https://ac.nowcoder.com/acm/contest/91849
多年退役找工作选手膜拜众出题大佬!!!出的题特别好!!!
A
寻找分开的若干个11..1串,比如串001110001111,就是111和1111。
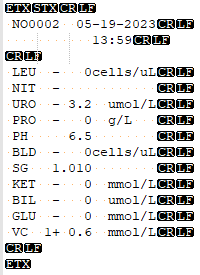
首先,认为所有的0,都是识别正确的,这些0的下一个位置,都是人类。即0 next = Human。
其次,对于11..1串,从右到左,它们可以这样设置(H代表人类,B代表机器):
| 0 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|
| H | B | H | B | H | B |
11..1串最后一个字符,也就是从右到左的第一个字符,必定是B,因为它识别错了,下一个位置应该是人类,因为有前提:0 next = Human,而只有机器人才会识别错误。然后逐渐交替,即B H B H B … …。
实际做题的时候,大概感受一下输入样例是怎么得到输出的,然后直接下手写了。
#include <bits/stdc++.h>
using namespace std;
#define LL long long
#define ULL unsigned long longconst LL mod_1=1e9+7;
const LL mod_2=998244353;const double eps_1=1e-5;
const double eps_2=1e-10;const int maxn=2e5+10;string str;int main()
{int T, n, i, result, cnt;cin>>T;while (T--){cin>>n>>str;result = 0;n--;for (i=0; i<n; i++){cnt = 0;while (i<n && str[i]=='1'){i++;cnt++;}result += (cnt+1)/2;}cout << result << endl;}return 0;
}B
看榜单,这么多人做对,而且时间比较短,猜测是比较短代码的题目。
我是稍微想了B没思路,然后先做了C(159分时AC),再折回来做B。那时候时间就很紧张,剩下20分钟。
然后静下心,把这个代码写了。还遇到1e6写成1e5的问题,还有多组测试样例下数组的问题。反正我就猜测有什么问题,毕竟是最后1分钟,把有可能发生错误的都试着改一下然后提交,甚至i-K也试着改成i-K-1和i-K+1提交一下。运气好,AC了。同时,感觉最近很多场线上比赛压轴提交代码AC,很爽!
因为是\(10^{6}\)复杂度,所以可以处理的算法不多,我想过的有DP,ST算法,感觉时间、空间都挺超的,还有尺取法,等等。我一开始想的,就是贪心,然后逐渐演化而成。
相邻的两个k倍数段(第k * j个段和第k * (j + 1)个段),至少要间隔k个数,然后贪心不了。后来想了一下,哦哦,其实对于某个数(位置为P)作为第k * (j + 1)个段的开头,它就可以以位置1 ~ P-K的任意一个数作为第k * j个段的结尾。记录位置为1 ~ P作为第k * j个段的结尾时的前缀权值之和,然后取它们的最大值:\(\max_{i=1}^{P}(PreSum_{i})\)。每次P位置+1时可以O(1)处理。注意哈,我说的前缀权值PreSum不是前缀和,而是k倍数段中的数的数值之和。
对于第k * j个段,若当前P位置处于这个段,那么P+1位置可以选择添加\(a_{P + 1}\)这个数字,同时这个数仍然处于第k * j个段,仍然可以继续拓展。
关键代码:
start[i] = a[i];value = max(value, start[i-K]);start[i] = max(start[i], start[i-1] + a[i]);start[i] = max(start[i], value + a[i]);
代码细节:
- \(10^{6}\)
- 数组每次的初始化(不然WA)
K=1无法分割段时的特殊处理(赛后再次测试得知,它是要单独处理的,否则WA)
#include <bits/stdc++.h>
using namespace std;
#define LL long long
#define ULL unsigned long longconst LL mod_1=1e9+7;
const LL mod_2=998244353;const double eps_1=1e-5;
const double eps_2=1e-10;const int maxn=1e6+10;LL a[maxn], start[maxn];int main()
