Lecture 04 Rendering on Game Engine
Challenges on Game Rendering
- 成千上万不同类型的物体
- 在现代计算机上跑(CPU、GPU的复杂结合)
- 稳定帧率
- 帧率
- 分辨率
- 限制CPU带宽和内存
- 渲染只占20%左右,剩下留给Game logic、网络、动画、物理和AI系统等等
Outline of Rendering
- Basics of Game Engine
- 硬件结构
- 渲染数据组织
- Visibility
- Materials、Shaders and Lighting
- PBR (SG, MR)
- Shader模型
- Lighting
- Point / Directional lighting
- IBL / Simple GI
- Special Rendering
- Terrain
- Sky / Fog
- PostProcess
- Pipeline
- Forward, deferred rendering, forward plus
- Real pipeline with mixed effects
- Ring buffer and V-Sync
- Tiled-based rendering
Building blocks of Rendering
渲染管线相关内容见GAMES101,不再赘述
-
GPU
-
SIMD Single Instruction Multiple Data
一个指令完成多维加减法
比如矩阵运算、坐标运算下会使用
-
SIMT Single Instruction Multiple Thread
一条指令在许多核上做同样指令操作
比如计算着色器、CUDA
所以绘制时尽可能用同样的代码,使用自己的数据来运算
-
现代GPU架构
-
GPC Graphics Processing Cluster
图形处理集群,用于计算、光栅化、着色和纹理
-
SM Streaming Multiprocessor
用来跑CUDA kernels
不同SM含有Shared Memory
-
Texture Units
纹理处理单元,可以fetch和filter纹理
-
CUDA Core
并行运算单元
-
Warp
线程集合
-
-
-
Data Flow from CPU to GPU
- CPU与内存
- 数据加载/卸载
- 数据预备
- CPU to GPU
- 高延迟
- 带宽限制
- 因此尽可能单向从CPU往GPU送数据,而不要从GPU读数据
- GPU和显存
- 高性能并行渲染
- CPU与内存
-
Be Aware of Cache Efficiency
数据恰好在缓存上叫Cache hit,否则叫Cache miss,就要等很久
- 全力利用硬件并行计算的优势
- 避免冯诺依曼瓶颈
-
GPU Bounds and Performance
应用程序性能被以下限制
- Memory Bounds
- ALU Bounds
- TMU (Texture Mapping Unit) Bound
- BW (Bandwidth) Bound
-
Modern Hardware Pipeline
- D3D12的mesh shader
-
其他架构
-
比如主机UMA架构(内存是共享的)
-
移动端架构
考虑到功耗和芯片性能,发展出了Tile-Based Rendering
two-pass渲染,pass one中不被剔除的图元才在pass two中执行fragment shader
# Pass one for draw in renderpass:for primitive in draw:for vertex in primitive:execute_vertex_shader(vertex)if primitive not culled:append_tile_list(primitive)#Pass two for tile in renderpass:for primitive in tile:for fragment in primitve:execute_fragment_shader(fragment)
-
Mesh Render Component
-
Everything is a game object in the game world
-
Game object could be described in component-based way
-
game object中表达的游戏对象和真实要绘制的是两个东西(mesh component)
-
在mesh component中会存renderable,拿到renderable就可以绘制出来
-
renderable
-
mesh
-
material
-
texture
-
normal
-
...
-
Mesh
-
Mesh包含
- 顶点位置
- 法向朝向
- UV
- ...
-
Mesh表达
存顶点索引值,因为顶点会被共用
-
Vertex Data
- Vertex declaration
- Vertex buffer
-
Index Data
-
Index declaration
-
Index buffer
实际上可以不存储Index buffer,可以每个三角形的顶点索引记为一组(triangle stripe)
-
-
Materials
在现代引擎中,一般在绘制系统中只定义视觉材质,物理材质单独定义
包含Shader和Texture
- Phong模型
- PBR
- ...
Texture
- Albedo
- Normal
- Metallic
- Roughness
- AO
- ...
Variety of Shaders
现代游戏引擎中shader既可以看作源代码也可以看作Assets
绘制时,需要给一小段代码,叫作blob (二进制数据块),是编译好的shader代码
-
Shader Graph
连连看生成shader代码
Render Objects in Engine
Coordinate System and Transformation
模型Asset在局部坐标系定义,最终需要渲染到屏幕空间
Object with Many Materials
-
Mesh
-
Vertex Data
- positions
- uv
- ...
