Summary
- Summary
- 标准序列推荐模型
- 其他推荐模型
- FPMC
- DNN(Pooling)
- GRU4Rec(RNN-based)
- GRU4Rec+(RNN-based)
- Caser(CNN-based)
- SASRec(Transformer-based)
- DIN(Transformer-based)
- BERT4Rec(Transformer-based)
- TiSASRec(Transformer-based)
- FMLP-Rec(Transformer-based)
- CLS4Rec(Contrastive Learning based)
- SHAN(长短期)
- ComiRec(多兴趣)
- MKM-SR(多行为)
标准序列推荐模型
| 非深度学习 | Pooling | RNN | CNN | Transformer | 对比学习 |
|---|---|---|---|---|---|
| FPMC(最终得分 = 用户特征+物品特征) | DNN | GRU4Rec(GRU-based) | Caser | SASRec(第一次使用self-attention) | CLS4Rec |
| GRU4Rec+(改进损失函数与负采样) | DIN(attention换成了AU) | ||||
| BERT4Rec(使用Bert-based) | |||||
| TiSASRec(相对时间self-attention) | |||||
| FMLP-Rec(把self-attention换成滤波器) |
其他推荐模型
- 多个attention:SHAN(两层attention,一层表示长期兴趣,一层表示短期兴趣)
- 多个兴趣:ComiRec(使用多头attention提取多个向量,并分别做最近邻检索)
- 多个行为:MKM-SR(多任务训练;item sequence embedding+micro-behavior sequence embedding)
FPMC
-
背景:推荐系统需要同时考虑用户的长期偏好和顺序行为。现有方法要么只考虑一般偏好(MF),要么只考虑顺序模式(MC)。
-
问题:如何在一个统一框架下同时捕捉用户的长期偏好和短期顺序行为
-
方法:
-
输入数据以"basket"(购物篮)形式组织
- 每个时刻t用户可能与多个物品交互
- 同一时刻交互的所有物品构成一个basket
