Stream流
Stream是Java 8 API添加的一个新的抽象,称为流Stream,以一种声明性方式处理数据集合(侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式)Stream流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算Stream流是对集合(Collection)对象功能的增强,与Lambda表达式结合,可以提高编程效率、间接性和程序可读性。特点:
1、代码简洁:函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环
2、多核友好:Java函数式编程使得编写并行程序如此简单,就是调用一下方法
流程:
1、将集合转换为Stream流(或者创建流)
2、操作Stream流(中间操作,终端操作)
stream流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果
接口继承关系:
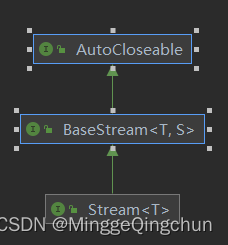
BaseStream:基础接口,声明了流管理的核心方法;
Stream:核心接口,声明了流操作的核心方法,其他接口为指定类型的适配
Java中的流式编程:创建Stream数据流
生成流的方式主要有五种:
2.1、Stream创建
使用静态方法 Stream.of(),通过显式值创建一个流
Stream<Integer> stream = Stream.of(0, 1, 2, 3, 4, 5);
2.2、Collection创建
Collection 集合创建(应用中最常用的一种)
List<Integer> integerList = new ArrayList<>();
integerList.add(0);
integerList.add(1);
integerList.add(2);
integerList.add(3);
integerList.add(4);
integerList.add(5);
Stream<Integer> listStream = integerList.stream();
2.3、Arrays创建
Arrays 数组创建,将数组作为数据源,读取数组中的数据到一个流中
int[] intArr = {0, 1, 2, 3, 4, 5};
IntStream arrayStream = Arrays.stream(intArr);
1
2
2.4:文件创建
通过 Files.line() 方法得到一个流,并且得到的每个流是给定文件中的一行
try {
Stream
} catch (IOException e) {
e.printStackTrace();
}
2.5:函数创建
函数创建,创建无限流
Stream.iterator() 方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为 iterator 生成的流为无限流,通过 limit 方法对流进行了截断
Stream<Integer> iterateStream = Stream.iterate(0, n -> n + 2).limit(5);
Stream.generate() 方法接受一个参数,方法参数类型为 Supplier ,由它为流提供值。generate 生成的流也是无限流,因此通过 limit 对流进行了截断
Stream<Double> generateStream = Stream.generate(Math::random).limit(5);
Java中的流式编程:中间操作
Java中的流式编程:中间操作
通常对于 Stream 的中间操作,可以视为是源的查询,并且是懒惰式的设计,对于源数据进行的计算只有在需要时才会被执行,与数据库中视图的原理相似;
Stream 流的强大之处便是在于提供了丰富的中间操作,相比集合或数组这类容器,极大的简化源数据的计算复杂度。一个流可以跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用这类操作都是惰性化的,仅仅调用到这类方法,并没有真正开始流的遍历,真正的遍历需等到终端操作时,常见的中间操作有下面即将介绍的 filter、map 等。
3.1、filter 过滤
filter 条件过滤,以将流中满足指定条件的数据保留,去掉不满足指定条件的数据
// filter:输出ID大于6的user对象
List<User> filetrUserList = userList.stream().filter(user -> user.getId() > 6).collect(Collectors.toList());
filetrUserList.forEach(System.out::println);3.2、map 映射
map 元素映射,提供一个映射规则,将流中的每一个元素替换成指定的元素
// map
List<String> mapUserList = userList.stream().map(user -> user.getName() + "用户").collect(Collectors.toList());
mapUserList.forEach(System.out::println);3.3、distinct 去重
distinct 去重,去除流中的重复的数据,这个方法是没有参数的,去重的规则与 hashSet 相同
// 去重
dataSource.distinct().forEach(System.out::println);
3.4、sorted 排序
sorted 排序,将流中的数据,按照其对应的类实现的 Comparable 接口提供的比较规则进行排序
// sorted:排序,根据名字倒序
userList.stream().sorted(Comparator.comparing(User::getName).reversed()).collect(Collectors.toList()).forEach(System.out::println);3.4、limit & skip 限制 & 跳过
limit 限制,表示截取流中的指定数量的数据(从第0开始),丢弃剩余部分
skip 跳过,表示跳过指定数量的数据,截取剩余部分
// 获取成绩的[3,5]名
dataSource.sorted((s1,s2) -> s2.score - s1.score).distinct() .limit(5).skip(2).forEach(System.out::println);
3.5、flatMap 扁平化映射
使用 flatMap 方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用 map(Arrays::stream) 时生成的单个流都被合并起来,即扁平化为一个流
// 一般是用在map映射完成后,流中的数据是一个容器,而我们需要再对容器中的数据进行处理,此时使用扁平化映射
// 将字符串数组中的数据读取到流中
Stream
// 统计字符串数组中所有出现的字符
stream.map(e -> e.split("")) .flatMap(Arrays::stream).distinct().forEach(System.out::print);
3.6、peek 对元素进行遍历处理
// peek:对元素进行遍历处理,每个用户ID加1输出
userList.stream().peek(user -> user.setId(user.getId()+1)).forEach(System.out::println);
