基于CS的学习工作流构建思路
原文作者:Vacodwave 首发于 少数派 留存备用,如有侵权,立即删除。
平时工作中往往会遇到新的知识点,这个时候需要我们快速学习并且进行最佳实践。往往是在真正学习了一段时间之后,才会发现有哪些地方可以优化,这样磨合出来的工作流才是最适合自己的。经过两年工作之余的学习后,我磨合出了以下学习工作流:
底层核心逻辑
一开始我学习新知识时会参考一些博客或者是视频,当我开始敲代码实践时往往会出现一些纰漏和错误,我开始意识到我参考的信息可能是错误的,毕竟发博客的门槛低,因此文章的可信度可能不高,于是我开始查阅一些相关的中文书籍。
中文书籍的确是比较全面且系统地讲解了知识点,但众所周知,技术更迭很迅速,又因为老美在 CS 方面一直都是灯塔,所以一般中文书籍里的内容会滞后于当前最新的知识,导致我跟着中文书籍实践会出现软件版本差异的问题。这时我开始意识到一手信息的重要性,有些中文书籍是翻译英文书籍的,一般翻译一本书也要一两年,这会导致信息传递的延迟,还有就是翻译的过程中信息会有损失。如果一本中文书籍不是翻译的呢,那么它肯定也是参考其他书籍的,参考的过程会带有对英文原著中语言和语义理解的偏差。
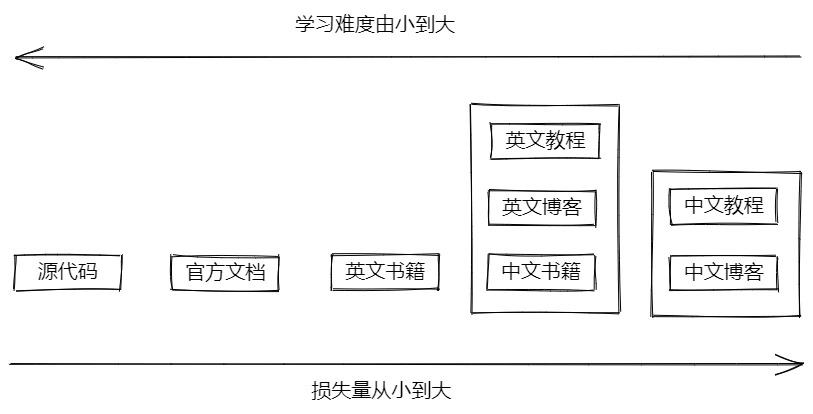
于是我就顺其自然地开始翻阅英文书籍。不得不说,整体英文书籍内容的质量是比中文书籍高的,一个原因是写英文书籍的作者更会写作,他们会用自己的话很详尽地解释一个知识点,而不是像一些中文书籍那样罗列知识点并且理所当然地以为读者能读懂而忽略一些细节的描述,还有一个原因就是知识很注重时效性,英文书籍的内容往往更新一点。后来随着学习的层层深入,以知识的时效性和完整性出发,我发现 源代码 > 官方文档 > 英文书籍 > 英文博客,最后我得出了一张 信息损失图