-
Index Data
用Submesh管理,根据材质不同,切分成submesh,对应自己的材质、纹理、shader,但是会把顶点放在一个大的buffer中,这样只需要用offset和count去取就好
- Submesh
- offset
- count
- Submesh
-
-
Material
- Shader
- Textures
Instance: Use Handle to Reuse Resources
如果绘制很多东西时,每个GameObject都存储Mesh、submesh,各种材质、shader、纹理,这样数据量就非常大,并且这里很多东西都是一样的
于是在现代游戏引擎中会建立一个Resource Pool
- 所有的Mesh放在一起,形成Mesh Pool
- 所有Texture放在一起
- 所有Shader放在一起
这样不同Instance只是通过一个指引指向各自需要的材质、网格等等(实例化:使用Handle复用资源)
Sort by Material
每次改变参数(纹理、shader)时损耗大,因为显卡的Streaming Multiprocessor都得停下来等到改好再运转
场景中相同材质的物体有相同的参数、相同的纹理,那么将场景中的物体按照材质排序,只设置一次材质,绘制一个个Submesh,速度就会更快
比如像DX12、Vulkan会专门将GPU的状态设置专门抽象成一个Render State Object,对显卡状态先定义好,然后一次性做大量的运算
GPU Batch Rendering
很多子物体是一模一样的,那么依次设置VBIB (Vertex and Index Buffer Validation 顶点和索引缓冲区验证) 也很浪费,所以用计算着色器或者其他shader的能力,可以一个drawcall,设置依次VBIB,和它绘制的一堆位移的数据,就能一次性创建成百上千个物体
struct batchData
{SubmeshHandle m_submesh_handle;MaterialHandle m_material_handle;std::vector<PerInstanceData> p_instance_data;unsigned int m_instance_count;
}Initialize Resource Pools
Load ResourcesCollect batchData with same submesh and materialfor each BatchDataUpdate ParametersUpdate TexturesUpdate ShaderUpdate VertexBufferUpdate IndexBufferDraw Instance
end
