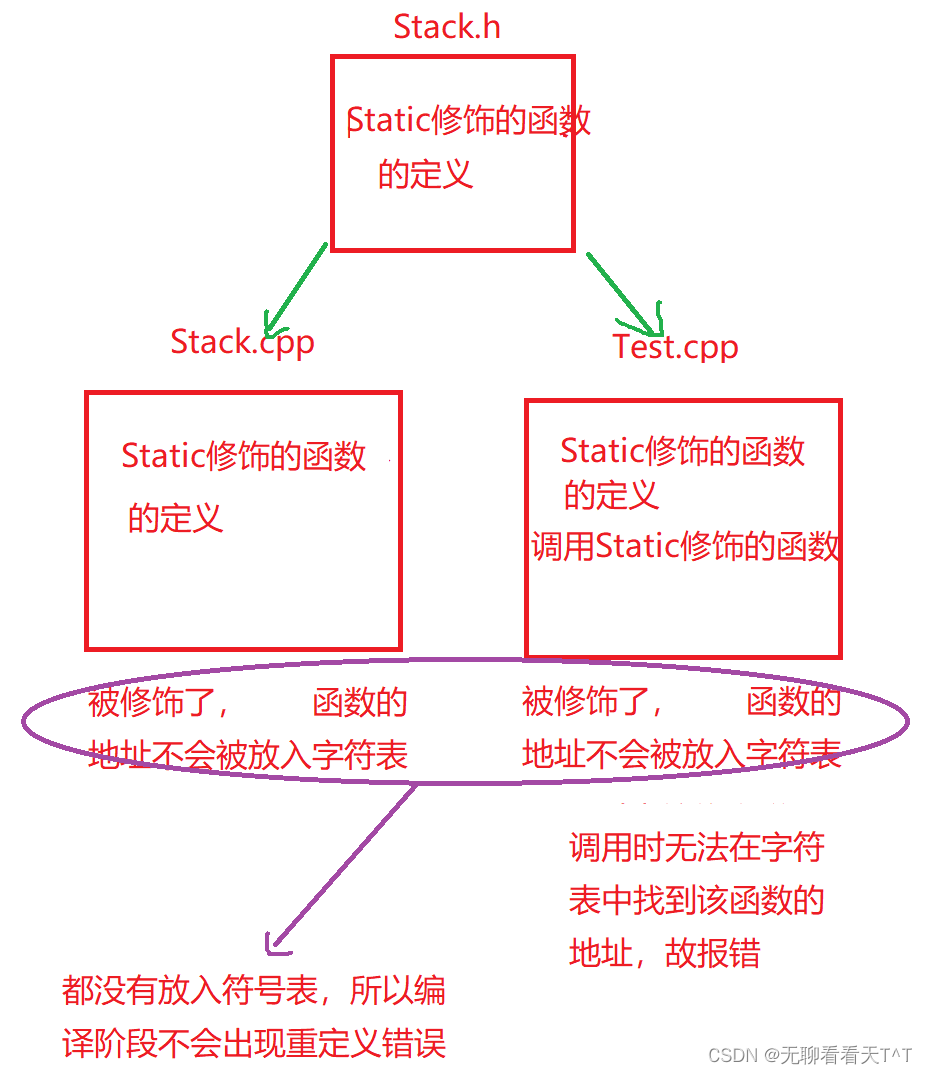
基本概念:使用static修饰的函数,则该函数只能被当前文件访问,无法被其他文件调用
底层原理:编译阶段被static修饰的函数不会被统计进符号表中(其它的用不到)
#pragma once
#include <iostream>
using namespace std;static int Add(int a, int b)
{cout << "int Add(int a,int b)" << endl;return a + b;
}当Stack.cpp文件只有#include ”Stack.h“,Test.cpp文件有函数调用和#include ”Stack.h“时,在编译后会产生如下情况:
inline修饰函数
不做解释
结论
- 要么在写文件的时候直接选择函数声明和定义分离的方式
- 如果实在想要用函数声明和定义不分离,那么大函数用static修饰,小函数用inline修饰
必须声明和定义不分离的应用场景
有时候声明和定义必须不分离的情况可能包括以下几点:
模板函数或类:对于模板函数或类,通常需要将其声明和定义放在同一个文件中。因为编译器需要在实例化时能够看到完整的函数或类定义,以便生成相应的代码
inline函数:为处理频繁调用小型函数而导致的开销问题,而采用inline修饰函数时静态成员变量:对于某些静态成员变量,在 C++ 中如果希望确保只有一个实例存在,则通常会将其声明和定义结合起来,并且还可能需要特殊处理以确保正确初始化
特定平台下链接问题:一些特定平台或库要求某些符号必须在同一源文件中进行声明和定义,并且不能被其他模块引用。这种情况下也需要将声明与实现结合起来
~over~