虽然一手信息很重要,但后面的 N 手信息并非一无是处,往往这 N 手资料里写了作者对源知识的转化——作者对知识基于某种逻辑的梳理(流程图、思维导图等)以及自己的一些理解(对源知识的抽象、类比、延伸到其他知识点),这些转化可以帮助我们理解一些知识,就如同初高中读书时使用的辅导书。 学习的过程中和别人的交流十分重要,这些 N 手信息同时起了和其他作者交流的作用,所以学习一个知识点的过程中不妨参考多个信息源,让自己的理解更加准确。
现实中的学习不会仅围绕一个知识点由浅入深地学习,经常会在学习过程中涉及到其他知识点,比如一些新的专有名词,以及一些自己疑惑的段落。遇到专有名词很好解决,只要去搜索引擎搜索这个名词就好了。而对于那些令自己困惑的段落,我们往往容易不容易察觉那些是问题,甚至有时明知自己看不懂也懒得去查资料,因此学习的过程中要保持思考,勤于提问。
小结
单个知识点多参考源,勤于提问给多个知识点之间建立联系
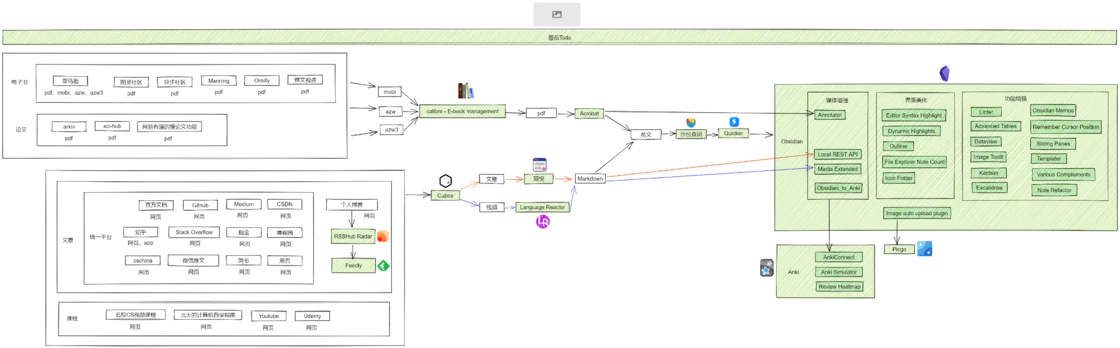
工作流的演化
工作流的骨架围绕 单个知识点多参考源,勤于提问给多个知识点之间建立联系 的底层核心逻辑建立。我们以前写的论文其实就是符合这个底层逻辑的。论文一般会有脚注去解释一些关键字,并且论文末尾会有多个参考的来源,如此一来已经挺严谨了,但是我们平时写笔记时需要更灵活的方式。因为平时写代码习惯在 ide 里跳转代码,所以如果笔记也能像代码那样可以跳转就好了。