将大量的绘制运算交给GPU而不是CPU,比如一次性要绘制几百米开外的树、草
Visibility Culling
大多数空间的物体、对象、粒子效果、地形等都不需要绘制
Visibility Culling是绘制系统一个最基础的系统
检测物体包围盒在不在视锥体
-
包围盒
-
Sphere
-
AABB
轴对称包围盒,轴是游戏世界中的坐标轴,那么只用存两个端点就能构建出一个AABB,计算效率仅次于Sphere包围盒
-
OBB
贴着物体走
-
8-DOP
-
Convex Hull
凸包
-
-
包围盒是很多计算的基础
- intersection test消耗不高
- Tight fitting
- 计算开销小
- 旋转和位移简单
- 内存消耗小
-
Hierarchical View Frustum Culling
-
Quad Tree Culling
四叉树Culling
-
BVH (Bounding Volume Hierarchy) Culling
现代游戏引擎用得多,BVH效率不是最高的,但是因为动的物体多,重新构建层级结构快
-
PVS (Potential Visibility Set)
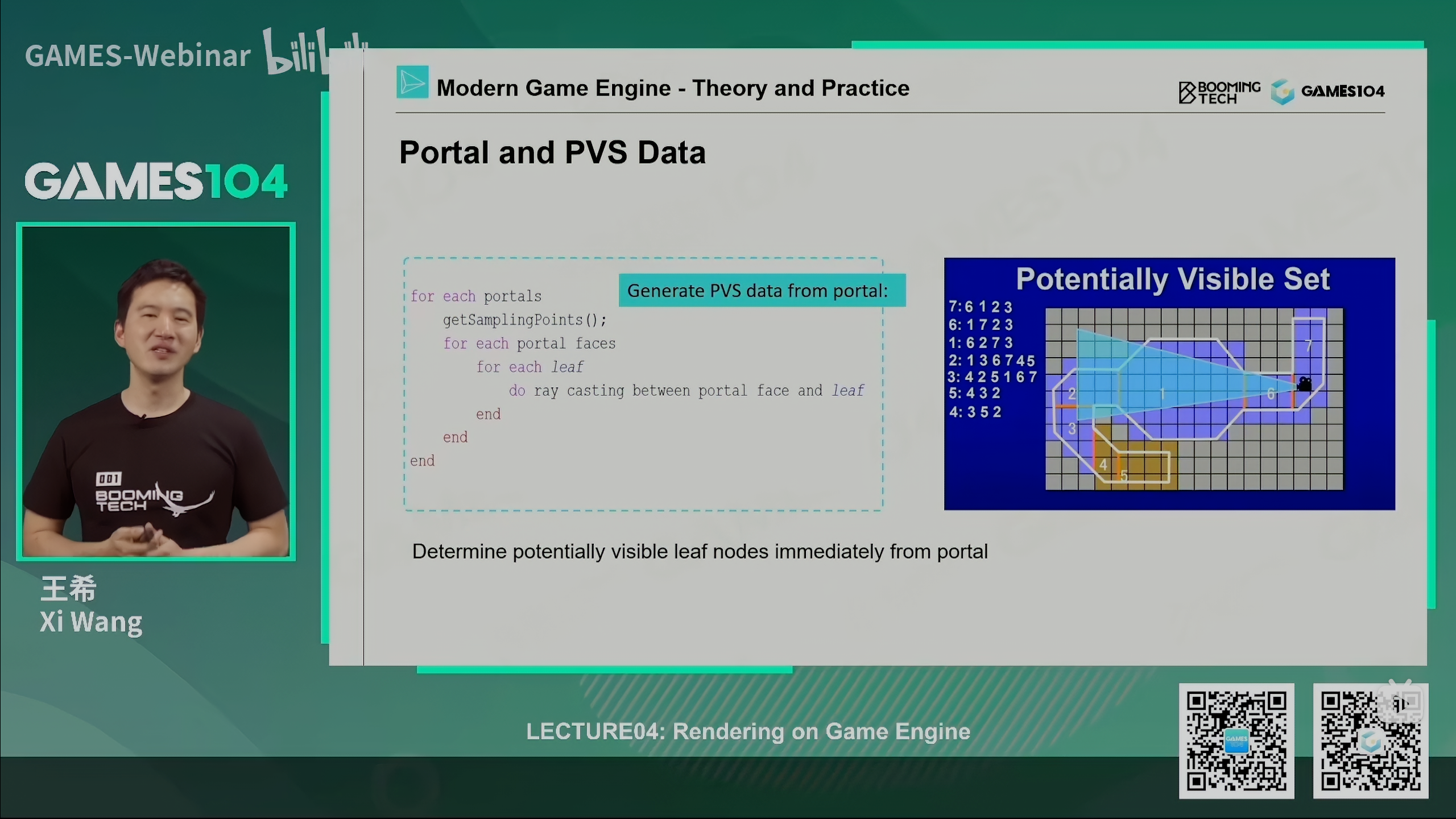
一种思想,现在全面用PVS做Culling的游戏不多了,但是这种思想很有用,比如说线性单机游戏,在每个区域能看到区域是固定的,这样做除了Visibility Culling外还可以用作资源的加载
在大世界中的应用可参考UE5的City Sample
先用BSP-Tree
先将空间分成一个个小方块,每个小方块通过一个Portal连接,在每个方块中通过Portal只能看到固定几个方块,比如图中在7号房间只能看到6、1、2、3四个房间,那么就只需要渲染这四个房间
原理简单,但对空间的划分算法比较复杂
-
Texture Compression 纹理压缩
纹理压缩不能用图片上比较好的压缩方法,比如JEPG格式,因为不支持随机访问
纹理压缩一般采取的思想是Block-based,将图片切成一个个小块(比如\(4\times4\)),然后找其中颜色最亮的点和最暗的点,那么剩下的点就是这两个点的插值(因为很多图片相邻的像素都有关联),
于是就只能存一个最大值,一个最小值,然后每个像素存一个离最大值、最小值的比例关系,就能近似表达这个小色块的颜色,整个计算机图形学的纹理压缩都是基于这个思想的
-
PC
- BC7 (modern)
- DXTC (old)
-
mobile
-
ASTC (modern)
分块可以不再是严格的\(4\times4\),而是任意形状,而且效果是最好的,解压缩的效率也不低,但是压缩的运算比较费性能,不能运行中进行压缩
-
ETC / PVRTC (old)