4、Java中的流式编程:终端操作
Stream 流执行完终端操作之后,无法再执行其他动作,否则会报状态异常,提示该流已经被执行操作或者被关闭,想要再次执行操作必须重新创建 Stream 流
一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。
终端操作的执行,才会真正开始流的遍历。如 count、collect 等
4.1、collect 收集器
collect 将流中的数据整合起来
// collect:收集器,将流转换为其他形式
Set set = userList.stream().collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("--------------------------");
List list = userList.stream().collect(Collectors.toList());
list.forEach(System.out::println);
4.2、forEach 遍历流
forEach 遍历流中数据
// forEach:遍历流
userList.stream().forEach(user -> System.out.println(user));
userList.stream().filter(user -> "上海".equals(user.getCity())).forEach(System.out::println);
4.3、findFirst & findAny 获取流中的元素
findFirst 获取流中的一个元素,获取的是流中的首元素,在进行元素获取的时候,无论是串行流还是并行流,获取的都是首元素
// findFirst:返回第一个元素
User firstUser = userList.stream().findFirst().get();
User firstUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findFirst().get();
findAny 获取流中的一个元素,通常是首元素,但在并行流中,获取的可能不是首元素。在进行元素获取的时候,串行流一定获取到的是流中的首元素,并行流获取到的可能是首元素,也可能不是
// findAny:将返回当前流中的任意元素
User findUser = userList.stream().findAny().get();
User findUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findAny().get();
4.4、count 总数
count 返回流中元素总数
// count:返回流中元素总数
long count = userList.stream().filter(user -> user.getAge() > 20).count();
System.out.println(count);
4.5、sum 求和
// sum:求和
int sum = userList.stream().mapToInt(User::getId).sum();
4.6、max & min 最大 & 最小
// max:最大值
int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId();
// min:最小值
int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId();
4.7、reduce 聚合
reduce 将流中的数据按照一定的规则聚合起来
// reduce:将流中元素反复结合起来,得到一个值
Optional reduce = userList.stream().reduce((user, user2) -> {return user;
});
if(reduce.isPresent()) System.out.println(reduce.get());
4.8、allMatch & anyMatch & noneMatch
allMatch: 只有当流中所有的元素都匹配指定的规则,才会返回 true
anyMatch: 只要流中的任意数据满足指定的规则,就会返回 true
noneMatch: 只有当流中所有的元素都不满足指定的规则,才会返回 true
// allMatch:检查是否匹配所有元素
boolean matchAll = userList.stream().allMatch(user -> "北京".equals(user.getCity()));
// anyMatch:检查是否至少匹配一个元素
boolean matchAny = userList.stream().anyMatch(user -> "北京".equals(user.getCity()));
// noneMatch:检查是否没有匹配所有元素,返回 boolean
boolean nonaMatch = userList.stream().allMatch(user -> "北京".equals(user.getCity()));
5、Collect收集
Collector:结果收集策略的核心接口,具备将指定元素累加存放到结果容器中的能力;并在Collectors工具中提供了Collector接口的实现类
5.1、toList
将用户 ID 存放到 List 集合中
List<Integer> idList = userList.stream().map(User::getId).collect(Collectors.toList()) ;
5.2、toMap
将用户 ID 和 Name 以 Key-Value 形式存放到 Map 集合中
Map<Integer,String> userMap = userList.stream().collect(Collectors.toMap(User::getId,User::getName));
5.3、toSet
将用户所在城市存放到 Set 集合中
Set<String> citySet = userList.stream().map(User::getCity).collect(Collectors.toSet());
5.4、counting
符合条件的用户总数
long count = userList.stream().filter(user -> user.getId()>1).collect(Collectors.counting());
5.5、summingInt
对结果元素即用户 ID 求和
Integer sumInt = userList.stream().filter(user -> user.getId()>2).collect(Collectors.summingInt(User::getId)) ;
5.6、minBy
筛选元素中 ID 最小的用户
User maxId = userList.stream().collect(Collectors.minBy(Comparator.comparingInt(User::getId))).get() ;
5.7、joining
将用户所在城市,以指定分隔符链接成字符串
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));
5.8、groupingBy
按条件分组,以城市对用户进行分组;
Map<String,List<User>> groupCity = userList.stream().collect(Collectors.groupingBy(User::getCity));