现在市面上 双链笔记软件 就可以解决笔记跳转的痛点,像 Roam Research、Logseq、Notion 和 Obsidian。Roam Research 和 Logseq 都是基于大纲结构的笔记软件,而 大纲结构 是劝退我使用这两款软件的原因,一是 大纲结构 适合做思维导图,比如幕布,大纲结构 做笔记容易使文章纵向篇幅太长,二是如果嵌套结构过多会占横向的篇幅。Notion 页面打开慢,弃之。最终我选择了 Obsidian,原因如下:
- Obsidian 基于本地,打开速度快,且可存放很多电子书。我的笔记本是 32g 内存的华硕天选一代,拿来跑 Obsidian 可以快到飞起
- Obsidian 基于 Markdown。这也是一个优势,如果笔记软件写的笔记格式是自家的编码格式,那么不方便其他第三方拓展,也不方便将笔记用其他软件打开,比如 qq 音乐下载歌曲有自己的格式,其他播放器播放不了,这挺恶心人的
- Obsidian 有丰富的插件生态,并且这个生态既大又活跃,即插件数量多,且热门插件的 star 多,开发者会反馈用户 issue,版本会持续迭代。借助这些插件,可以使 Osidian 达到
all in one的效果
Obsidian 的插件使其可以支持 pdf 格式,本身支持 Markdown 格式,而 pdf 不能完美地转换成 Markdown,也就是说使用 Obsidian 可以支持最少两种格式。
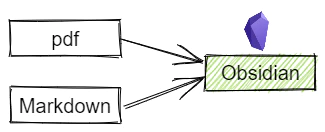
如果想要 all in one,那么可以基于这两个格式出发,将其他格式文件转换为 pdf 或者 Markdown。 现在就面临着两个问题:
- 有什么格式
- 怎么转换为 pdf 或 Markdown
有什么格式
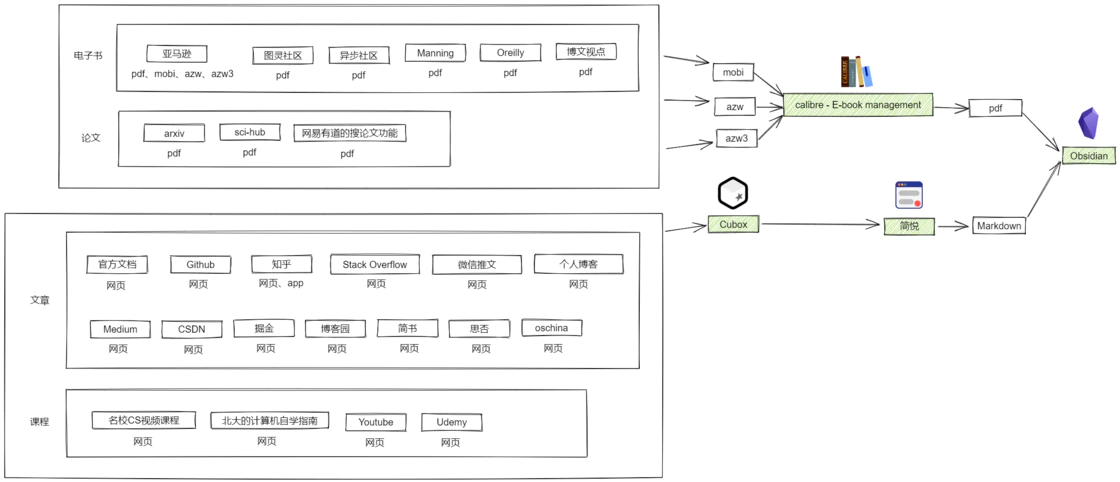
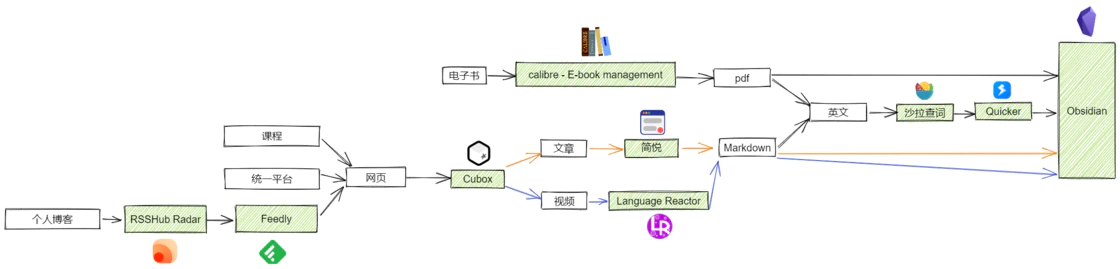
文件格式依托于其展示的平台,所以在看有什么格式之前,可以罗列一下我平时获取信息的来源
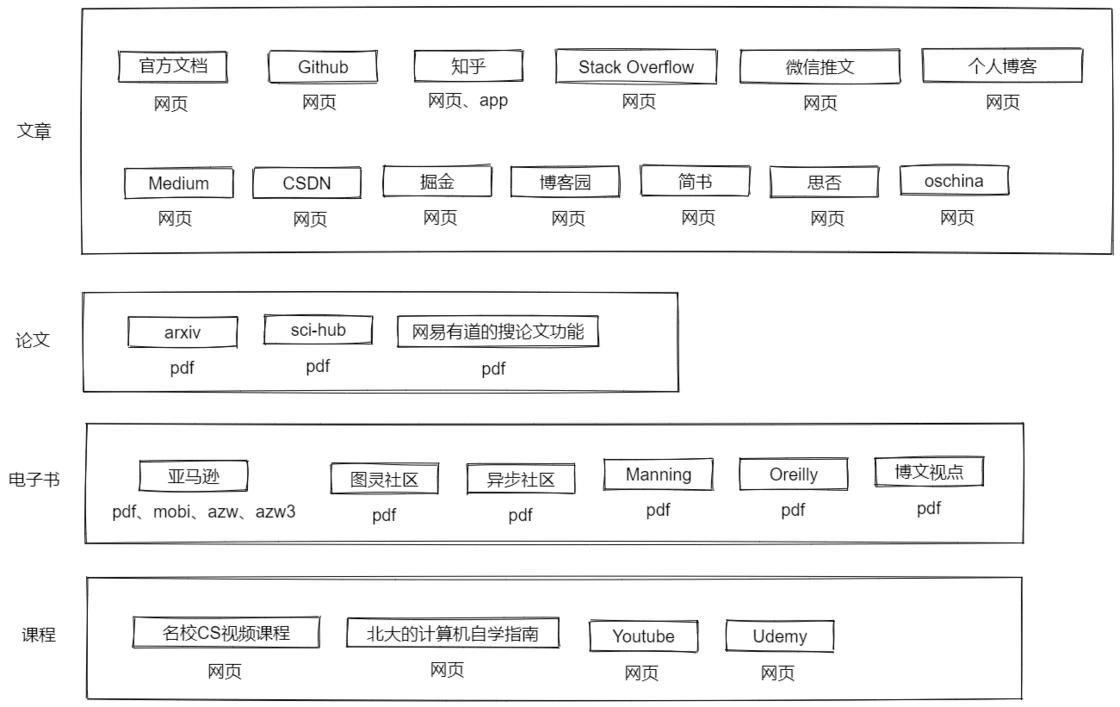
可以看到可能的格式有 网页、pdf 、mobi、azw、azw3
怎么转换为 pdf 或 Markdown
将其他格式电子书转换为 pdf 可以使用 calibre

将网页转换为 Markdown 可以使用一些剪藏软件,这些剪藏软件可以将网页文章转换为多种文本格式文件。常用的剪藏软件有Cubox、简悦,而 Cubox 的剪藏功能做的并不出色,有些文章转化后格式会出现问题,并且不支持将文章剪藏到 Obsidian 中,遂不用 Cubox 来剪藏,但是 Cubox 可以被应用到跨端收藏。使用简悦可以将几乎所有平台的文章很好地剪藏为 Markdown 并且导入到 Obsidian。
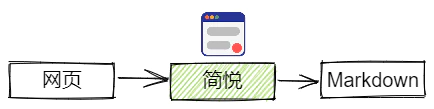
现在可以将文章的最终格式都统一成 Markdown 了
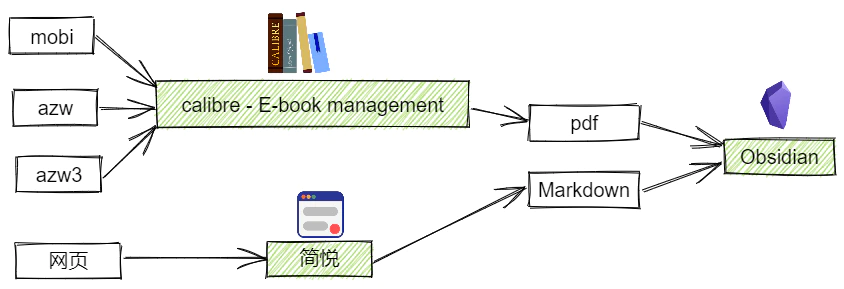
那么可不可以将信息来源的存储都统一到一个平台呢?比如知乎、掘金、CSDN等网站自身就有管理收藏的功能,如果我想使用简悦给这些平台上的文章做剪藏,那么我就需要逐个打开知乎、掘金等网站的收藏夹才能给给里面的文章做剪藏,并且在做完剪藏后我想删除掉收藏记录,我还得到每个平台里删除