-
预测目标:基于用户ID和当前basket预测下一个时刻的物品
-
最终分数 = 用户-物品交互分数 + 物品-物品转移分数
-
使用S-BPR(Sequential Bayesian Personalized Ranking)损失函数
-
DNN(Pooling)
-
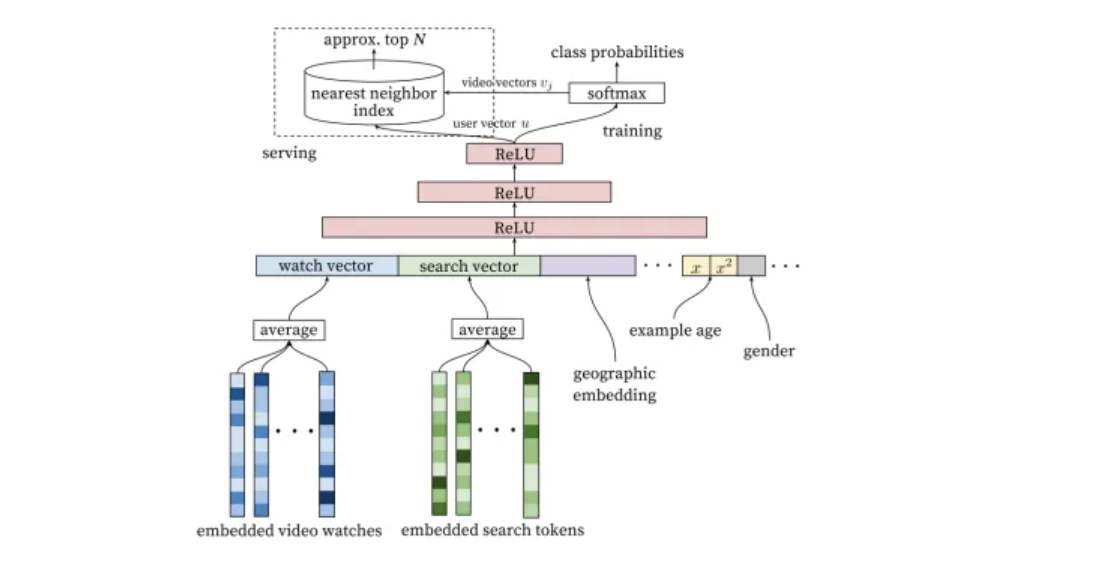
背景与问题:YouTube面临海量用户和视频的推荐挑战。需要处理实时性强、噪声大、稀疏性等问题。需要平衡新内容探索和已有内容
-
解决方案:普通的Pooling模型。Trick:增加一个Example Age,新视频更容易被推荐。将序列的最后一次观看作为label。
GRU4Rec(RNN-based)
-
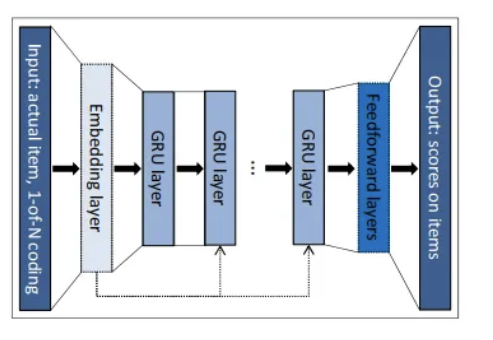
背景:很多场景下只能获取用户的当前会话信息,传统方法难以建模会话内的复杂顺序依赖
-
问题: 如何仅基于会话数据建模用户的即时偏好并做出准确推荐
-
解决方案:引入GRU
GRU4Rec+(RNN-based)
-
背景/问题:如何改进GRU4Rec
-
