一、关于效率和适用范围
尽管官方承诺Json格式字段采用了空间换时间的策略,比Text类型来存储Json有大幅度的效率提升。但是Json格式的处理过程仍然效率不及传统关系表,所以什么时候用Json格式字段尤为重要。
只有我们确定系统已经能精确定位到某一行,比如用主键、创建时间范围等,这时候我们的数据集合比较小,那么我们就可以放心大胆的用Json格式字段进行进一步数据处理,而且Json中所存储的信息一定不是检索时必要的筛选信息和统计时需要计算的关键数据,不要妄想在百万行Json字段里对某一个Json属性进行搜索、聚合,这属于纯粹找虐。
比如说我们读个字典,以往要拆成两个表,现在一个表就可以解决;或者说ERP系统里我们可以把万年不查的子表、孙表都放在一个Json字段里,这样用单表即可解决复杂结构化数据存储的问题。
举个每个人都知道具体场景的例子:CMS系统有内容页,传统方式解决扩展字段大多都用键值对表(也就是窄表)来解决问题,但事实上键值对表的查询非常慢,所有的数据都以TEXT的方式存储(因为要照顾到富文本自定义字段),因此非常难以查询,当用户已经点击进入内容页的时候我们已知具体是内容表的哪一行,此时直接将JSON数据返回给前端的效率要完全优于遍历键值对表,而且还能对Json的某个属性加索引,也可以对整个Json串加全文索引,这样对某个栏目下的有限内容的同一个字段就很容易进行统计。
再举一个经常遇到的例子:业务总是在变化,字段总要变,需要兼顾灵活性和效率,不得不用Json字段来处理数据。
二、实测前的准备工作
建表就不用说了,主流建表工具都支持建立Json列。
插入和更新数据也不用说了,就当是操作字符串即可,只有一个局部更新可能需要用到,后面会讲到。
我们这里主要讲查询。
假设我们有这么一个表my_table,后面的例子都用它来举例:
CREATE TABLE `my_table` (`id` bigint NOT NULL AUTO_INCREMENT,`code` varchar(255) NULL,`name` varchar(255) NULL,`attrs` json NULL,`create_time` datetime NULL,`creator` bigint NULL,`last_modify` datetime NULL,`modifier` bigint NULL,`time_stamp` datetime NULL,`deleted` tinyint NULL,PRIMARY KEY (`id`)
);
然后我们准备好要测试的数据
INSERT INTO `my_table` (`id`, `code`, `name`, `attrs`, `create_time`, `creator`, `last_modify`, `modifier`, `time_stamp`, `deleted`)
VALUES (1, 'menu', '菜单', '[{\"code\": \"menu1\", \"name\": \"菜单1\"}, {\"code\": \"menu2\", \"name\": \"菜单2\"}]', NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO `my_table` (`id`, `code`, `name`, `attrs`, `create_time`, `creator`, `last_modify`, `modifier`, `time_stamp`, `deleted`)
VALUES (2, 'sysConfig', '系统设置', '{\"sysName\": \"某综合管理系统\", \"wxAppId\": \"wx1234567\"}', NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO `my_table` (`id`, `code`, `name`, `attrs`, `create_time`, `creator`, `last_modify`, `modifier`, `time_stamp`, `deleted`)
VALUES (3, 'site', '站点设定', '[{\"code\": \"a.myweb.com\", \"extra\": {\"owner\": \"rantUser1\"}, \"visited\": 200}, {\"code\": \"b.myweb.com\", \"extra\": {\"owner\": \"rantUser1\"}, \"visited\": 300}, {\"code\": \"www.example.com\", \"extra\": {\"owner\": \"rantUser2\"}, \"visited\": 157}, {\"code\": \"b2c.example.com\", \"extra\": {\"owner\": \"rantUser2\"}, \"visited\": 775}]', NULL, NULL, NULL, NULL, NULL, NULL);都导入之后,数据大概是这样子的:

各种查询方法
晦涩难懂的官方原版Manual就不给大家重复了,直接上干货:
Json转表
Json转表是第一个要解决的问题,只要变成我们熟悉的表,很多传统MySQL的关联表、集合查询之类的操作都能用上了。
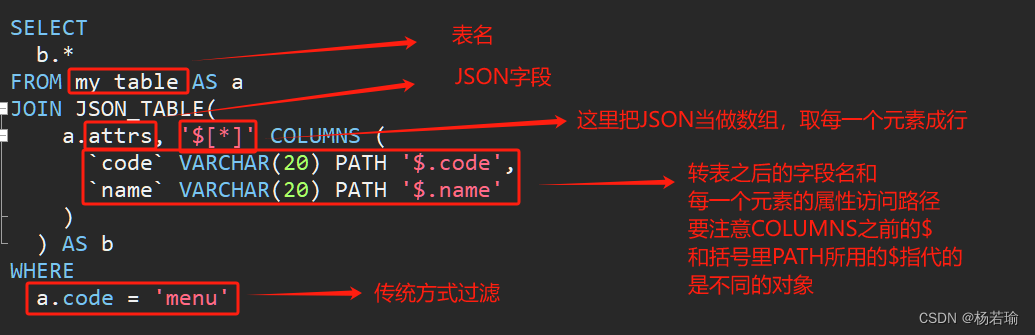
SELECT b.* FROM my_table AS a
JOIN JSON_TABLE( a.attrs, '$[*]' COLUMNS (`code` VARCHAR(20) PATH '$.code',`name` VARCHAR(20) PATH '$.name') ) AS b
WHERE a.code = 'menu'
解析直接看图吧:
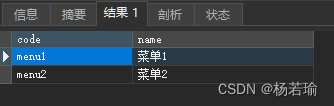
查询结果:
取属性
我们很多时候面向对象开发需要用到ORM框架,但每次都要当做String来用FastJson、Gson之类的框架来解析实在是太麻烦。例如我们有MyBatis这样的框架,直接在SQL语句里把Json的字段都附加上,上层所有的应用框架全都可以认,岂不是一劳永逸。
SELECT *,attrs->>'$.sysName' sys_name,attrs->>'$.wxAppId' wx_app_id
from my_table
where code='sysConfig'
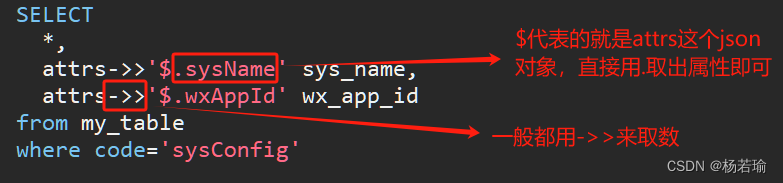
查询结果如下:

维度抽取
这个是针对数组的,echarts之类的框架会需要用到,这里不做赘述
select attrs->>'$[*].code' code_list,attrs->>'$[*].name' name_list
from my_table where code='menu'
查询结果:
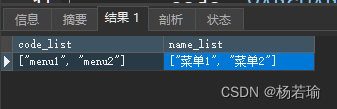
还可以针对多行一起获得维度抽取的结果,如果碰到JSON不是数组的,它也不会报错,只是返回一个null,非常人性化
select id,code,name,attrs->>'$[*].code' sub_code
from my_table
查询结果:

聚合操作
这次我们把已经设定的站点都取出来,根据所有者的不同,把他们网站的访问量都统计出来
SELECTb.owner,sum(b.visited) visited
FROM my_table AS a
JOIN JSON_TABLE( a.attrs, '$[*]' COLUMNS (`owner` VARCHAR(20) PATH '$.extra.owner',`visited` BIGINT PATH '$.visited') ) AS b
WHEREa.code = 'site'
GROUP BY owner

局部更新
有时候我们并不想把整个Json都更新了,只想更新其中一个值(比如多人同时更新一个Json时,各个内存中完整的Json副本都不一样,如果贸然全量更新,就会互相覆盖)
UPDATE my_table
SET attrs = JSON_SET(attrs, '$.sysName', '某网站管理系统')
WHERE code='sysConfig';
通过上面这个方式就可以局部更新sysName这个key对应的值,MySql内部做了优化,如果值是相同的,影响行数则返回0,它并不会无脑覆盖。
总结
至于其他的用法,对于应用层面开发来说没什么太大用途,主要原因是大批量的Json加工压力还是在前端和后台,所以数据库层面只需要关注读取方式、效率以及和ORM框架的兼容性即可。Json字段对于低代码开发、元数据、动态表单之类的应用是很有帮助的,特别是对有些动态数据结构的加工来说,省了很多精力。