如何统一管理信息来源
网页浏览器其实就解决了这个需求,但是网页浏览器不能实现跨端的网页收藏。跨端网页收藏我选用了 Cubox,虽然免费版只能收藏 100 个网页,但其实够用了,还可以在收藏满时督促自己赶紧剪藏掉这些网页,让收藏不吃灰。
观察一下我们收藏的网页,就会发现有很多网站并不像知乎、掘金这类有完整功能的博客平台,更多的是个人建的小站,而这些小站往往没有移动端应用,这样平时刷手机的时候也看不到,这些小站放到浏览器的收藏夹里又容易漏了看,有新文章发布我们也不能第一时间收到通知,这个时候就需要一种叫 RSS 的通信协议。
RSS(英文全称:RDF Site Summary 或 Really Simple Syndication),中文译作简易信息聚合,也称聚合内容,是一种消息来源格式规范,用以聚合多个网站更新的内容并自动通知网站订阅者。然后借助 RSSHub Radar 来快速发现和生成 RSS 订阅源,接着使用 Feedly 来订阅这些 RSS 订阅源。
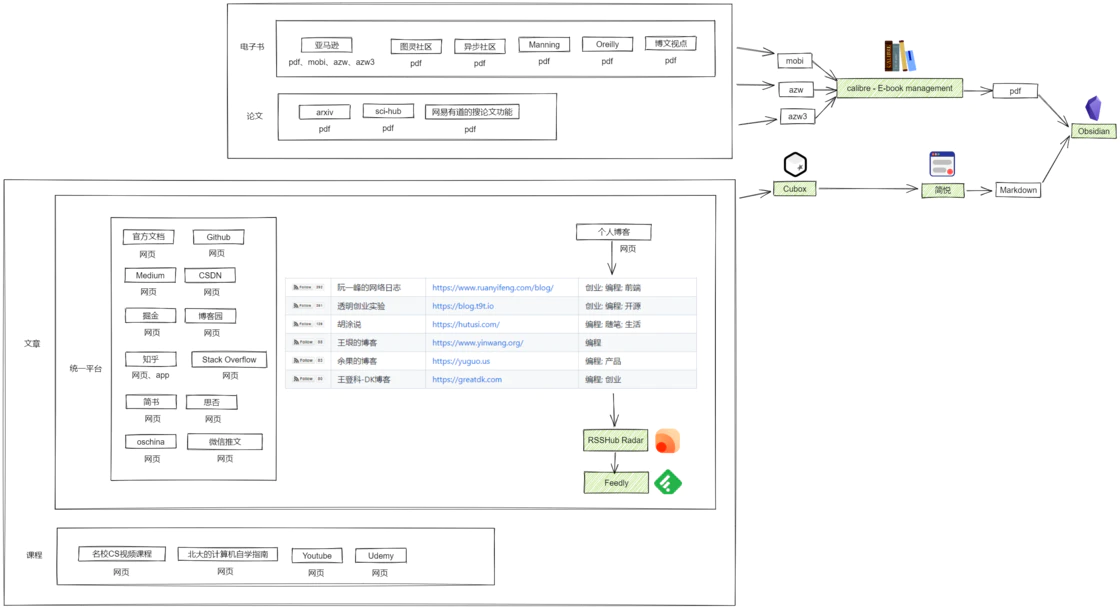
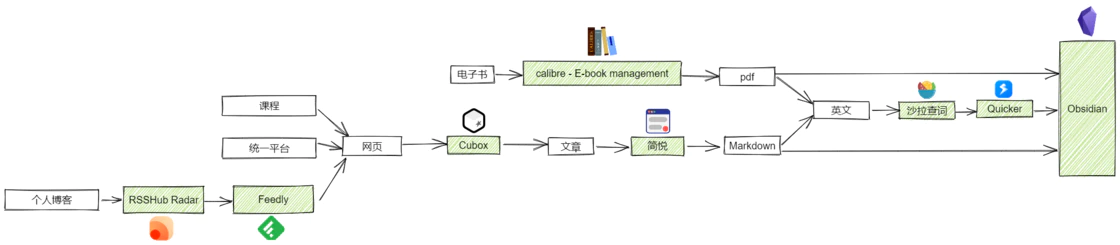
到这里为止,收集信息的流程已经比较完备了。在收集完信息后就得进一步的处理信息,即阅读这些信息,如果是英文信息的话还得搞懂英文的语义,加粗高亮重点句子段落,标记有疑问的地方,发散联想相关的知识点,最后写上自己的总结。那么在这过程中需要使用到什么工具呢?