{LL T,n,K, sum, i, value;memset(start, 0, sizeof(start));scanf("%lld", &T);while (T--){scanf("%lld%lld", &n, &K);for (i=1;i<=n;i++)scanf("%lld", &a[i]);for (i=1;i<=n;i++)start[i] = 0;value = 0;for (i=1;i<=n;i++){if (i<K)continue;start[i] = a[i];value = max(value, start[i-K]);start[i] = max(start[i], start[i-1] + a[i]);start[i] = max(start[i], value + a[i]);//start[1]~start[i-K]}if (K==1){sum = 0;for (i=1;i<=n;i++)sum += a[i];printf("%lld\n", sum);continue;}sum = 0;for (i=K;i<=n;i++)sum = max(sum, start[i]);printf("%lld\n", sum);}return 0;
}
C
看到这道题,我感受到了可能和这道题有点像,2018 “百度之星”程序设计大赛 - 初赛(A)度度熊学队列,我那时的解法,这道题用list数据结构,把编号为 v 的队列接在编号为 u 的队列的最后面,可以做到O(1)。实际上这道题的数据结构不适用这道题哈。
求\(p_{k}\)的数值,只考虑\(k\)这个位置的变化,那么就要从后往前看。比如1->3->2->4,1这个位置,从后往前看(反过来看),swap(1,3),swap(3,2),swap(2,4),最后是一开始的a[4]的数值在1这个位置。感觉遇到过这种这类的题不少次。
然后问题来了,swap(X,Y),就是当前处于X的数和处于Y的数交换位置。一个集合和一个集合交换位置,我想到的是像set、list、vector这类的数据结构,都可以做到O(1)处理。
然后,就是记录和获取work(L,R,K)的数值。
实际上可能有很多个操作都在同一个位置,但是统一处理降低了复杂度。否则,比如位置1的数值经历了m次修改,n个询问都是问这个位置1,复杂度就是\(O(n*m)\)了。
同时,有些数据结构,无法获取R->L,当到达位置L时,要获取结果然后结束(处理刚好完成后,从某个数据结构中删除)。所以,选择的数据结构需要有排序 / Top的功能。
实际操作中:
set,记录(L, Qth)。Qth是第Qth个查询。L就是题目中的L,(L,R) range的L。vector,记录反过来(从大到小),作为开始的R,有哪些(L,R)对是从某个特定的R开始的。R就是题目中的R,(L,R) range的R。R从大从小遍历。R从大从小遍历,处理这个特定的R的若干序列(K,L,Qth),(L,Qth)加入set[K]中。- 你并不知道对于特定的
(L,R,K),当L处理完后,它在哪个set中。因为set有n个(\(n \leq 10^6\)),你总不能依次遍历n个set吧寻找吧。一个巧妙的处理点,对于已经在处理第I个操作,在swap(set[ a[i] ], set[ b[i] ])之前,对于第a[i]和b[i]个set,可以把之前已经处理完的对删除(erase)了。具体就看哪些对的L值大于现在的I。因为set是自动排序的数据结构,所以这些要处理的(L,Qth)实际上就在set的最后面几个。
代码实际上不长哈,就是有点耗脑。
因为很久没写set这类reverse的代码了,写起来很难受,这个地方卡了很长时间。删除一个元素的时候,指针也会发生变化。比如rbegin,erase(it),++it,等等,反正就是很容易写错。这是用文心一言(ChatGPT更好哈)跑"set删除一个元素,它的next指针发生变化"生成的结果。你需要先记录next指针,再删除哈,或者每次删除最大的元素并循环。我写成it = --st[j].end(),让我有点难崩,应该有其它的写法吧,也可以用auto。
在 C++ 的 std::set 容器中,元素的存储和访问方式与链表(如单链表或双链表)有很大的不同。std::set 是一种基于红黑树(一种自平衡二叉查找树)实现的关联容器。因此,std::set 中的元素不是通过指针链接在一起的,而是通过节点在红黑树中的位置关系来组织。当你从 std::set 中删除一个元素时,以下几点需要注意:元素指针的变化:在 std::set 中,你通常不会直接操作元素的指针(如 next 指针),因为 std::set 的内部实现是基于节点的,而这些节点之间的链接(父节点、左子节点、右子节点)是由红黑树的性质来维护的。红黑树的调整:当你删除一个元素时,红黑树需要进行一系列旋转和重新着色操作,以保持其平衡性和查找效率。这些操作会改变树的结构,但你不会直接看到或操作这些“指针”(即节点之间的链接)。
