原文链接:https://tecdat.cn/?p=37244
原文出处:拓端数据部落公众号
分析师: Cengjun Wang
目前,众多银行由于服务质量的降低、同业竞争的日益激烈等因素,面临着信用卡客户流失的棘手难题,这给银行经理施加了沉重的压力。而且,获取新的信用卡用户所需成本通常高于维持现有用户的成本。本文将通过展示银行信用卡客户流失机器学习预测的案例,并结合一系列Python、R银行信用卡客户流失机器学习预测热门文章合集实例的代码数据,为读者提供一套完整的实践数据分析流程。
然而,如果能够基于客户的部分个人信息,预测出具有潜在流失可能性的信用卡用户,就能够极大程度地降低银行成本,推测出当前在客户管理及业务方面可能存在的问题,进而为制定挽留策略提供有力依据。所以,我们的目标是通过持续不断地优化算法,尽可能精准地预测出信用卡的流失客户。
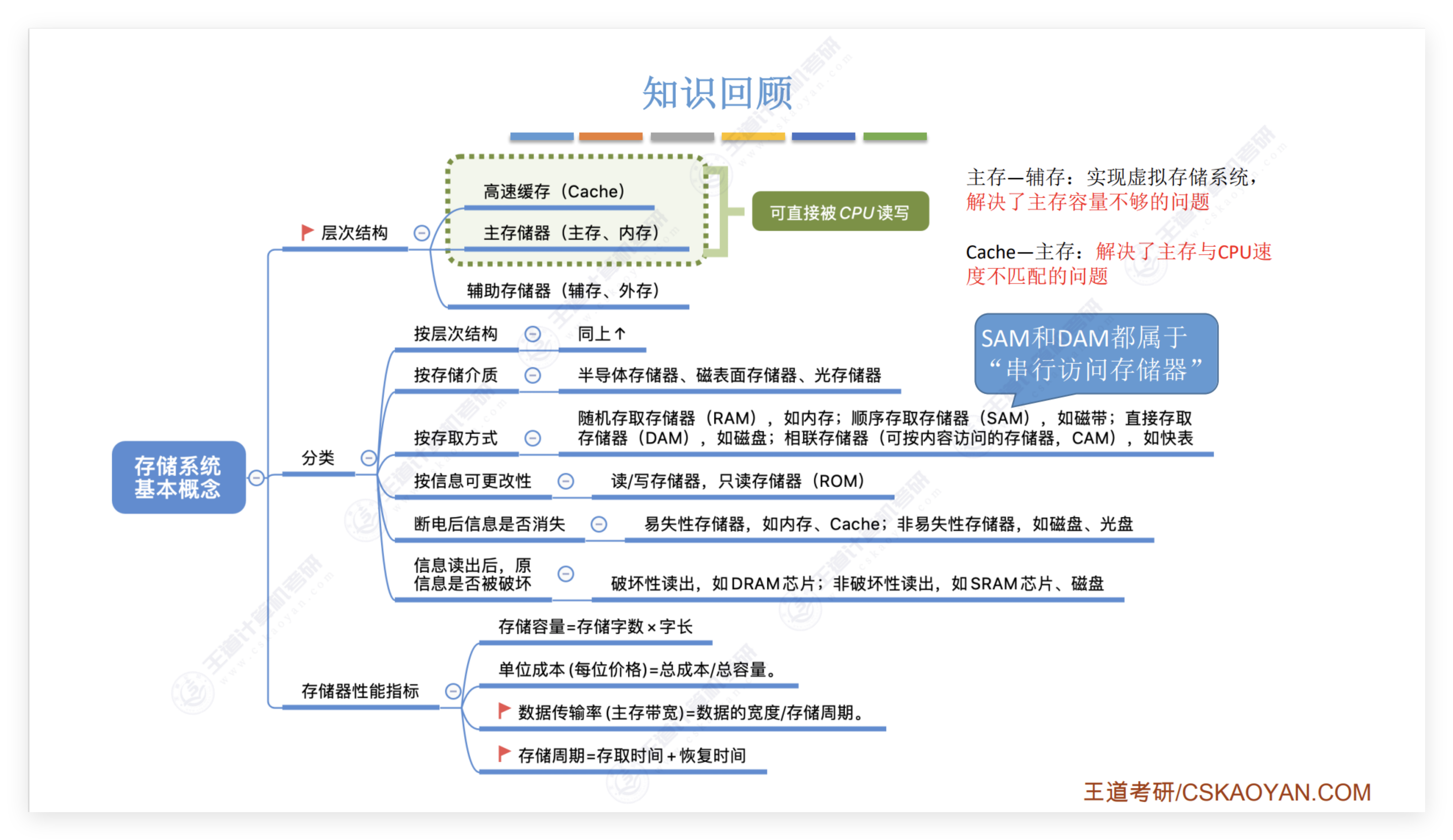
解决方案