处理信息
面对英文的资料,我以前是用 有道词典 来划词翻译,遇到句子的话就使用谷歌翻译,遇到大段落时就使用 deepl,久而久之,发现这样看英语文献太慢了,得用三个工具才能满足翻译这一个需求,如果有一个工具能够同时实现对单词、句子和段落的划词翻译就好了。我联想到研究生们应该会经常接触英语文献,于是我就搜 研究生 + 翻译软件,在检索结果里我最终选择了 Quicker + 沙拉查词 这个搭配来进行划词翻译(具体为什么不用知云翻译等其他方式的原因我不记得了)
使用这套组合可以实现在浏览器外的其他软件内进行划词翻译,并且支持单词、句子和段落的翻译,以及每次的翻译会有多个翻译平台的结果。btw,如果查单词时不着急的话,可以顺便看看 科林斯高阶 的翻译,这个词典的优点就是会用英文去解释英文,可以提供多个上下文帮助你理解,对于学习英文单词也有帮助,因为用英文解释英文才更接近英语的思维
处理完文本类的信息后,我们还得思考一下怎么处理多媒体类的信息。此处的多媒体我特指英文视频,因为我没有用播客或录音学习的习惯,而且我已经不看中文教程了(像极客时间这种也挺多干货的,我大学的时候也都是看中文的,像慕课网、中国大学MOOC等等)。用视频学习还是挺频繁的,比如国外名校公开课都是以视频的形式,如果能对视频进行做笔记会不会有帮助呢?不知道大家有没这样的想法,就是如果能把老师上课讲的内容转换成文本就好了,然后再适当配上图片,如果是涉及到具体操作的就保留拍摄了操作过程的动图或视频,对上课过程的文本化可以提高学习效率,因为平时学习时我们看书的速度往往会比老师讲课的速度快。刚好 Language Reactor 这个软件可以将油管和网飞内视频的字幕导出来,同时附上中文翻译
我们可以把 Language Reactor 导出的字幕复制到 Obsidian 里面作为文章来读。