前言:
在数据库查询优化领域,索引一直被视为关键的工具,用于提高查询性能并加速数据检索过程。然而,随着数据库技术的不断发展,出现了一些新的优化技术,其中包括索引下推(Index Pushdown)和索引覆盖(Index Covering)。这两种技术在提高查询性能和降低系统负载方面发挥了重要作用,并且已经成为了现代数据库系统中不可或缺的一部分。

目录
前言:
索引分类:
二者优缺点:
索引覆盖:
索引下推:
总结:
在介绍索引下推和索引覆盖前,我们要先从MySQL的索引讲起:
索引分类:
在数据库中,索引(Index)是一种数据结构,用于快速定位表中数据记录的位置,从而加速查询操作。索引可以理解为表的副本,其中包含了被索引列(或多列)的值以及对应的物理位置。索引使得数据库系统能够以更快的速度执行查询、排序和聚合等操作。
我们现在假设有一张表,这张表是基于B+树的形式来组织索引数据结构的,而且索引的类型为主键索引(聚簇索引):
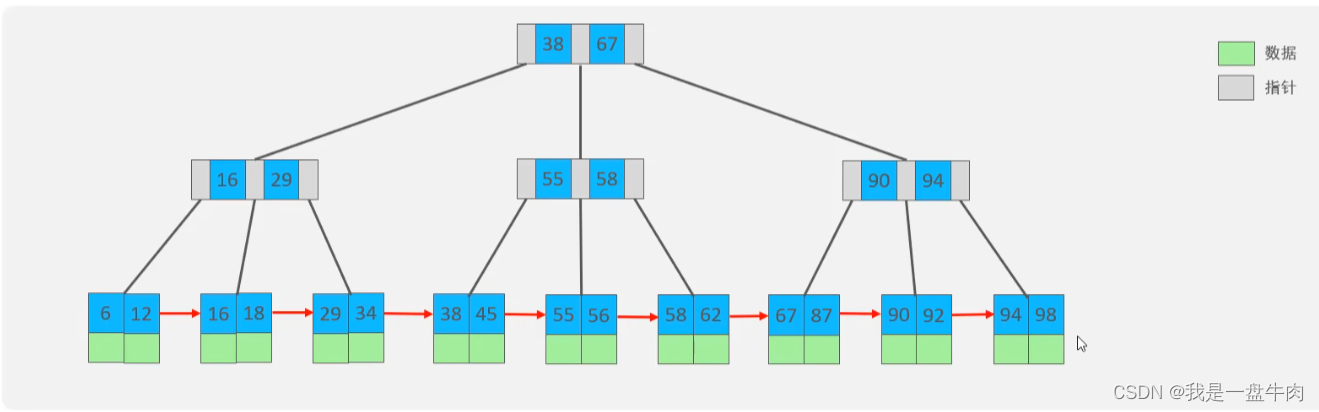
那么这张表的数据结构大概就如图所示,它的叶子结点存储的是索引和数据,也就是说:我们只要查到了这条数据对应的索引,就得到了这条数据。我们把这种索引类型叫做聚簇索引。
而还有另外一种情况:索引的类型是非主键(非聚簇索引)
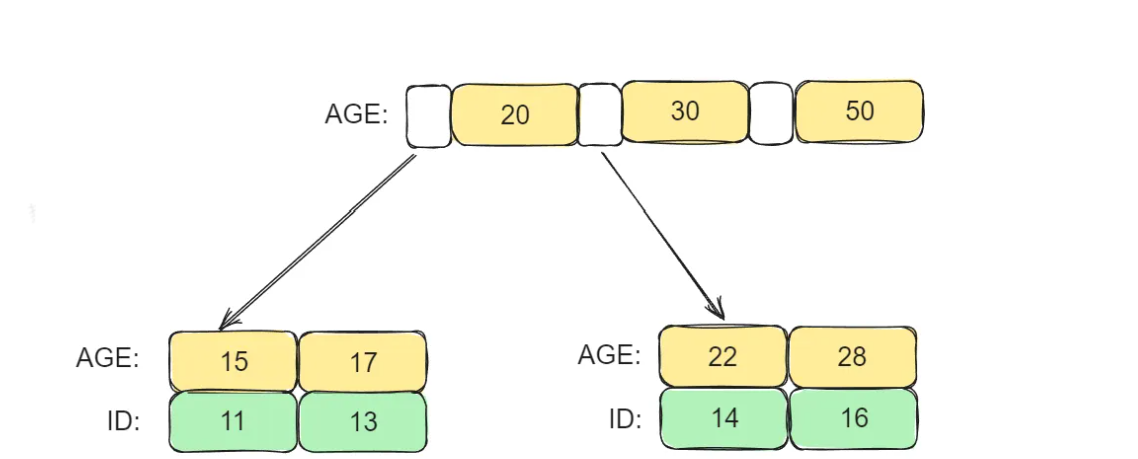
在这种情况下, 叶子节点存储的是索引值和主键,也就是说:我们没有办法像聚簇索引一样,只查询一次就得到目标数据。我们把这种索引类型叫做非聚簇索引。在非聚簇索引中,我们要进行二次查询,在我们这个例子中,还需要根据主键的值进行真正的数据查询。
二者优缺点:
聚簇索引(Clustered Index)的优点:
- 数据存储紧凑:聚簇索引中数据的物理顺序与索引的逻辑顺序相同,使得相关数据存储在一起,减少了磁盘IO操作次数,提高查询性能。
- 范围查询性能好:由于数据在物理上相邻存储,范围查询的效率较高。
- 主键查询快速:对于主键的查询速度很快,因为索引本身就是按照主键顺序组织的。
聚簇索引的缺点:
- 更新操作慢:插入、删除、更新记录时,需要调整数据在磁盘上的物理顺序,可能导致性能下降。
- 空间利用不灵活:插入数据时,可能会导致数据页分裂,造成空间的浪费。
非聚簇索引(Non-Clustered Index)的优点:
- 更新操作快:插入、删除、更新记录时,不会涉及数据在磁盘上的物理顺序调整,因此更新速度较快。
- 空间利用较灵活:不会因为数据的插入而导致数据页的分裂,节约空间。
非聚簇索引的缺点:
- 数据存储分散:索引和数据存储在不同的地方,查询时可能需要多次IO操作,影响查询性能。
- 范围查询效率低:由于数据存储分散,范围查询时需要多次IO操作,效率相对较低。
- 主键查询速度慢:对主键的查询速度可能不如聚簇索引快速。
而我们把没有办法通过一次SQL查询就得到目标结果,还需要进行二次查询的过程叫做回表。而为了优化回表这种情况,尽可能减少回表的发生,我们发明了索引覆盖和索引下推。
索引覆盖:
索引覆盖(Index Covering)是指一个查询可以完全通过索引来执行,而无需访问实际的数据行。在数据库中,通常查询语句包含了一系列的条件,这些条件用于筛选出符合特定条件的数据行。如果这些条件能够通过索引直接定位到符合条件的数据行,而无需访问实际的数据页,那么就称为索引覆盖。
比如我们有这样一条SQL语句:
select name,age,level
frmo user
where name = "AAA" and age 17那么我们就可以把目标查询内容设置成为索引
key `idx_nal` (`name`,`age`,`level`) using btree那么这样的话,我们在搜索的时候,只需要通过索引就能够拿到我们需要的全部数据了。这样就避免了回表。
索引覆盖注意事项:
1.如果一个索引包含了需要查询的所有字段,那么这个索引就是覆盖索引。
2.MySQL 只能使用B+Tree索引做覆盖索引,因为只有B+树能存储索引列值。
索引下推:
索引下推(Index Condition Pushdown)是数据库查询优化的一种技术,通常用于处理包含过滤条件的查询语句。它的原理是在使用索引进行查询时,将查询的过滤条件也应用到索引查找过程中,以减少需要读取和处理的数据量,从而提高查询性能。
索引下推是MySQL5.6推出来的一个查询优化方案,主要的目的是减少数据库中不必要的数据读取和计算。
索引下推的原理是尽可能把查寻条件推到索引层面进行过滤,减少从磁盘读取的数据量。
假设我们有一张表:
当我们尝试执行这样一条SQL语句的时候:
select * from user where name like '张%' and age = 16我们需要从这种表中检索所有姓张并且年龄等于16的用户,在没有开启索引下推之前,MySQL的执行流程为:
- 先从二级索引中根据name匹配所有姓张的人,得到id为1和4。
- 用1和4去主键索引中找匹配的数据行。
- 在MySQL的sever层中,使用”age=16“ 进行过滤。
这种方式,会有两次回表,分别是id=1和id=4,而索引下推就是针对这个场景做出的优化:
因为我们已经有name和age组成的组合索引了,那么我们在查询的时候,直接根据name和age查出id,在根据id查出具体用户。
这样的话就之前牵扯到一次回表,优化了性能。
总结:
总的来说,索引下推和索引覆盖是数据库查询优化中两个重要的概念,它们都旨在提高查询性能和减少资源消耗。索引下推通过在索引查找阶段应用过滤条件,减少了需要读取和处理的数据量,从而显著提高了查询效率。索引覆盖则通过利用索引数据本身包含查询所需的全部信息,避免了对实际数据行的访问,进一步降低了IO成本和CPU开销。
在实际应用中,合理设计和利用索引结构、以及对查询语句进行优化,是提升数据库性能的关键步骤。了解和充分利用索引下推和索引覆盖的原理,可以帮助数据库管理员和开发人员更好地优化数据库架构和查询语句,提升系统的整体性能和响应速度。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!