任务/目标
计划采用 Python 搭建神经网络算法,并运用集成学习的思想构建随机神经网络模型,逐步优化算法的内部结构与超参数,解决原始数据集训练过程中出现的问题,以获取更出色的预测效果。
数据源准备
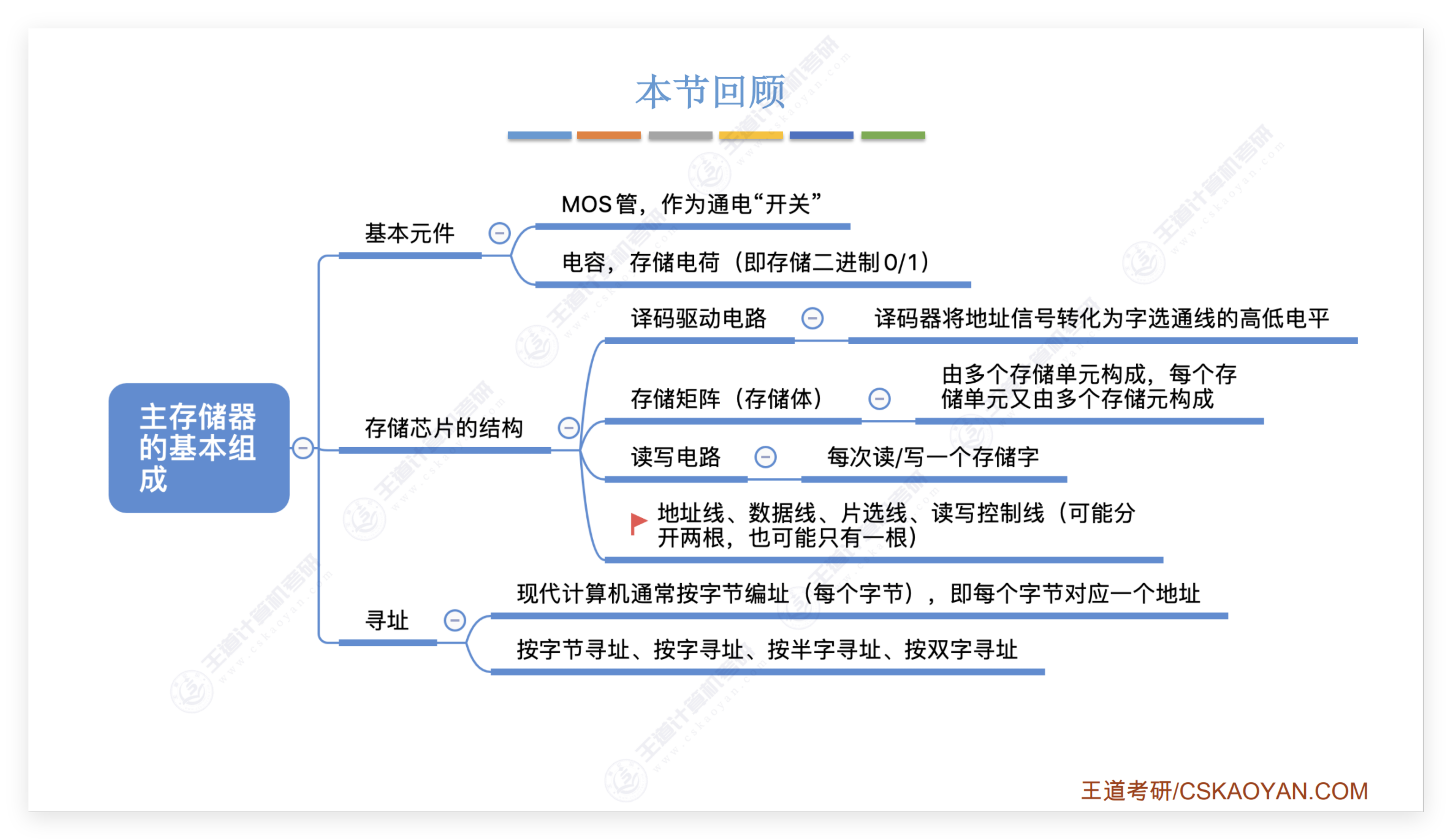
我们获取了 10000 位银行信用卡客户的数据,包含年龄、性别、年收入水平、婚姻状况、信用卡额度、信用卡类型、过去 12 个月的总交易数和总交易金额、是否为流失客户等 18 个变量。在是否流失客户这一变量中,存在诸如年龄、受扶养人数量、与银行的关系期、信用卡额度等连续变量,我们发现它们之间的数量级差异较大,后续在优化过程中会详细阐述如何处理这一问题。
数据预处理
样本不均衡问题
在前期的试验中我们发现,无论是运用 SVM、Logistic Regression 还是 Neural Network,最终测试集的准确率均在 85%上下波动(结果如下图)。

