三国演义内容抓取(诗词名句网)
时间:2024-08-06
一、完整代码
import random
import timeimport requests
from lxml import etreefour_famous_novels = 'https://www.shicimingju.com/bookmark/sidamingzhu.html' # 四大名著在线阅读地址
three_kingdoms = 'https://www.shicimingju.com/book/sanguoyanyi.html' # 三国演艺地址
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}
req = requests.get(three_kingdoms, headers=header)
req.encoding = req.apparent_encoding
# print(req.text)
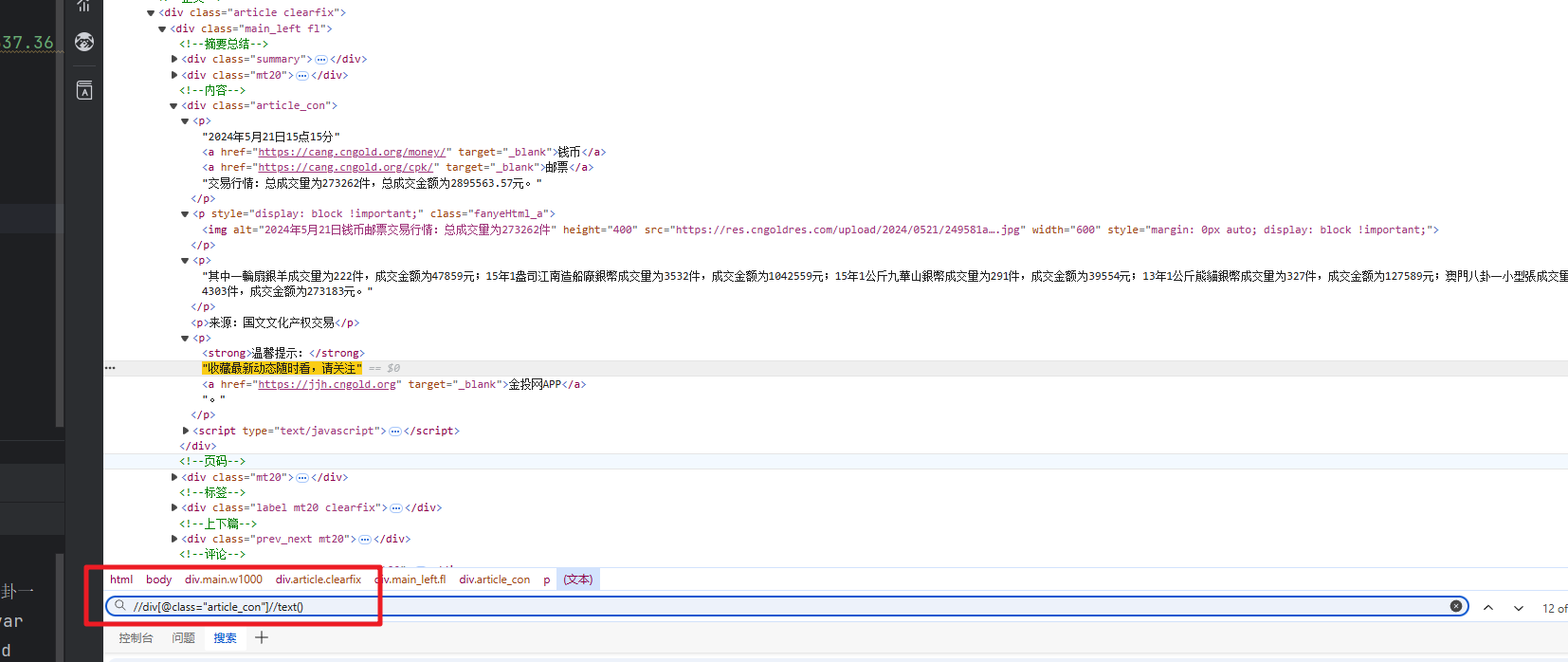
tree = etree.HTML(req.text)
book_mulu = tree.xpath('//div[@class="book-mulu"]/ul/li/a/text()')
mulu_href = tree.xpath('//div[@class="book-mulu"]/ul/li/a/@href')
for i in range(len(book_mulu)):url = 'https://www.shicimingju.com' + mulu_href[i]print(url)req_content = requests.get(url, headers=header)req_content.encoding = req_content.apparent_encodingtree = etree.HTML(req_content.text)content = tree.xpath('//div[@class="chapter_content"]//text()')print(book_mulu[i])print(content)time.sleep(random.randint(1, 4))
效果:

二、知识点
2.1 随机时间点(避免网站压力大)
time.sleep(random.randint(1, 4))
三、思路
第一步: 先抓取目录和目录下面的链接第二步: 循环所有的urls ,然后抓取下面的内容第三步TODO: 创建一个三国演绎的文件夹,然后里面按照 01 章+ 章节名.txt 进行文本内容写入