目录
什么是BaseDao?
为什么需要BaseDao?
BaseDao的实现逻辑
什么是BaseDao?
Basedao 是一种基于数据访问对象(Data Access Object)模式的设计方法。它是一个用于处理数据库操作的基础类,负责封装数据库访问的底层操作,提供通用的数据库访问方法。
Basedao 主要用于简化数据库操作的代码开发,并提供一致性和可维护性。它通常包含有对数据库的增加、删除、修改和查询等操作方法,以及一些基本的事务处理功能。
Basedao 可以通过继承来扩展具体的数据库操作方法,使得在具体的业务实现中可以更加专注于业务逻辑的实现,而不需要关注底层数据库的细节。
通过使用 Basedao,开发人员可以更加高效地进行数据库操作的开发,减少了重复的代码编写,提高了代码的可维护性和可读性。
为什么需要BaseDao?
BaseDao 的优点包括:
- 代码复用(共性抽取):BaseDao 封装了常见的数据库操作方法,可以被不同的业务逻辑类多次调用,避免了重复编写相同的数据库操作代码,提高了代码的复用性。
- 提高开发效率:BaseDao 提供了高级的数据库操作方法,开发人员可以直接调用这些方法,减少了重复的开发工作,提高了开发效率。
- 降低代码耦合度:BaseDao 封装了底层数据库的细节,通过调用 BaseDao 的方法,业务逻辑类可以和具体的数据库实现解耦,减少了业务逻辑类和数据库之间的直接依赖,提高了代码的可维护性和可扩展性。
- 提供事务支持:BaseDao 通常会提供事务处理的功能,可以保证数据库操作的一致性。开发人员可以通过 BaseDao 来处理事务,确保在一次操作中,要么全部成功,要么全部失败,避免了数据不一致的情况。
总的来说,BaseDao 通过封装数据库操作,提供高级的数据库操作方法,降低代码耦合度,提供事务支持等优点,可以提高开发效率,简化数据库操作,提高代码的可维护性和可扩展性。
BaseDao的实现逻辑
简单来说BaseDao就是对数据库底层操作业务进行共性抽取,下面就以学生信息为例~
1、在学生信息管理系统中,不论增删改查还是特殊业务都离不开每次访问数据库的配置驱动以及获取连接和关闭连接,所以这两步是必然封装的
/*** 获取数据库连接对象*/
public Connection getConnection() throws Exception { //获取连接对象方法//加载配置文件Properties properties = new Properties();properties.load(Files.newInputStream(Paths.get("D:\\druid.properties")));//创建一个指定参数的数据库连接池DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);return dataSource.getConnection(); //返回连接对象
}因为当时博主访问数据库是采用Druid连接池,所以配置驱动就使用配置文件的方式,配置文件( .properties )代码如下:
driverClassName = com.mysql.cj.jdbc.Driver
url = jdbc:mysql://localhost:3306/student?useServerPrepStmts=true
username = root
password = root
initialSize = 10
maxActive = 30
maxWait = 1000关闭连接方法封装代码如下:
/*** 关闭数据库连接* @param conn 数据库连接* @param stmt PreparedStatement预处理对象* @param rs 结果集*/
public void closeAll(Connection conn, PreparedStatement stmt, ResultSet rs) { //关闭连接方法// 若结果集对象(RresuleSet)不为空,则关闭if (rs != null) {try {rs.close();} catch (Exception e) {e.printStackTrace();}}// 若预处理对象(PreparedStatement)不为空,则关闭if (stmt != null) {try {stmt.close();} catch (Exception e) {e.printStackTrace();}}// 若数据库连接对象(Connection)不为空,则关闭if (conn != null) {try {conn.close();} catch (Exception e) {e.printStackTrace();}}}2、通过第一步的调用能够返回一个连接对象,那么接下来就可以进行基本的增删改查操作, 增删改都属于对数据做更新,所以先做增删改
/*** 增、删、改的操作* @param preparedSql 预编译的 SQL 语句* @param param 参数的字符串数组* @return 影响的行数*/
public int updateRow (String preparedSql, Object[] param) throws Exception { //增删改操作的方法PreparedStatement preparedStatement = null; //创建预处理对象并初始为空(通过预处理可以防止SQL恶意注入)int row = 0; //初始受影响行数(当受影响行数大于0时,说明执行成功数据则更新)Connection connection = getConnection(); //调用getConnection()方法获取数据库连接try {preparedStatement = connection.prepareStatement(preparedSql); //对sql形参预处理if (param != null) { //形参数组(注入参数)不为空时,循环遍历对预处理sql注入参数for (int i = 0; i < param.length; i++) {//为预编译sql设置参数preparedStatement.setObject(i + 1, param[i]);}}row = preparedStatement.executeUpdate(); //执行sql语句并得到受影响的行数closeAll(connection,preparedStatement,null); //调用closeAll()方法关闭资源,因为执行操作不含查询,则将结果集的实参传空} catch (SQLException e) {e.printStackTrace();}return row; //返回受影响行数