经查看数据集,我们发现样本中存在严重的样本不均衡问题,实际流失的客户比例仅占总体样本的 16.07%,即若模型将所有客户都预测为不流失,整体准确率仍会达到 84%,这与我们最初设定的目标完全相悖,并非我们期望的情况。
因此我们采用了两种方式进行处理,一是 resample, 二是 bootstrap
梯度消失
在训练神经元网络模型时,有时会出现权重调整速度缓慢的情况。下图是对其中一个样本进行五次迭代的结果,我们发现其最终输出结果几乎未发生改变,即模型将其预测为非流失客户,但该样本的真实值是流失客户。
我们认为此问题可能有两个原因:其一,sigmoid 函数自身在接近 0 和 1 时梯度极小,这是无法改变的;其二,使用未经标准化的数据(由于数量级太大)会导致初始值接近 1,而 sigmoid 函数的导数值接近 0,最终造成梯度消失的情况,这部分是可以控制的。
我们假定样本服从正态分布,对其进行统一标准化操作后,下图显示该样本初始的预测值不再出现几乎为 1 的情况,并成功通过梯度下降算法完成了正确预测。
标准化后,能够有效防止极端值的出现,并大幅提升运算效率。
建模
神经网络

随机神经网络(集成学习)

模型优化
调整损失函数、调整迭代次数(early stopping)、调整神经网络的其他参数(学习率、隐藏层层数、隐藏层节点数、激活函数)
对照实验

作为对照,我们调用了 scikit-learn 的 Logistic Regression 模型对这个二分类模型进行预测,然后用 AUC 的指标来横向比较不同模型的预测效果。结果表明,我们的神经网络模型的 AUC(0.93)优于 LR 模型的 AUC(0.91),同时我们的随机神经网络模型的 AUC 也能达到 0.91 的水平。
Python、R银行信用卡客户流失预测热门文章合集
01
R语言逻辑回归模型的移动通信客户流失预测与分析

02
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像

03
PYTHON中用PYTORCH机器学习神经网络分类预测银行客户流失模型

04
R语言决策树和随机森林分类电信公司用户流失churn数据和参数调优、ROC曲线可视化

关于分析师

在此对Cengjun Wang对本文所作的贡献表示诚挚感谢。他在上海交通大学完成了商务数据科学专业学位,专注于商务数据分析和数据科学领域。Cengjun Wang擅长使用Python和SQL进行数据分析和处理,同时在决策树、神经网络和回归分析等数据科学领域有着深入的研究和实践经验。他的专业技能和对数据科学的深刻理解为本文的研究提供了宝贵的支持。



![DFJX[2024] 游记](https://img2024.cnblogs.com/blog/3481178/202408/3481178-20240805151934575-2048908335.png)

![[WACV2022]Addressing out-of-distribution label noise in webly-labelled data](https://img2023.cnblogs.com/blog/3039442/202408/3039442-20240806194717685-1403539735.png)