1. 引言
随着互联网应用的发展和规模的不断扩大,分布式系统中的缓存成为了提升性能和扩展性的重要手段之一。本文将介绍几种在分布式系统中常用的缓存方案,包括分布式内存缓存、分布式键值存储、分布式对象存储和缓存网关等。
1.1 缓存在分布式系统中的重要性
在分布式系统中,缓存起着至关重要的作用。随着互联网应用的不断发展和用户数量的增加,分布式系统面临着诸多挑战,包括高并发访问、大数据量处理和系统性能优化等。缓存作为一种提高系统性能和可伸缩性的重要手段,在分布式系统中发挥着重要作用,具有以下几个方面的重要性:
-
提高访问速度: 在分布式系统中,数据存储往往分布在不同的节点和数据中心中,网络延迟和数据传输时间成为影响系统性能的关键因素。通过将数据缓存到靠近用户的位置,可以大大减少数据传输时间,提高用户访问速度。
-
降低数据库负载: 分布式系统中的数据库往往面临着高并发读写请求,而数据库的读写操作是相对较慢的,容易成为系统的瓶颈。通过将热点数据或频繁访问的数据缓存到内存中,可以减少对数据库的读写请求,降低数据库负载,提高系统的并发处理能力。
-
提高系统可用性: 缓存可以将数据复制到多个节点中,实现数据的备份和冗余存储,当某个节点发生故障或网络故障时,可以自动切换到其他节点,提高系统的可用性和容错性。
-
减少外部依赖: 分布式系统中往往依赖于外部服务或第三方接口,如支付服务、地图服务等。通过缓存外部接口返回的数据,可以减少对外部服务的依赖,提高系统的稳定性和可靠性。
1.2 缓存方案的选择对系统性能的影响
在设计分布式系统时,选择合适的缓存方案对系统的性能和可伸缩性有着重要的影响。不同的缓存方案具有不同的特点和适用场景,正确选择缓存方案可以有效提高系统的性能,并且降低系统的复杂度和维护成本。
1.2.1 性能影响
-
读写速度: 不同的缓存方案对读写速度有着不同的影响。本地缓存通常具有较快的读写速度,适用于频繁读取的数据;而分布式缓存虽然具有分布式的优势,但通常会牺牲一定的读写速度来实现数据的分布式存储和高可用性。
-
数据一致性: 在选择缓存方案时,需要考虑数据一致性的问题。本地缓存通常不具备数据一致性保证,而分布式缓存可以通过一致性哈希算法等方式来保证数据一致性,但可能会牺牲一定的性能。
1.2.2 可伸缩性影响
-
水平扩展: 不同的缓存方案对系统的水平扩展能力有着不同的影响。分布式缓存通常具有较好的水平扩展能力,可以通过增加节点来扩展系统的处理能力;而本地缓存通常不具备水平扩展能力,需要在单节点上处理所有的请求。
-
节点故障容错: 在分布式环境中,节点故障是常态,选择合适的缓存方案可以降低节点故障对系统的影响。分布式缓存通常具有较好的节点故障容错能力,可以通过复制数据和备份节点来提高系统的可用性。
1.2.3 维护成本影响
- 部署和管理: 不同的缓存方案对系统的部署和管理成本有着不同的影响。本地缓存通常具有较低的部署和管理成本,适用于小规模系统;而分布式缓存通常需要较多的节点和复杂的部署和管理工作,适用于大规模系统。
2. 缓存方案概述
在设计分布式系统时,选择合适的缓存方案对系统的性能和可伸缩性至关重要。以下是常见的几种缓存方案的概述:
常用的缓存架构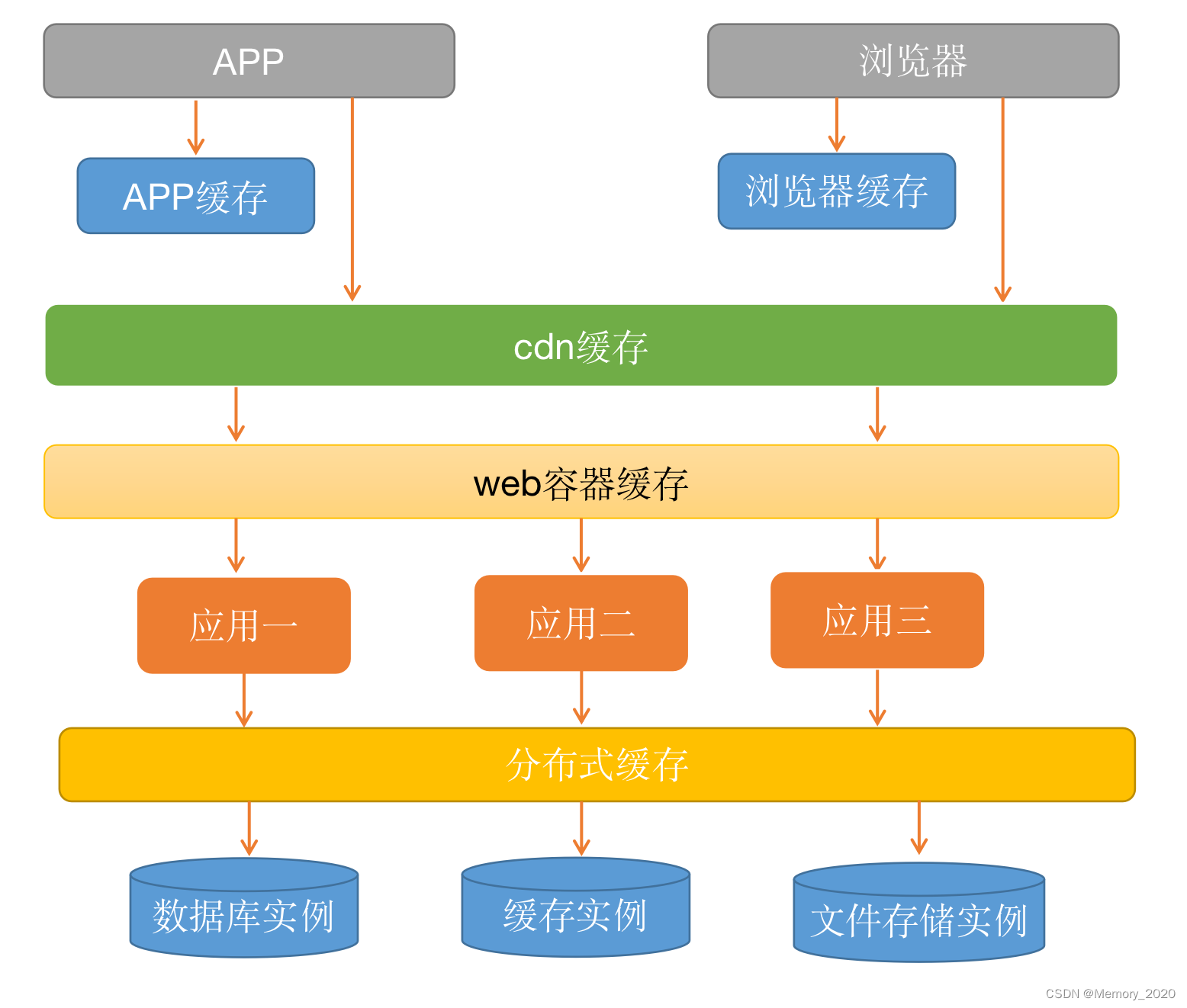
2.1 本地缓存
本地缓存是指将数据缓存在应用程序的本地内存中,以减少对后端数据存储系统的访问。本地缓存通常具有快速读取和写入的特点,适用于频繁访问的数据和对数据一致性要求不高的场景。常见的本地缓存包括内存缓存(如Caffeine、Guava Cache)和文件缓存(如Ehcache)等。