解决方案:改进GRU4Rec+的负采样策略与损失函数策略。
负采样:不仅使用mini-batch负采样,还同时使用从某个预定义分布中采样得到的物品作为负样本。
损失函数:TOP1-max和BPR-max损失
Caser(CNN-based)
-
背景:Top-N序列推荐的核心是将每个用户建模为过去交互商品的序列,目标是预测用户在"近期未来"可能交互的前N个排序商品。在这个过程中,交互顺序体现出重要的序列模式 - 序列中较近期的商品对下一个商品的影响更大。
-
问题:需要一个模型能够反映出近期商品具有更大影响力的特点,同时考虑用户的一般偏好和序列模式
-
解决方案:将序列看作"图像",引入CNN来处理序列。
flowchart TDsubgraph InputU[用户ID]S[近期L个交互物品序列]endsubgraph EmbeddingE[Embedding Layer]M[L×d Embedding矩阵]endsubgraph CNNdirection TBsubgraph "水平卷积 (横向滑动)"H[水平卷积核: h×d]HP[水平池化]endsubgraph "垂直卷积 (纵向滑动)"V[垂直卷积核: L×1]endendsubgraph FusionC[特征拼接]FC[全连接层]endsubgraph OutputP[预测层]S2[下T个物品的预测分数]endU --> ES --> EE --> MM --> HM --> VH --> HPHP --> CV --> CC --> FCU --> FCFC --> PP --> S2style Input fill:#f9f,stroke:#333style Embedding fill:#bbf,stroke:#333style CNN fill:#bfb,stroke:#333style Fusion fill:#fbb,stroke:#333style Output fill:#ff9,stroke:#333
SASRec(Transformer-based)
-
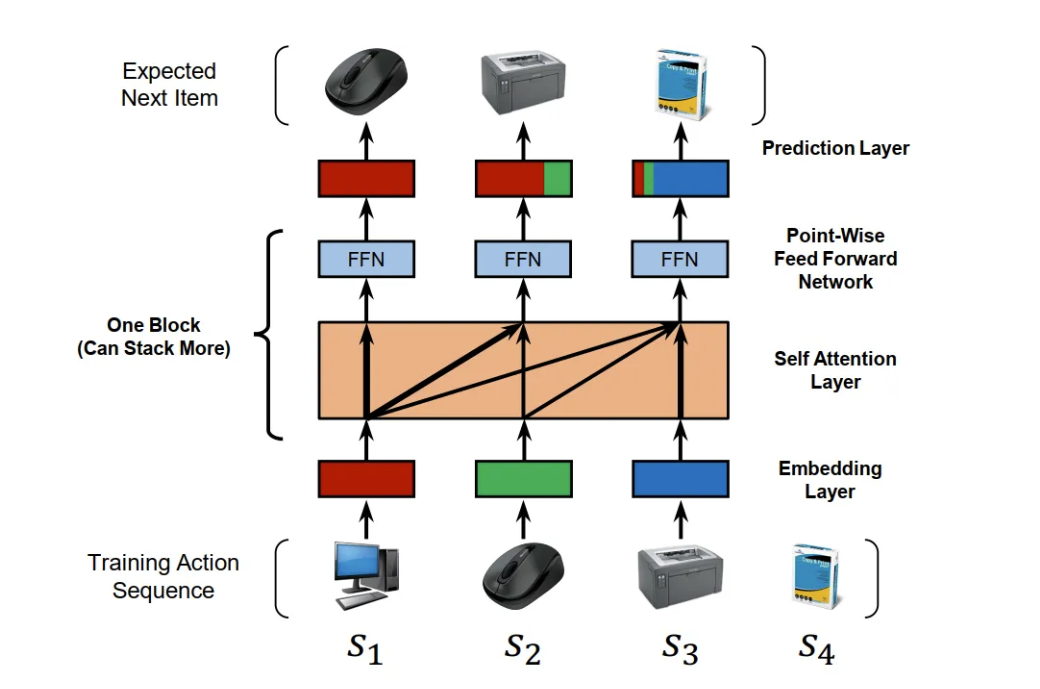
背景:MC方法表达能力有限,RNN方法需要大量数据
-
问题:如何设计一个既能捕获长期依赖又计算高效的序列推荐模型
-
解决方案:引入Transformer Encoder
DIN(Transformer-based)
-
