Lecture 12 Real-Time Ray Tracing
Basic idea

sample per pixel PPS
1 SPP path tracing = $$\downarrow$$
- camera出发打到求出第一个交点(像素上看到的点),这一步是primary ray(工业上实际用rasterization)
- 工业上这一步有一个技巧
- 将这一步改为光栅化
- 因为每个像素都要从camera出发打一条光线看打到了什么,这一步和光栅化做法一模一样
- 并且光栅化更快
- 从第一个交点和光源做连接,做light sampling, 看是否可见(shadowing ray, primary visibility)
- 这一步与前一步实现的是直接光照
- 从shading point上进行采样(secondary ray)
- secondary ray打到的点与光源连接,看是否能看到光源 (secondary visibility)
通过RTX硬件加速能够做1SPP的光追(2080ti时代),但是得到的结果会有非常巨大的噪声
所以RTRT最关键的技术是Denoising降噪
目标(1SPP情况下)
- 质量(无overblur、无artifacts,保证所有细节)
- overblur指滤波核过大,导致结果过于模糊
- 看起来奇怪的地方,是可见的bug
- 速度 一般每帧2ms以内,最多不超过5ms
这些要求达不到
- Sheared filtering series (SF, AAF, FSF, MAAF, ...)
- 离线滤波方法
- 深度学习系列 (CNN, Autoencoder, ...)
- 稍微复杂的网络跑一遍就得几十到几百ms了
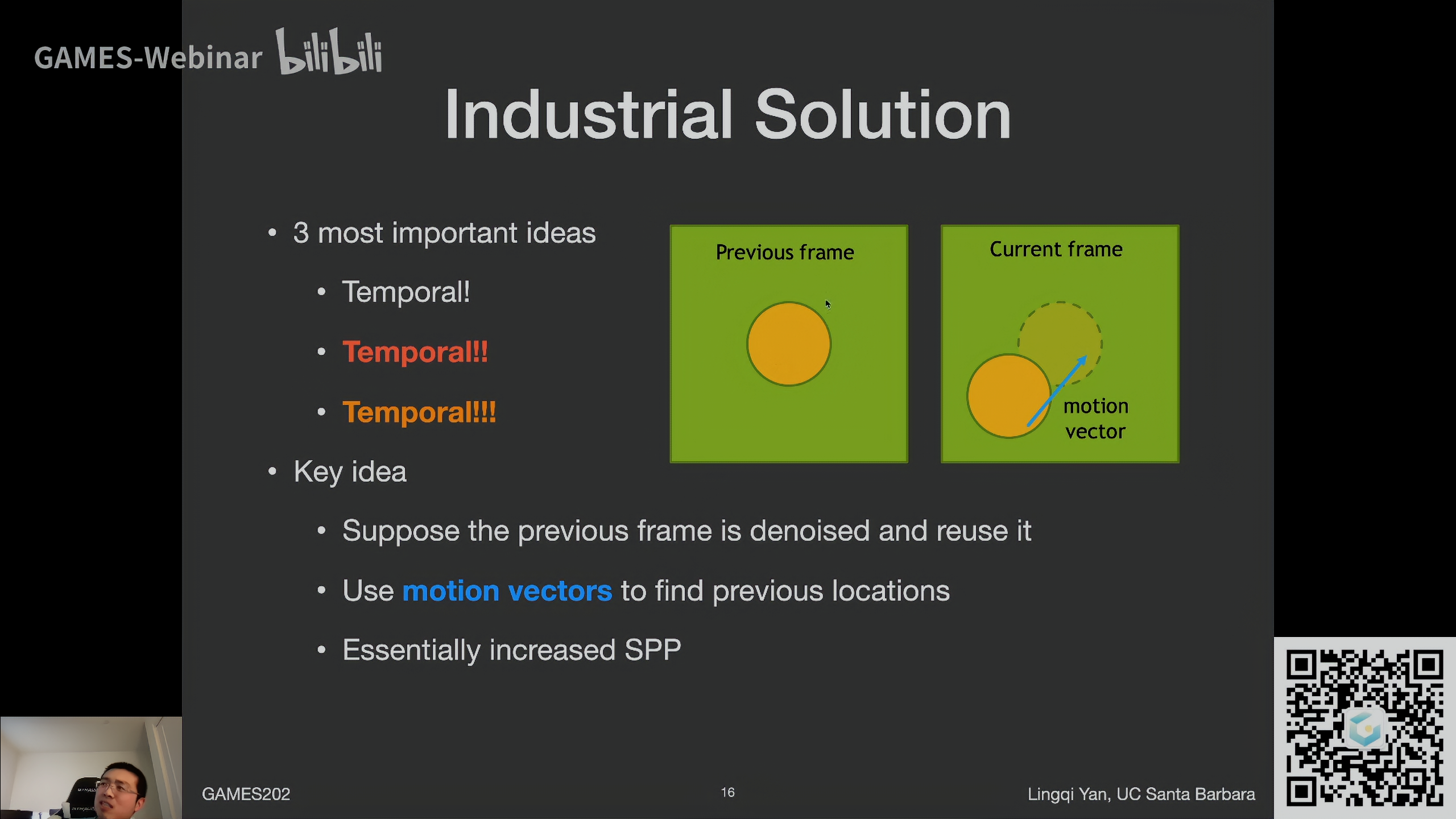
工业界的做法,核心是Temporal
Key idea
- 认为前一帧是滤波好的,复用它
- 所有运动都是连续的,没有突然的变化(实际上不可能)
- 使用motion vector找到上一帧的位置
- 通过这种方法相当于增加了SPP
- 并不是增加了1SPP,因为这是一个递归的思路,每一帧都利用上
- 是一个指数下降
- Spatial?空间上怎么降噪?
Motion vector
G-Buffers
Geometry buffer 几何缓冲区
- 渲染过程中可以免费得到的额外信息
- 代价很小,可以认为免费(轻量级)
- 一般有每像素深度、法线、世界坐标等等
- 只有屏幕空间信息
- G-buffer是第一趟光栅化代替光追时得到的
Back Projection
要求当前帧$$i$$中的像素$$x$$在前一帧$$i-1$$中的位置,两种做法都可以