2.2 分布式缓存
分布式缓存是指将数据缓存在分布式环境中的多个节点上,以提高数据访问的速度和可伸缩性。分布式缓存通常具有数据分片、负载均衡和高可用性的特点,适用于大规模分布式系统和高并发访问的场景。常见的分布式缓存包括Redis、Memcached、Hazelcast和Apache Ignite等。
2.3 内存数据库
内存数据库是指将数据存储在内存中,以提高数据访问的速度和响应性能。内存数据库通常具有快速的读写能力、高并发访问和数据持久化的特点,适用于对数据一致性要求较高的场景。常见的内存数据库包括Apache Geode、Aerospike和VoltDB等。
2.4 缓存网关
缓存网关是指将缓存部署在反向代理服务器或负载均衡器上,以提高静态资源的访问速度和可用性。缓存网关通常具有缓存内容的动态更新、请求缓存和缓存失效策略等特点,适用于静态资源访问频繁的场景。常见的缓存网关包括Varnish、Squid和NGINX等。
本地缓存是将数据缓存在应用程序的本地内存中,以减少对后端数据存储系统的访问。在分布式系统中,本地缓存通常位于每个应用程序实例的内存中,可以提高数据访问速度和减轻后端存储系统的负载。
3.1 特点与优势
- 快速读写: 本地缓存直接存储在应用程序的内存中,读写速度快,响应时间低。
- 降低后端负载: 本地缓存可以减少对后端数据存储系统的访问,降低后端系统的负载压力。
- 易于实现和管理: 本地缓存通常易于实现和管理,无需额外的部署和配置。
- 适用于小规模系统: 对于小规模系统或者对数据一致性要求不高的场景,本地缓存是一种简单有效的解决方案。
3.2 适用场景
本地缓存适用于以下场景:
- 频繁读取的数据: 对于频繁读取的数据,可以将其缓存到本地内存中,提高数据访问速度。
- 临时数据: 对于临时性的数据,如用户登录信息、临时计算结果等,可以缓存在本地内存中,减少对后端存储系统的访问。
- 数据一致性要求不高的场景: 对于对数据一致性要求不高的场景,如页面静态数据、临时计算结果等,可以使用本地缓存。
3.3 使用示例与实践
在一个电子商务系统中,需要缓存商品信息,并且希望能够在缓存中设置过期时间,以保证缓存数据的及时性和一致性。以下是一个使用本地缓存(Guava Cache)的示例:
import com.google.common.cache.Cache;
import com.google.common.cache.CacheBuilder;import java.util.concurrent.TimeUnit;public class ProductCacheExample {// 创建本地缓存实例private static Cache<Long, Product> productCache = CacheBuilder.newBuilder().maximumSize(1000) // 设置最大缓存数量.expireAfterWrite(30, TimeUnit.MINUTES) // 设置缓存过期时间.build();// 模拟从数据库或其他数据源中加载商品信息private static Product loadProductFromDatabase(long productId) {// 这里假设从数据库中加载商品信息// 实际应用中可以根据业务需求进行具体实现return new Product(productId, "Product " + productId, 