调试的时候,不知道为什么,我的VSCode一直爆炸,每次调试后,都得关闭重新打开。我怀疑是set的问题。就像,之前CodeBlocks跑什么发生错误后(比如段错误),这个软件就得出点奇怪的问题,需要重新关闭打开才能调教好。太难受啦!我是第一个遇到这个问题哈,我用VSCode也是因为它的代码自动补全(这场基本没有看到)和CPH插件(也没太多用到,但稍微有点用)。
#include <bits/stdc++.h>
using namespace std;
#define LL long long
#define ULL unsigned long longconst LL mod_1=1e9+7;
const LL mod_2=998244353;const double eps_1=1e-5;
const double eps_2=1e-10;const int maxn=1e6+10;typedef pair<int, pair<int, int> > par;
vector<par> vec[maxn];
set<pair<int, int> > st[maxn];
set<pair<int, int> >::iterator it;int result[maxn], a[maxn], b[maxn];
int n, m, q, L, R, K, x, y, z, i;void handle(int j)
{if (st[j].empty())return;while (!st[j].empty()){it = --st[j].end();if (it->first > i){result[it->second] = j;st[j].erase(it);}elsereturn;}
}int main()
{cin>>n>>m>>q;for (i=1;i<=m;i++)scanf("%d%d", &a[i], &b[i]);for (i=1;i<=q;i++){scanf("%d%d%d", &L, &R, &K);vec[R].push_back(make_pair(K,make_pair(L, i)));}for (i=m;i>=1;i--) //L/R range{for (int j : {a[i], b[i]})handle(j);for (auto temp : vec[i]){x = temp.first;y = temp.second.first;z = temp.second.second;st[x].insert(make_pair(y, z)); //L i}swap(st[ a[i] ], st[ b[i] ]);}i = 0;for (int j = 1; j<=n; j++) // value rangehandle(j);for (i=1;i<=q;i++)printf("%d\n", result[i]);return 0;
}P.S. 我觉得好的题的定义
我感觉这种很考思维逻辑,数据结构的题(我指的是前3题,后面没看),ChatGPT很难生成正确的答案。其实AtCoder、CodeForces估计一直有这方面的尝试和讨论,出点很有创新的题目,而不是模板题。有一次我看到AtCoder歪榜,你懂的字数字数。
我的个人感悟巴拉巴拉
实力尚还在吧,多年后,一些数据结构有新的感悟,但是一些STL函数使用的确生疏了,写得也相对比较慢,但是代码错误基本会比较少。虽然一开始有点事,后面环境也不是太安静,但是他们都努力降低声音了,set也很久没写了很生疏,但是最后20分钟赶上了第三题的ac,最后两分钟赶上了第二题的ac。看了一下榜,三题AC倒3,这很正常,因为我大大高估了自己做第三题的时间(STL字数字数,太耗时了),第二题最后做的,罚时超大,而且想到的都交了,于是5WA。前100名,187分钟的罚时,大概理想就是10(15) 30 (40) 90(120)吧,实际上挺难的,你还要考虑WA的次数。距离拿衣服还有很远的地步,但是足够了,很开心。话说,拿衣服就不能放宽到200名吗??!!!让兄弟们混件衣服呗!!!感觉参加这次比赛的同学都挺有水平,看它们牛客Ranking和颜色就知道了,普遍ACM银金水平吧。我很多牛客比赛都是乱作的,还有人很菜,然后蓝色,嗯?黑人问号?尊贵的蓝色?嗯???



![[SUCTF 2019]CheckIn](https://img2024.cnblogs.com/blog/3549480/202411/3549480-20241106000904571-983982594.png)