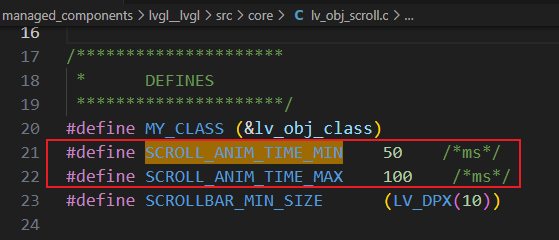
图像分类
resNet --基于CNN的网络
目标检测
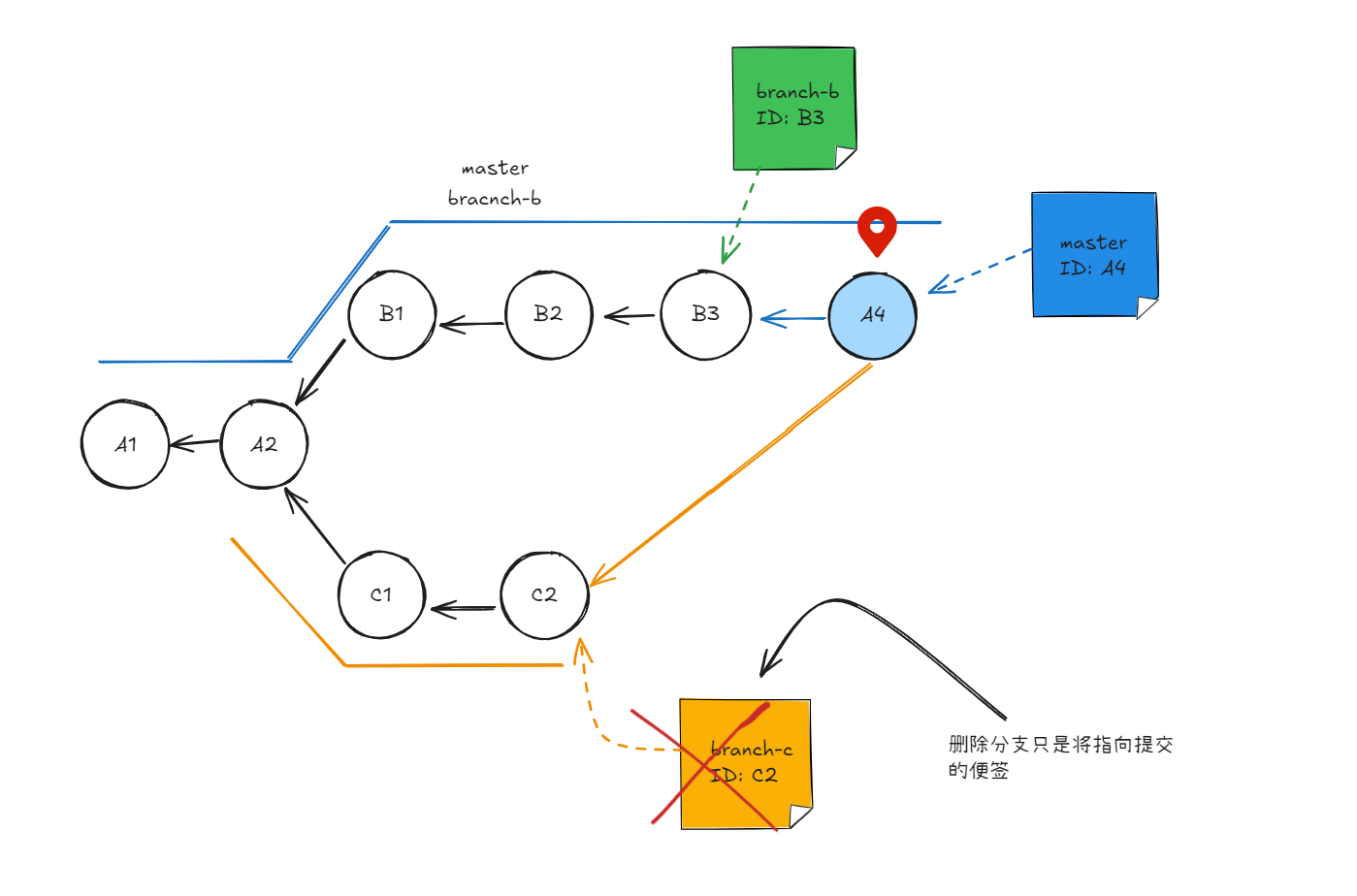
目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置真实边界框(ground-truth bounding box)锚框(anchor box 多尺度锚框交并比(IoU)非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框为图像生成多个锚框,再为这些锚框一一预测类别和偏移量--非极大值抑制预测边界框feature map 特征图(fmap)上生成锚框(anchors)
one-stage和two-stage 二阶段: 第一阶段提取感兴趣的区域,第二阶段进行分类和定位retinanetRetinaNet的主要创新点在于其focal loss,该损失解决了大多数目标检测数据集中存在的类别不平衡问题RetinaNet采用了经典的Backbone+Neck+Head单阶段网络结构,Backbone负责提取图像的特征,Neck负责增强或融合特征(如通过多尺度处理),而Head则根据任务需求生成最终的输出结果(如类别、边界框或掩膜)其中Backbone采用Resnet,Neck采用FPN, 特征金字塔网络(FPN)架构Head部分由分类子网络(class subnet)和框回归子网络(box subnet)组成一阶段检测算法:如YOLO和SSD torchvision/models/detection/ssd.pyhttps://github.com/pytorch/vision/blob/main/torchvision/models/detection/ssd.py
图像分割
图像分割(image segmentation)和实例分割(instance segmentation前景背景分割: 1表示前景,0表示背景语义分割 Semantic实例分割也叫同时检测并分割(simultaneous detection and segmentation全景分割:结合语义分割和实例分割,提供像素级的类别和实例标签,实现全面的场景理解-将背景也作为分类,标签图像(即“mask”或“ground truth”图像)通常是一张灰度图Segmentation Mask(分割掩码) 2023-04-06 Meta AI发布了Segment Anything Model(SAM)