-
构建引擎时纹理压缩是非常重要的模块,而且加载到显卡中的基本上是压缩过的数据格式
Authoring Tools for Modeling
Comparison of Authoring Methods
- Polymodeling
- 灵活
- 工作负担大
- Sculpting
- Creative
- 大量volume of data
- Scanning
- Realistic
- 大量volume of data
- Procedural modeling
- Intelligent
- 难以实现
Cluster-Based Mesh Pipeline
将复杂模型分成一个个小的meshlet(比如32个三角形),每个meshlet固定后,计算是非常一致的、高效的
这样每个Instance都能并行化绘制
- GPU-Driven Rendering Pipeline (2015)
- Mesh Cluster Rendering
- Arbitrary number of meshes in single drawcall
- GPU-culled by cluster bounds
- Cluster depth sorting
- Mesh Cluster Rendering
- Geometry Rendering Pipeline Architecture (2021)
- Rendering primitives are divided as:
- Batch: a single API draw (drawIndirect / DrawIndexIndirect), composed of many Surfs
- Surf: submeshes based on materials, composed of many Clusters
- Cluster: 64 triangles strip
- Rendering primitives are divided as:
Programmable Mesh Pipeline
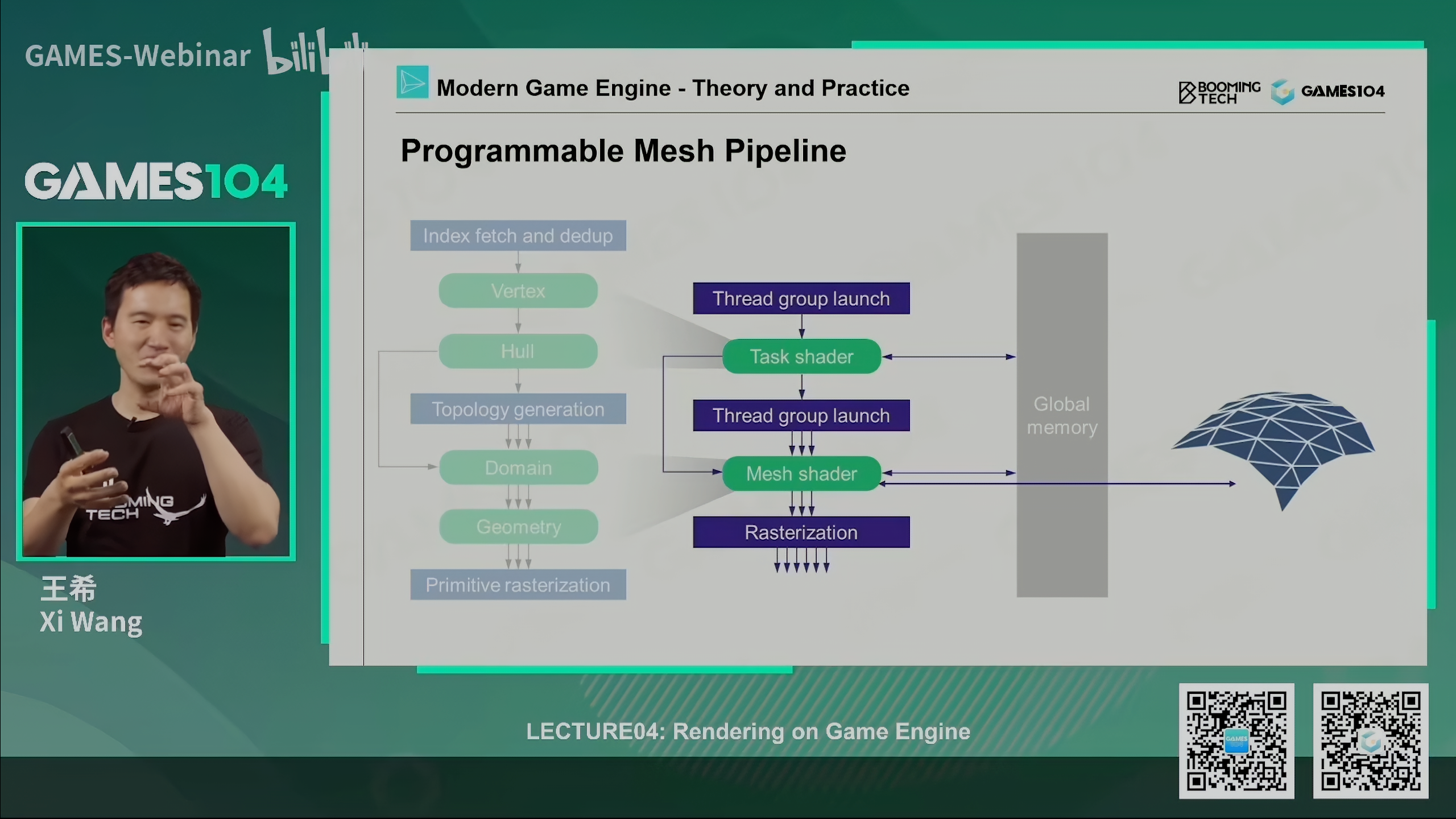
- 游戏引擎与硬件结构涉及深度相关
- submesh design被用于单个模型的多材质
- 使用culling算法减少绘制物体
- 将更多工作移至GPU (GPU-Driven)
Q&A
- 图形代码的Debug
- 不要一次性写完所以代码,每次写一部分,反复验证,没问题后再继续




![[笔记]Tarjan](https://img2024.cnblogs.com/blog/3322276/202408/3322276-20240831120223059-558260414.png)