-
当前帧$$i$$中的像素$$x$$在前一帧$$i-1$$中的位置
- 从后项求前项
-
前一帧$$i-1$$中的哪个像素包含当前帧$$i$$的同一个地方/点
- 从前项求后项
要求像素的世界坐标有两种方法,二选一
- 直接从G-buffer中获取(推荐)
-
\[s=M^{-1}V^{-1}P^{-1}E^{-1}x$$,这里$$E$$是视口变换 - 要变回齐次坐标,所以输入不能是2D的屏幕坐标,得是带深度的齐次坐标 - 注意视口变换没有改变深度值 - 关于为什么要乘以Model矩阵的逆矩阵,因为场景中的问题可能会移动,乘以当前帧这个物体的$M^{-1}$,找到`localPosition`,再乘以上一帧这个物体的$M$矩阵就能准确得到世界坐标 \]
- 如果物体发生了运动,那么运动向量$$T$$已知
-
\[s'\stackrel{T}{\rightarrow}s$$,则$$s'=T^{-1}s \]
- s是局部坐标系
- Motion Vector是两帧同一个像素的屏幕空间坐标之差
-
- 该像素在上一帧的对应$$x'=E'P'V'M's'$$
- 在计算机视觉里求上一帧像素位置的操作叫optical flow光流
- 图形学的这种计算是准确的
- 而光流是基于内容的,不准确
- 这些操作都是在图像上的
- 物体移动后的光线信息可能会改变
Temporal accumulation / filtering
于是就可以将当前帧有noise的图和上一帧没有noise的图结合在一起
最简单的做法就是做一个线性blending
- 首先先对当前帧做一个特殊的降噪
-
\[\overline C^{(i)}=Filter[\widetilde C^{(i)}] \]
- 无法仅依赖于当前帧的降噪,因为在1SPP单纯降噪效果不够
-
- 再做一个线性blending
-
\[\overline C^{(i)}=\alpha \overline C^{(i)}+(1-\alpha)C^{(i-1)} \]
-
- 如何平衡$$\alpha$$的数值?
- 一般取$$0.1\sim 0.2$$
- 说明$$80%\sim90%$$是来源于上一帧
- 如果两帧之间光照变化,就不能依赖上一帧了
- 降噪后明显变亮了?
- 实际没有变亮,降噪前后是能量守恒的
- 原因是降噪前某些噪点的亮度超过显示器范围,被clamp到了1
- 所以显得暗了
- 滤波绝对不会使一张图变亮或者变暗
Failure cases
-
case 1: switching scenes 这是shading上的问题
切换场景、切换光照、切换镜头都会导致上一帧不能复用
需要一个burn-in period积累前几帧的信息