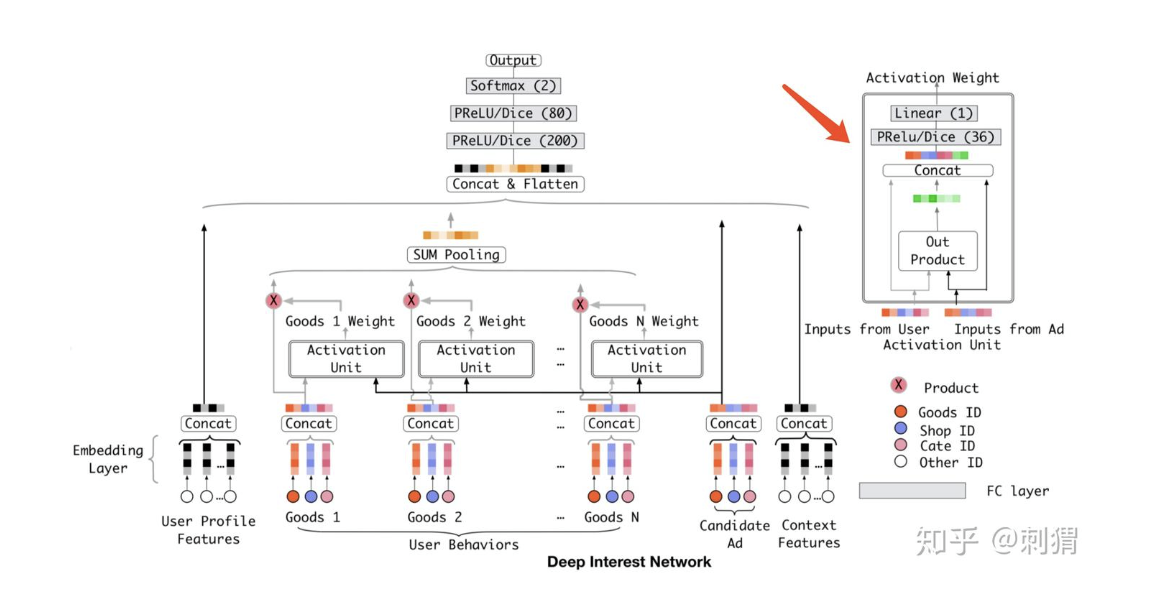
背景与问题:在电商推荐场景中,用户兴趣是多样化的,但现有的Embedding&MLP方法使用固定长度的向量表示用户兴趣,难以完整表达用户多样的兴趣。固定长度向量的表达能力有限,若要增加表达能力需要增大维度,会导致参数量剧增和过拟合问题
-
解决方案:引入局部激活单元(local activation unit),以及两个Trick:MAR降低计算复杂度,Dice激活函数
BERT4Rec(Transformer-based)
-
背景:大多数序列推荐模型都是单向的(从左到右)
-
问题:单向模型限制了对用户行为序列的建模能力
-
解决方案:和BERT类似
- 引入双向自注意力机制
- 采用Cloze task训练策略
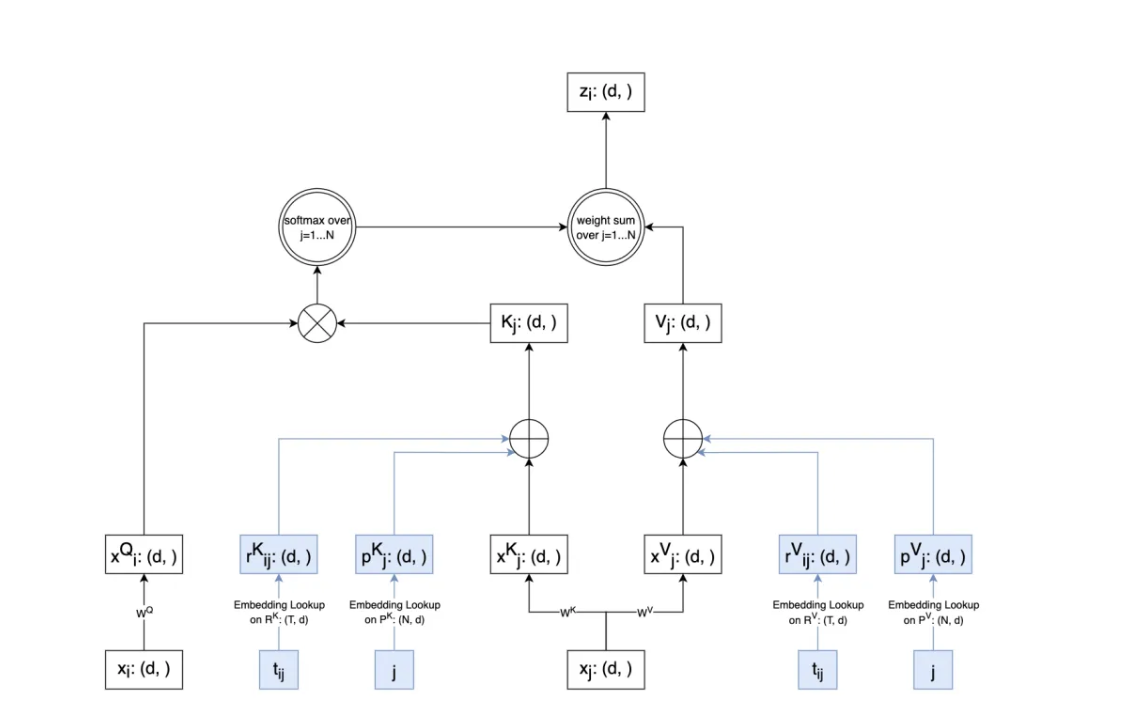
TiSASRec(Transformer-based)
-
背景:现有序列推荐模型只考虑物品的顺序,忽略了时间间隔信息
-
问题:如何将时间间隔信息纳入序列推荐模型中
-
解决方案:在计算attention时,向Key和Value向量中加入位置信息和时间间隔信息。