Vit--图像分类
是基于transformer结构的cv网络 一开始就捕捉全局上下文的能力 torchvision/models/vision_transformer.pyViT模型利用Transformer模型在处理上下文语义信息的优势,将图像转换为一种“变种词向量”然后进行处理ViT结构主要包括Patch Embedding、Position Embedding(位置编码)、Transformer Encoder与MLP Head
Transformer在CV领域通用的backboneNLP领域的词嵌入(Word Embedding),ViT采用了(Patch Embedding)
目标检测
DETR(Detection Transformer)用于目标检测和全景分割。这是第一个将Transformer成功整合为检测pipeline中心构建块的目标检测框架。从通用任务和可提示分割两个方向由三个主要部分组成:用于特征提取的CNN后端(ResNet)、transformer编码器-解码器和用于最终检测预测的前馈网络(FFN)
自动驾驶
BEV+Transformer方案可以将静态道路信息与动态道路信息统一到了同一个坐标系下,通过实时感知与转换,在行驶中即可实时生成“活地图”
VLAOpenVLA 模型OCC动态-静态-OCC
多模态
CLIP模型(Contrastive Language-Image Pretraining)
大模型时代
ChatGLM系列、Qwen系列、Llama系列Deepseek
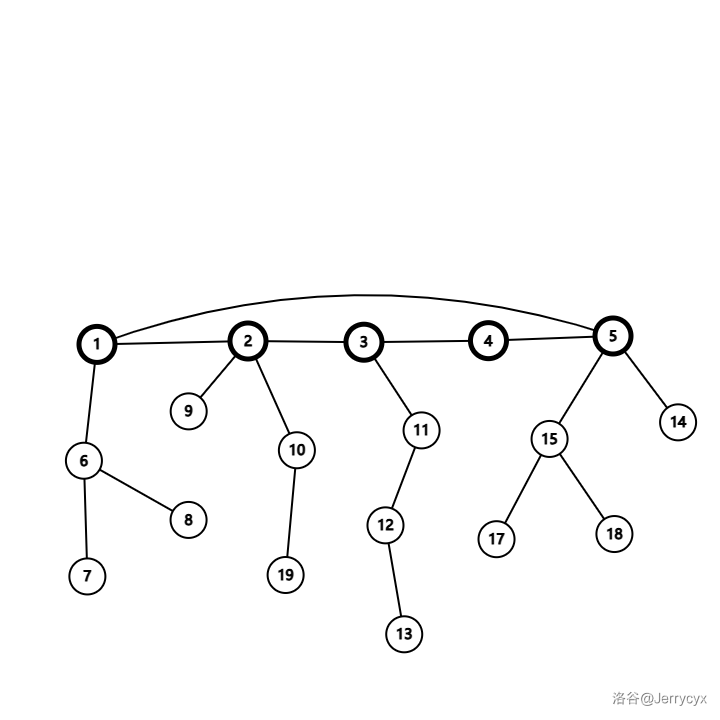



![P1020 [NOIP 1999 提高组] 导弹拦截(dilworth)](https://img2024.cnblogs.com/blog/3599636/202502/3599636-20250213183723947-1236173575.png)