}因为sql语句中需要的参数与类型是不确定的,则用Object类型数组作为容器
3、至此就剩查询操作了,在封装前需要创建一个实体类,以至于后续每个实体类都可以代表为一行数据,代码如下:
public class Student {//初始字段private int id;private String name;private int age;public Student(int id, String name, int age) { //构造函数this.id = id;this.name = name;this.age = age;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() { //toString方法return "Student{" +"id=" + id +", name='" + name + '\'' +", age=" + age +'}';}
}实体对象有了,那么走你:
public List<Student> queryData (String sql, Object[] param) throws Exception { //查询操作的方法PreparedStatement preparedStatement = null; //创建预处理对象并初始为空(通过预处理可以防止SQL恶意注入)Connection connection = getConnection(); //调用getConnection()方法获取数据库连接preparedStatement = connection.prepareStatement(sql); //调用getConnection()方法获取数据库连接if (param != null) { //形参数组(注入参数)不为空时,循环遍历对预处理sql注入参数for (int i = 0; i < param.length; i++) {//为预编译sql设置参数preparedStatement.setObject(i + 1, param[i]);}}ResultSet resultSet = preparedStatement.executeQuery(); //得到返回的结果集List<Student> list = new ArrayList<Student>(); //创建List接口对象,泛型为指定Student对象类型,代表每个实体对象都是一行数据while (resultSet.next()) { //循环遍历结果集,将每行数据封装成Student对象,并添加到List集合中Student student= new Student(resultSet.getInt(1), resultSet.getString(2), resultSet.getInt(3)); //获取结果集中的数据存入Student对象中list.add(student); //将Student对象存入list接口中}closeAll(connection,preparedStatement,resultSet); //调用closeAll()方法关闭数据库连接return list; //返回List集合对象
}接下来创建一个测试类进行检查:
1、增删改测试
//增删改测试
BaseDao baseDao = new BaseDao(); //创建BaseDao对象
String sql = "insert into student(id,name,age) values(?,?,?)"; //定义预处理sql
Object[] list = {6, "老八", 35}; //将sql需要的参数存入至Object类型的数组
int add = baseDao.updateRow(sql, list); //调用增删改的方法并接收返回的受影响行数
if (add > 0) { //受影响行数大于0则说明数据更新成功System.out.println("新增成功!受影响行数:" + add);
}
/* 删除、修改也是一样 */控制台:

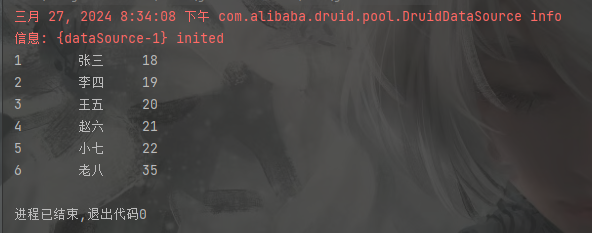
2、查询测试
//查询测试
BaseDao baseDao = new BaseDao(); //创建BaseDao对象
String sql = "select * from student"; //定义预处理sql
List<Student> list = baseDao.queryData(sql, null); //创建List接口,泛型为Student对象类型,用于存储查询返回的数据
for (Student student : list) {System.out.println(student.getId() + "\t\t" + student.getName() + "\t\t" + student.getAge()); //输出数据
}控制台:
这么一来,JavaWeb中的每次增删改查都可以简明的实现,增删改查以外的特殊性业务功能可在BaseDao对象中具体实现方法