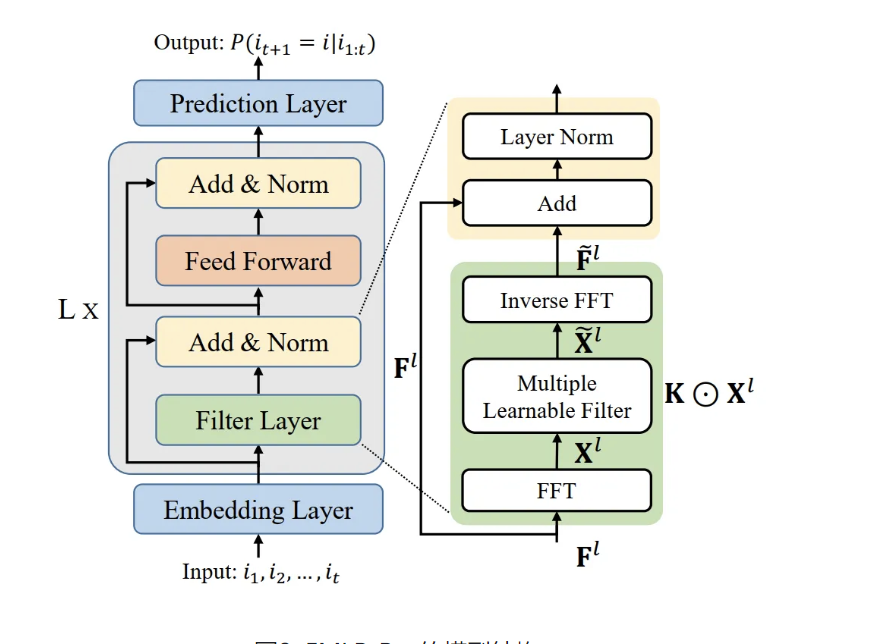
FMLP-Rec(Transformer-based)
-
背景:基于RNN,CNN,Transformer的模型容易过拟合
-
问题:如何简化Transformer架构,减少参数量
-
解决方案:将attention层替换为filter层,计算复杂度从\(O(n^2)\)降到\(O(n\log n)\)
CLS4Rec(Contrastive Learning based)
-
背景:现有方法在处理稀疏数据和噪声数据时表现不佳
-
问题:如何设计合适的数据增强方法来构建对比学习任务
-
解决方法:使用三种数据增强方式,判断哪些变换后的序列属于同一用户。
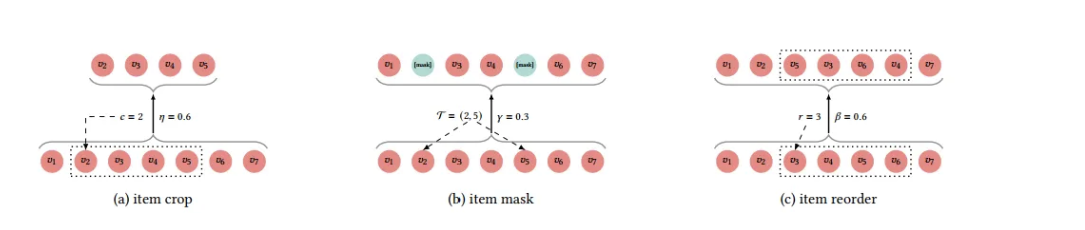
用多任务训练,损失函数=对比损失+预测损失
SHAN(长短期)
-
背景与问题:传统方法通常是将用户的总体兴趣(general taste)和近期需求(recent demand)结合起来进行推荐。但是,用户的长期偏好会随时间不断演变,并且交互建模方式过于简单。
-
解决方案:引入两个自注意力层。第一注意力层根据历史购买物品表征学习用户长期偏好,而第二注意力层则通过用户长期和短期偏好的耦合输出最终用户表征。