100.0);}// 根据商品ID获取商品信息(先从缓存中获取,如果缓存中不存在则从数据库中加载)public static Product getProductById(long productId) {try {// 尝试从缓存中获取商品信息Product product = productCache.get(productId, () -> loadProductFromDatabase(productId));return product;} catch (Exception e) {e.printStackTrace();// 缓存中不存在商品信息,从数据库中加载return loadProductFromDatabase(productId);}}public static void main(String[] args) {// 模拟获取商品信息long productId = 12345L;Product product = getProductById(productId);System.out.println("Product Name: " + product.getName());}// 商品实体类static class Product {private long id;private String name;private double price;public Product(long id, String name, double price) {this.id = id;this.name = name;this.price = price;}public long getId() {return id;}public String getName() {return name;}public double getPrice() {return price;}}
}
实践建议:
- 根据业务需求和数据特性选择合适的本地缓存库,如Caffeine、Guava Cache等。
- 设定合适的缓存大小、过期策略和缓存淘汰策略,以平衡内存使用和缓存命中率。
- 对于频繁更新的数据,考虑使用缓存更新策略,如定时刷新缓存、异步更新缓存等,以保持缓存数据的及时性和一致性。
- 监控和调优本地缓存的使用情况,及时发现并解决缓存使用过程中的性能问题和内存泄漏问题。
在分布式系统中,缓存是一种重要的数据存储和访问方式,用于提高系统性能和可扩展性。本节将介绍分布式缓存的特点与优势,常见的分布式缓存方案,以及一些使用示例与实践。
4.1 特点与优势
分布式缓存具有以下特点与优势:
- 高性能: 缓存数据存储在内存中,读写速度快,能够有效降低数据访问的延迟。
- 可扩展性: 分布式缓存可以水平扩展,通过添加更多的节点来增加存储容量和吞吐量。
- 高可用性: 分布式缓存通常具有复制和故障转移机制,能够保证数据的可靠性和服务的可用性。
- 降低数据库负载: 缓存可以减轻数据库的负载,提高数据库的性能和吞吐量。
- 缓解流量峰值: 缓存可以缓解系统的流量峰值,减少对后端服务的压力。
4.2 常见的分布式缓存方案
常见的分布式缓存方案包括:
-
Redis: Redis 是一个开源的内存数据结构存储,支持多种数据结构(如字符串、列表、哈希表等),并提供持久化功能。Redis 通过主从复制和分片技术实现数据的分布式存储和高可用性。
-
Memcached: Memcached 是一个高性能的分布式内存对象缓存系统,主要用于缓存数据和减轻数据库负载。Memcached 基于内存存储,支持键值对的存储,并提供简单的 API 接口。