这里是一个光源移动的例子,场景和camera没有移动,所以motion vector是0,这样沿用上一帧会导致阴影拖尾 (detached/lagging shadows)
-
case 2: 倒退着走(屏幕空间问题)

因为倒退着走时,越来越到的信息出现在屏幕中,会导致新出现到屏幕中的点在上一帧找不到对应
如图中倒退着走,越来越多的东西会出现在镜头中
-
case 3: 突然出现的背景 disocclusion问题 同样是屏幕空间问题

当箱子移动后,右侧当前帧蓝点在左侧前一帧对应的位置正确,但是在上一帧,这个物体处于被遮挡的状态,导致其实找不到正确的信息
这也是一种屏幕空间问题,因为这一点在上一帧被遮挡,根本没有存它的信息
-
那么要将上一帧拆成不同深度吗?
不要,开销太大了
-
-
case 4: glossy reflection 在shading上的问题
反射物移动,反射接收物不动(地板),会导致反射光滞后

motion vector只反映了物体在几何上的变化,在shading上的错误通过传统的motion vector没办法解决
错误处理
-
无视错误,强行复用上一帧
- 造成lagging 拖尾
-
Clamping
比如failure case3中,造成拖影的原因是将上一帧错误的黄色用在这一帧白色的地方
那么任何时候应用上一帧的值的时候,都先将上一帧的值拉近到当前帧的结果(Clamping),再去做blending,就看不出问题了
-
极端情况
- 如果拉的过大,太过偏离上一帧的结果,接近当前帧的结果,那么用上一帧就没意义了
- 取当前帧该点(空间上)周围一个范围,求出均值和方差,将上一帧没有noise的值clamp到这个范围内(均值$$\pm$$几个方差 )
- 注意是将上一帧的结果拉到当前帧,如果将当前帧结果拉到上一帧,拖影就更严重了
-
当然会有噪声,原本拖影的地方变成噪声了
-
-
Detection
检测要不要用上一帧的信息
- 使用object ID
- 调整$$\alpha$$,非0即1,或者根据偏差的情况调整
- 上一帧没有noise,当前帧有noise,调整后更多地依赖当前帧,noise也就更多了
- 尽可能增强或者增大filter
- 让当前帧更糊了,不过总比噪声好
-
两种方法都相当于重新引入了noise
Temporal Anti-Aliasing (TAA)
Temporal accumulation / filtering和TAA 时间上抗锯齿的概念基本等同
二者都是复用上一帧对应的位置,相当于提高一个像素的采样数,从而减少锯齿
*一切利用Temporal的方法都差不多,包括DLSS
- Temporally Reliable Motion Vectors for Real-time Ray Tracing
- Eurographics (EG)
- 这篇论文提出了一些motion vector,让它可以追踪阴影、反射、遮挡出现的变化,从而部分解决前面提到的Shading上的failure
- 但是无法解决屏幕空间问题,因为就是不知道屏幕外的信息,无法解决

![[转]高斯-牛顿算法](https://img-blog.csdn.net/20160609002742523)