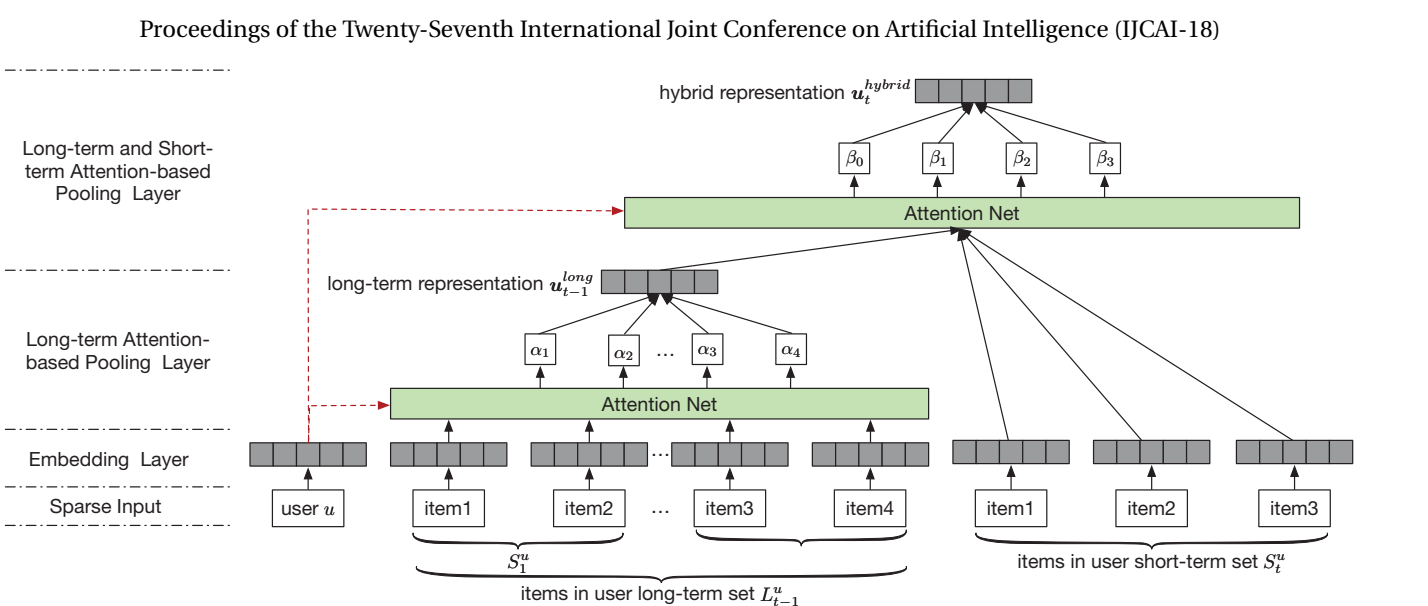
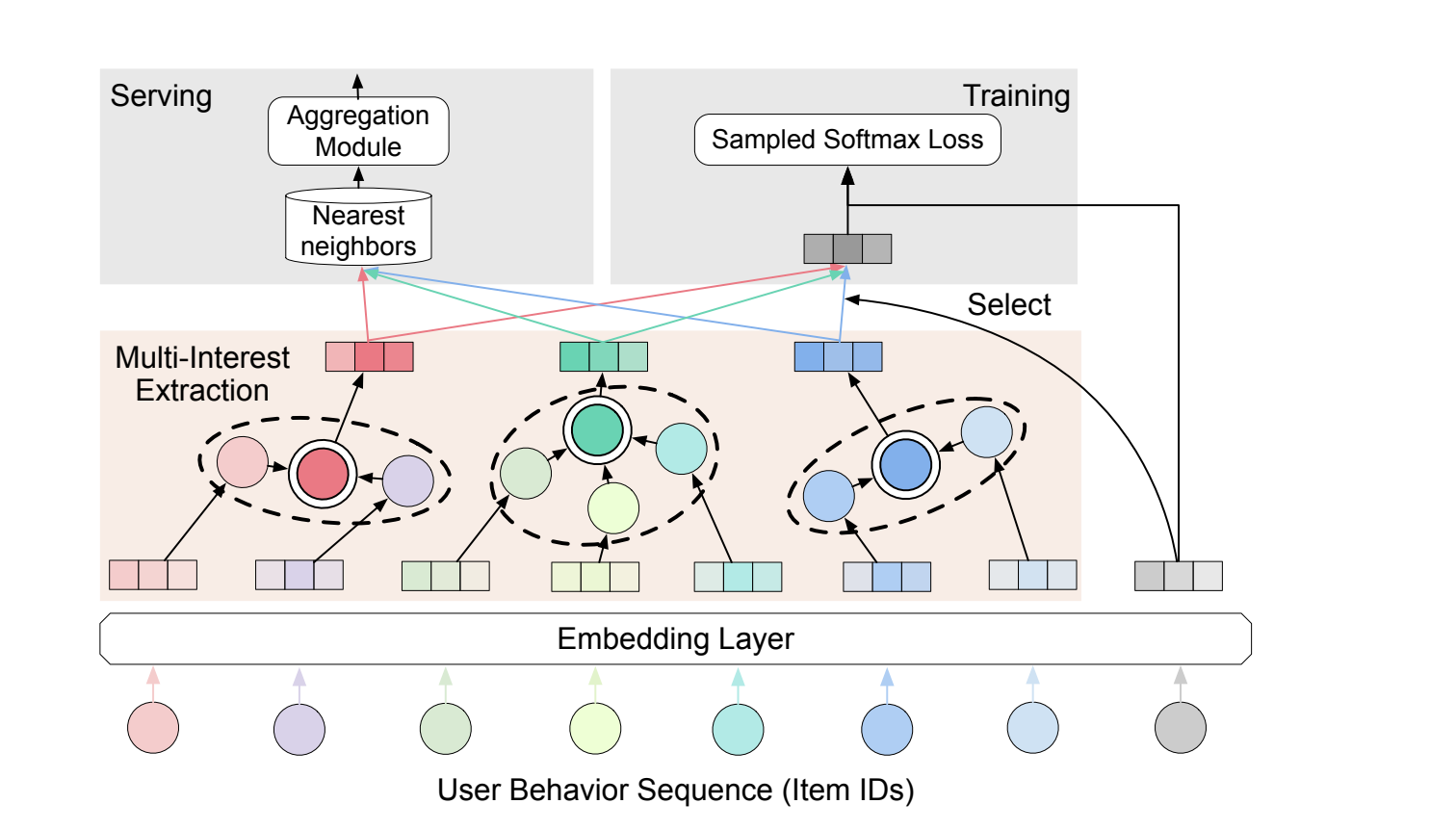
ComiRec(多兴趣)
-
背景:用户在推荐系统中的兴趣通常是多样的,但现有的序列推荐模型往往只用一个统一的用户向量来表示用户兴趣。
-
问题:如何更好地捕捉用户的多样化兴趣,提供更准确的推荐。
-
解决方案:提出了一个可控的多兴趣推荐框架,包含两个关键模块:
-
多兴趣提取模块:通过动态路由或多头self-attention从用户行为序列中提取多个兴趣表示。
-
聚合模块:通过可控因子平衡推荐的准确性和多样性。
-
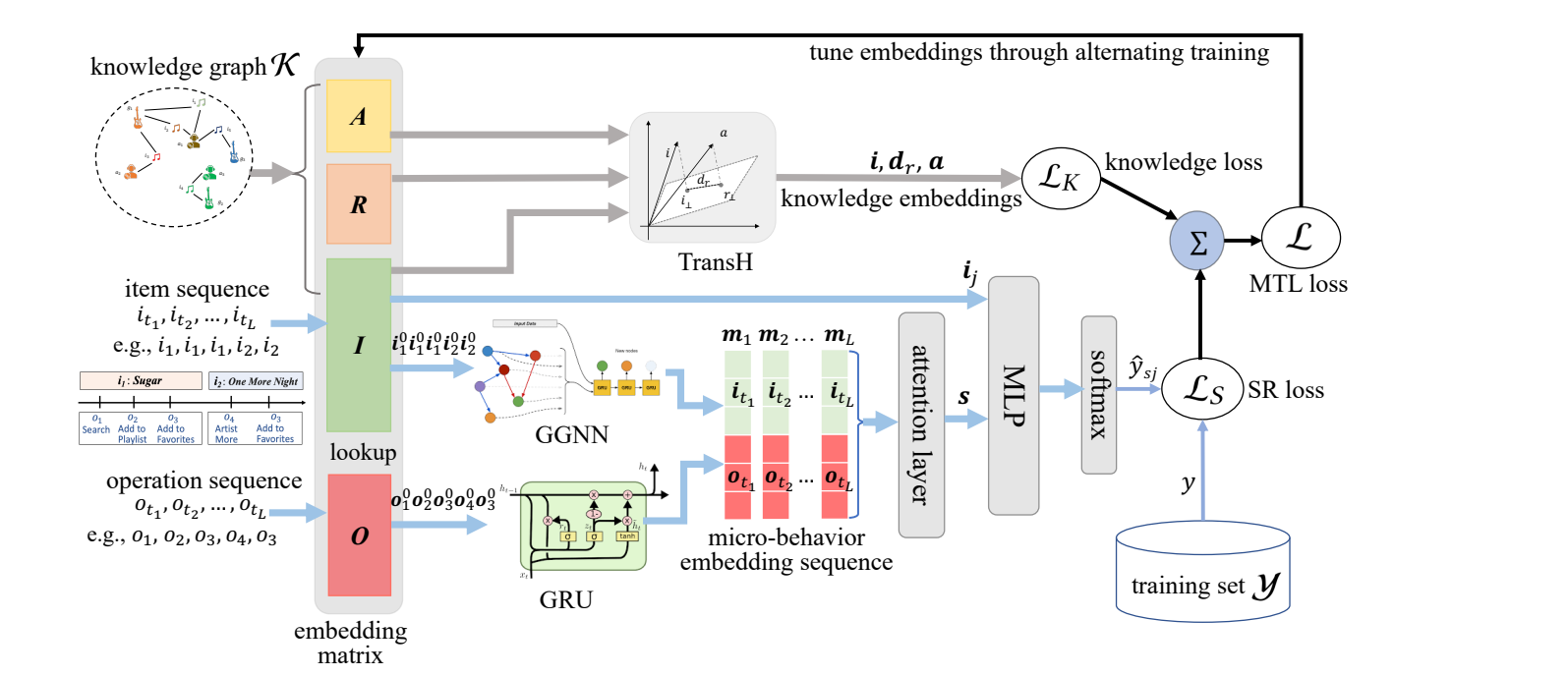
MKM-SR(多行为)
-
背景与问题:只关注会话中连续商品之间的转换模式,忽略了用户的微观行为。此外,商品属性可以提供额外信息来建模商品间的转换模式。
-
解决方案:将会话建模为商品-操作对的序列。此外,采用了多任务学习,主任务是推荐,辅助任务是knowledge embedding learning。