-
Hazelcast: Hazelcast 是一个开源的分布式内存数据网格,提供了分布式数据结构和集群管理功能,可以用于缓存、数据存储和分布式计算。
-
Apache Ignite: Apache Ignite 是一个内存中数据网格平台,提供了分布式缓存、分布式计算和分布式存储等功能,支持 SQL 查询和事务处理。
4.3 使用示例与实践
Redis 实现分布式缓存的示例:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class RedisCacheExample {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;public static void main(String[] args) {// 创建 Redis 连接池配置JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(100); // 最大连接数poolConfig.setMaxIdle(50); // 最大空闲连接数poolConfig.setMinIdle(10); // 最小空闲连接数// 创建 Redis 连接池try (JedisPool jedisPool = new JedisPool(poolConfig, REDIS_HOST, REDIS_PORT)) {// 从连接池获取 Jedis 实例try (Jedis jedis = jedisPool.getResource()) {// 设置缓存数据jedis.set("key", "value");// 获取缓存数据String value = jedis.get("key");System.out.println("缓存数据:" + value);}}}
}
5. 缓存网关
缓存网关是位于客户端和后端数据源之间的缓存层,用于加速数据访问和减轻后端负载。本节将介绍缓存网关的特点与优势,常见的缓存网关方案,以及使用示例与实践。
5.1 特点与优势
缓存网关通常具有以下特点与优势:
- 提高性能与加速访问: 缓存网关可以缓存静态内容和动态内容的副本,提高数据访问的速度,加速网站的响应时间。
- 减轻后端负载: 缓存网关可以将请求拦截并直接返回缓存中的数据,从而减轻后端服务器的负载,提高系统的性能和可扩展性。
- 提高系统可用性: 缓存网关具有缓存失效、数据更新等功能,能够保证数据的一致性和系统的可用性。
- 灵活的配置选项: 缓存网关通常提供了灵活的配置选项,可以根据业务需求进行缓存策略、缓存时间等参数的调整。
5.2 常见的缓存网关方案
常见的缓存网关方案包括:
-
Varnish: Varnish 是一个高性能的 HTTP 缓存代理,主要用于加速 Web 服务的访问速度。它通过缓存静态内容和动态内容的副本来减轻后端服务器的负载,提高网站的性能和可扩展性。
-
NGINX: NGINX 是一个轻量级的 Web 服务器和反向代理服务器,常用于负载均衡和缓存加速。它提供了灵活的配置选项和高性能的缓存功能,可以缓存静态内容和动态内容的副本,提高数据访问的速度。
5.3 使用示例与实践
使用 NGINX 缓存网关的示例配置:
# 定义一个名为 cache 的缓存路径和配置
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=cache:10m max_size=10g inactive=60m;# 定义一个名为 backend 的后端服务器
