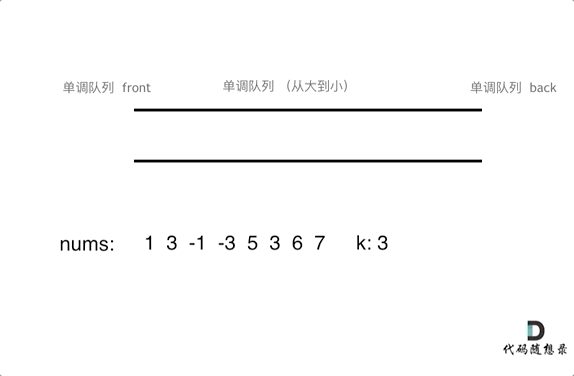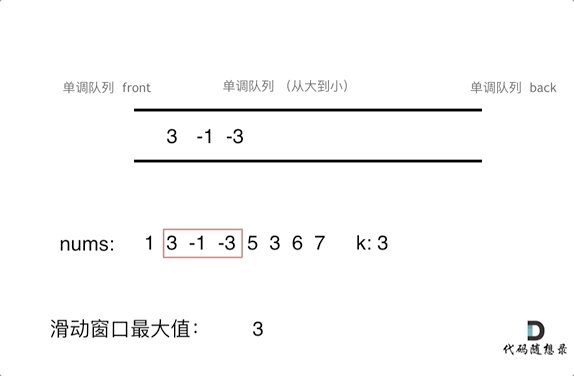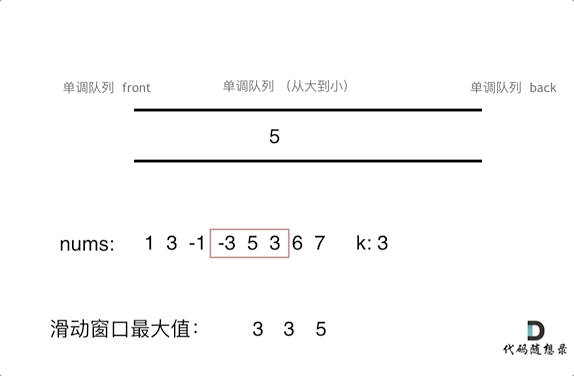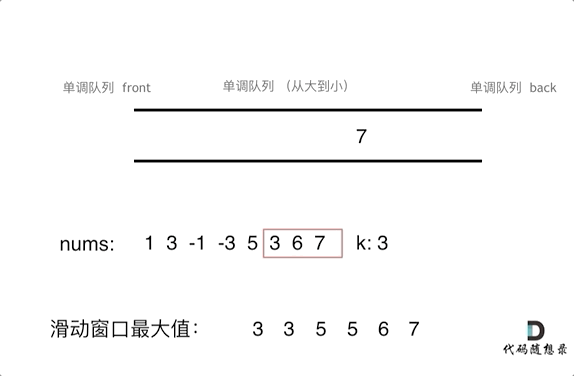
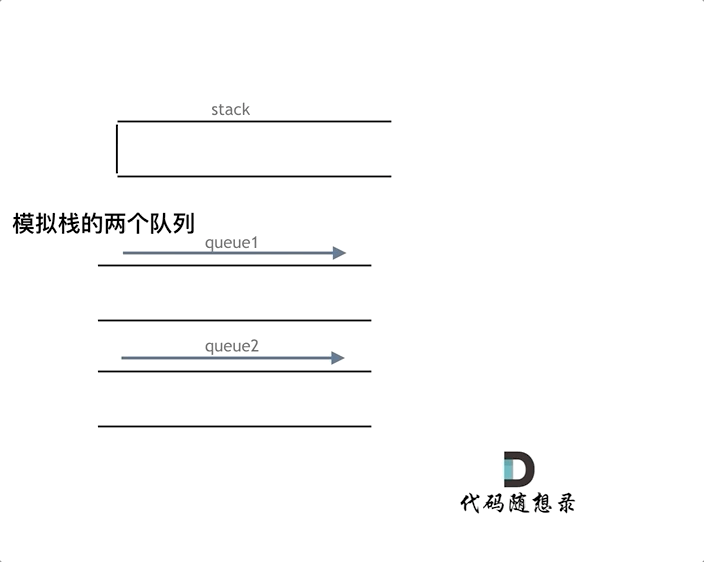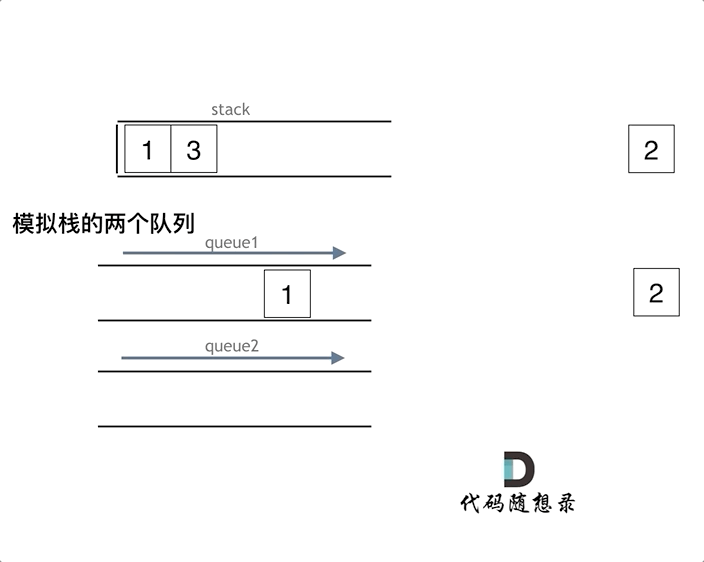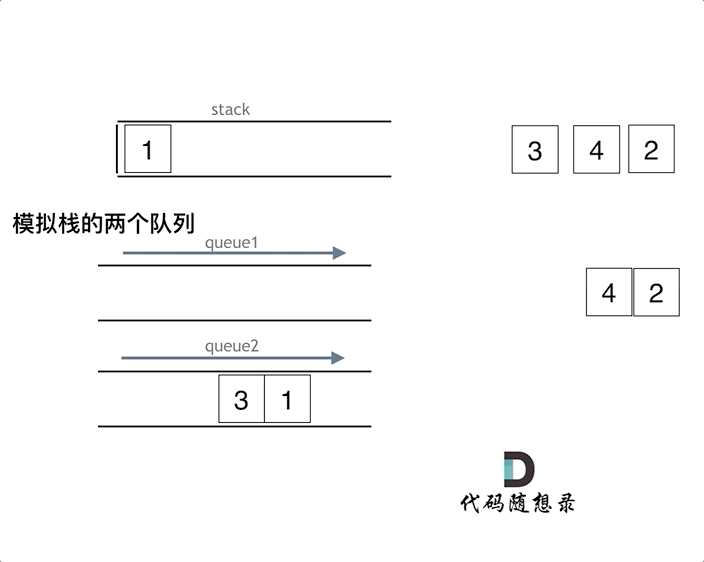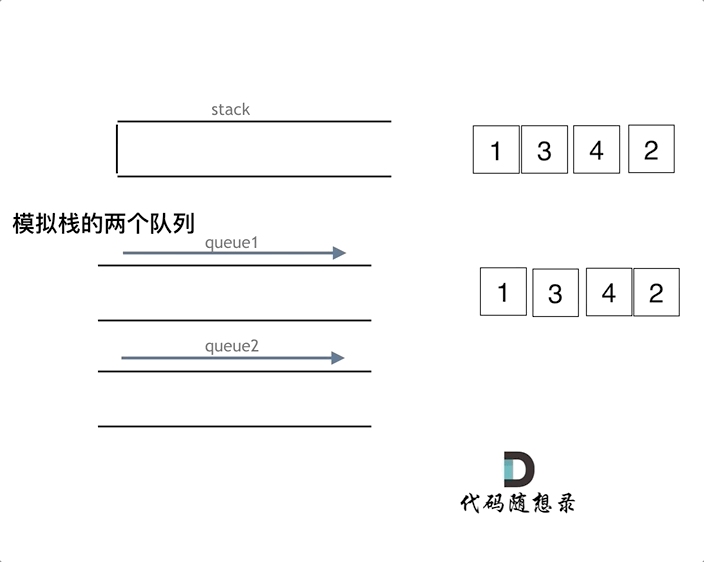
视频内容总结:
视频是由汪周谦主讲,
主题是介绍书生谱语大模型开源开放体系。内容主要包括以下几个方面:

1. **书生谱语大模型的发展历程**:
- 从2023年7月6日起,书生谱语大模型(Interlm)开始免费开源并商用,提供了全链条的开源工具体系。
- 2023年9月底,发布了适合中小企业和科研机构使用的20B模型。
- 2024年1月,Interlm 2.0开源,性能超越同量级开源模型。
- 2024年7月,Interlm 2.5开源,性能显著提升。
2. **技术进步**:
- Interlm 2.5在推理能力、上下文理解(达到一百万级别的聊天记录)和自主规划搜索能力方面有显著提升。
3. **开源生态**:
- 书生谱语的开源生态不仅包括Interlm模型,还涵盖了基于上海人工智能实验室的整个开源体系。
- 包括数据收集、整理、标注、模型训练、微调、评测、搜索引擎和AI应用部署等全链路方案的实现和开源。
4. **数据和工具**:
- 开源了预训练语料库“书生万卷”,以及多种数据集和工具,如数据提取工具minu、标注工具lablmu等。
- 提供了预训练框架interval、微调框架xoner、评测体系opencom和部署工具lmdeploy。
5. **模型性能**:
- 通过不断的迭代和优化,书生谱语大模型在性能上不断接近或超越国际主流模型。
- 演示了模型在处理长文本、复杂任务和多模态数据方面的能力。
6. **智能体框架**:
- 介绍了legend框架,支持与外部工具交互,提高输出的可靠性。
7. **社区和应用**:
- 书生谱语社区活跃,开源项目如雷波lm方便NLP任务的标注。
- 书生谱语大模型实战营成功举办,学员开发了多个毕业项目。
8. **未来展望**:
- 汪周谦表达了对书生谱语大模型开源体系的自豪,并期待未来的发展。
整体来看,汪周谦的演讲重点介绍了书生谱语大模型的开源进展、技术突破和社区生态建设,展示了其在人工智能领域的创新和应用潜力。