upstream backend {server localhost:8080;
}# 定义一个名为 cache_proxy 的服务器
server {listen 80;server_name example.com;# 配置缓存规则location / {proxy_pass http://backend;proxy_cache cache;proxy_cache_valid 200 304 10m;proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504;proxy_cache_bypass $http_cache_control;add_header X-Cache $upstream_cache_status;}
}
6. 总结
缓存方案在提升系统性能、减轻后端负载以及改善用户体验方面发挥着重要作用。不同的缓存方案具有各自的优点和缺点,需要根据具体的业务需求和场景来选择合适的方案。
内存数据库提供了高性能的数据存储和丰富的数据结构支持,适用于对读写速度要求高的场景;
分布式缓存具有良好的可扩展性和高可用性,适用于大规模数据存储和高并发访问的场景;
缓存网关能够减轻后端负载、提高数据访问速度,适用于缓存静态内容和动态内容的副本,但在动态数据更新频繁的场景效果有限。
下面是缓存方案对比
| 缓存方案 | 优点 | 缺点 |
|---|---|---|
| 内存数据库 | - 高性能:数据存储在内存中,读写速度快。 - 丰富的数据结构支持:支持多种数据结构,如字符串、列表、哈希表等。 - 持久化功能:支持数据的持久化到磁盘,确保数据不丢失。 | - 成本较高:存储成本较高,需要足够的内存资源。 - 容量限制:受限于单机内存容量,无法存储大规模数据。 - 需要备份和恢复机制:一旦服务器宕机,数据可能会丢失,需要定期备份和恢复。 |
| 分布式缓存 | - 可扩展性:可以水平扩展,通过添加更多的节点来增加存储容量和吞吐量。 - 高可用性:通过主从复制和分片技术实现数据的分布式存储和高可用性。 - 低延迟:部署在集群中,能够实现低延迟的数据访问。 | - 配置和管理复杂:需要考虑分片、复制、负载均衡等问题,部署和维护成本较高。 - 数据一致性:分布式环境下,数据一致性可能会受到影响,需要考虑数据同步和一致性问题。 |
| 缓存网关 | - 减轻后端负载:将请求拦截并直接返回缓存中的数据,减轻后端服务器的负载。 - 提高性能:缓存静态内容和动态内容的副本,提高数据访问的速度。 - 灵活配置:根据业务需求进行灵活的缓存策略配置。 | - 不适用于动态数据:适用于缓存静态内容和动态内容的副本,对于动态数据更新频繁的场景效果有限。 - 配置复杂:需要根据具体的业务需求进行灵活的缓存策略配置,配置复杂度较高。 |
更多文章
架构设计:生产消费模型-CSDN博客
RabbitMQ入门实战-CSDN博客
presto/trino 入门介绍实战_presto和trino怎么选-CSDN博客
MongoDB入门介绍与实战-CSDN博客
Netty入门与实战教程_netty教程-CSDN博客
Nacos入门介绍与使用_怎么找到nacos的控制台-CSDN博客
ElasticSearch入门介绍和实战-CSDN博客
JMM内存屏障和逃逸分析详解-CSDN博客
分布式任务调度:XXL-Job入门介绍实战-CSDN博客