除了出于学习的需求,也可以在平时看油管的视频时打开这个插件,这个插件可以同时显示中英文字幕,并且可以单击选中英文字幕中你认为生僻的单词后显示单词释义。
在我浏览 Obsidian 的插件市场时,我发现了一个叫 Media Extended 的插件,这个插件可以在你的笔记里添加跳转到视频指定时间进度的链接,相当于把你的笔记和视频连接起来了!这刚好可以和我上文提到的生成视频中英文字幕搭配起来,即每一句字幕对应一个时间,并且能根据时间点跳转到视频的指定进度,如此一来如果需要在文章中展示记录了操作过程的视频的话,就不需要自己去截取对应的视频片段,而是直接在文章内就能跳转!
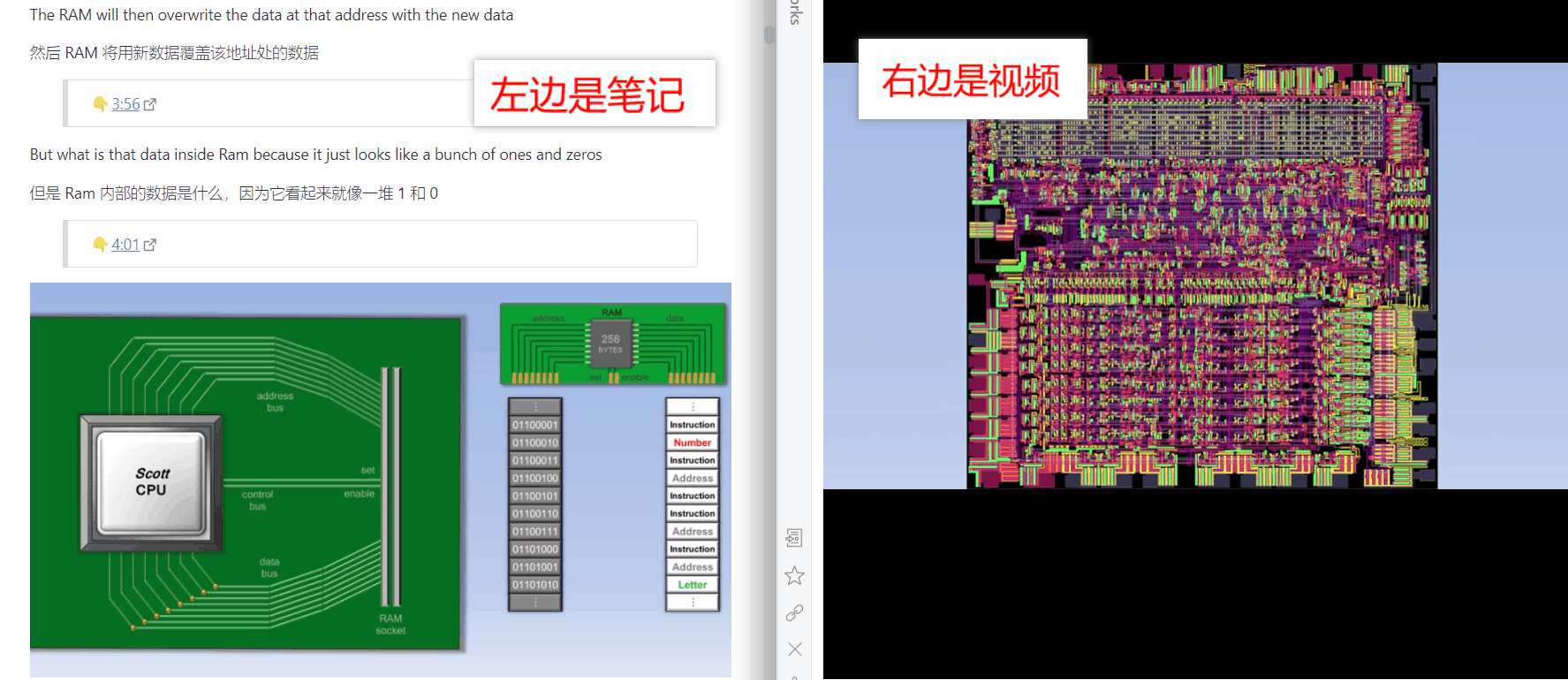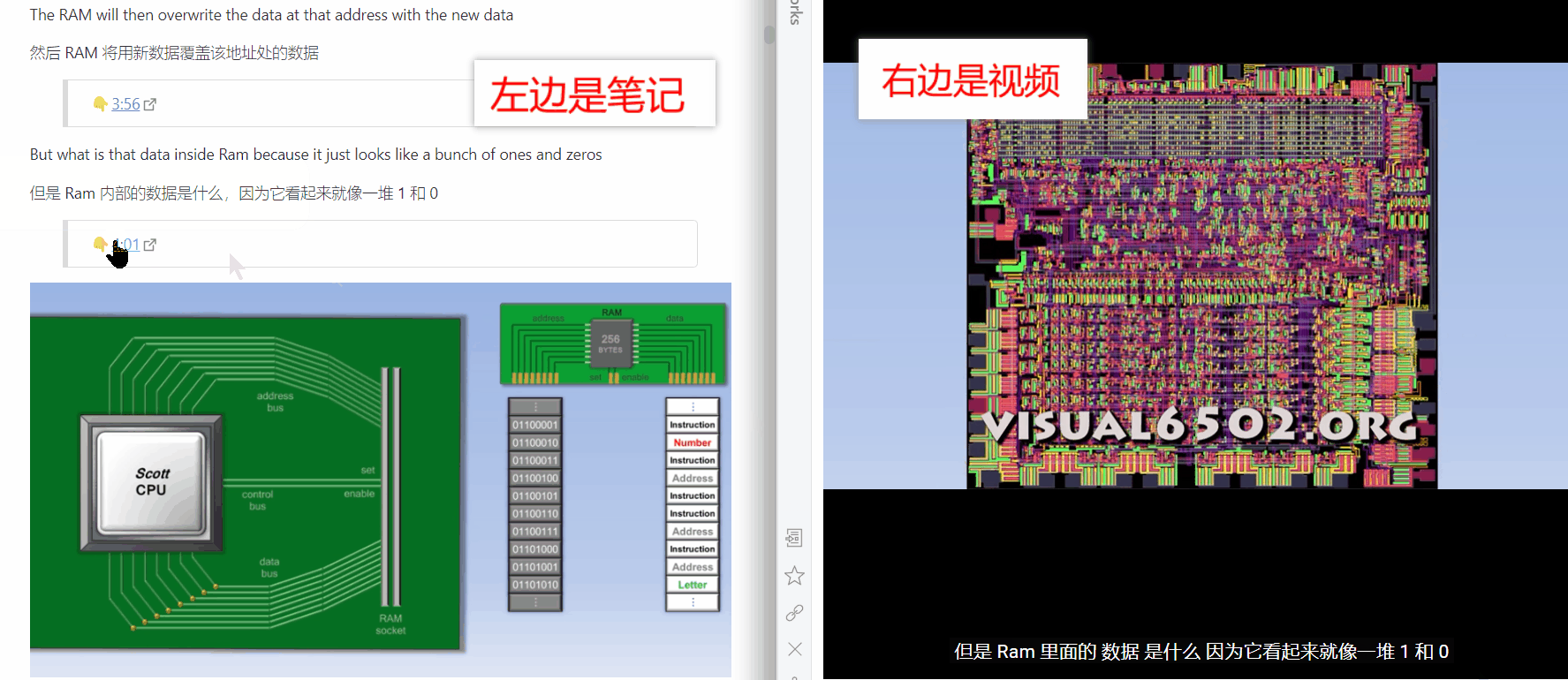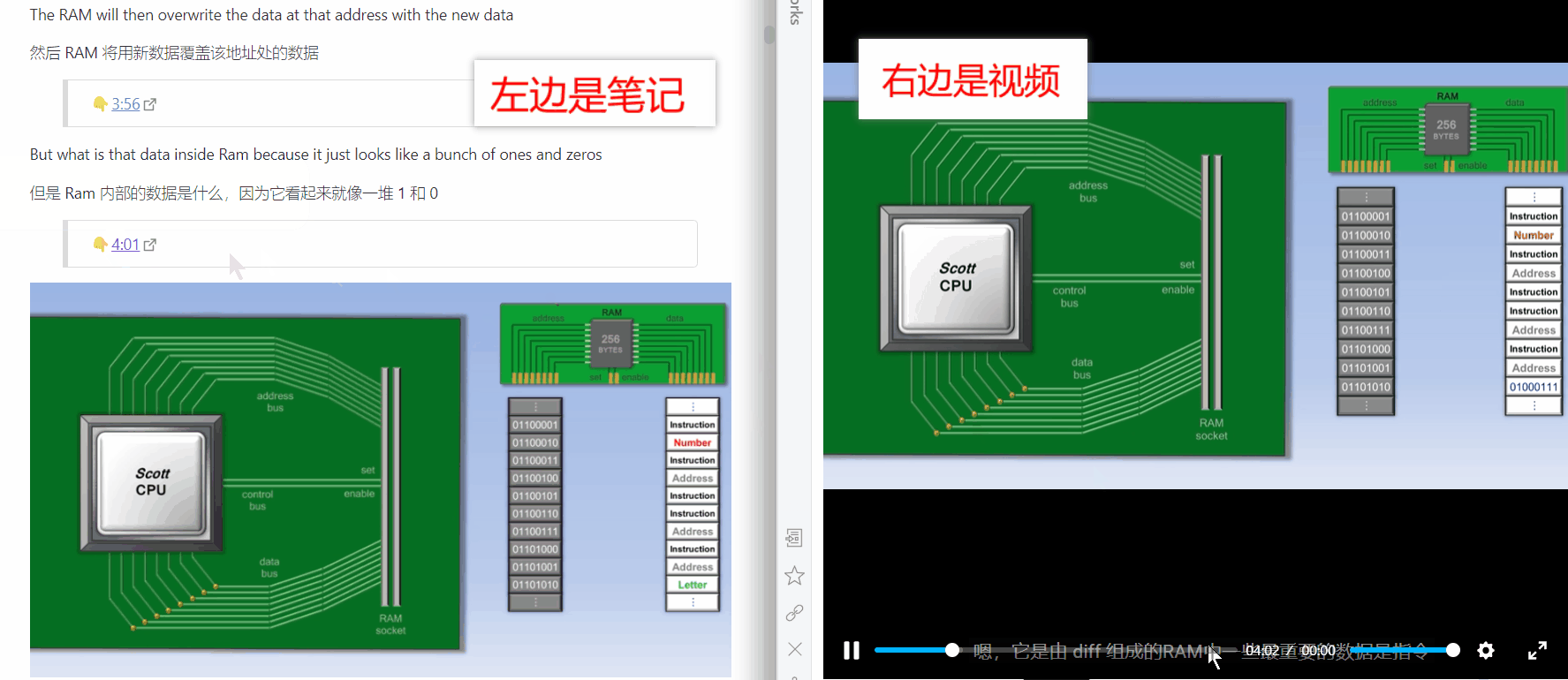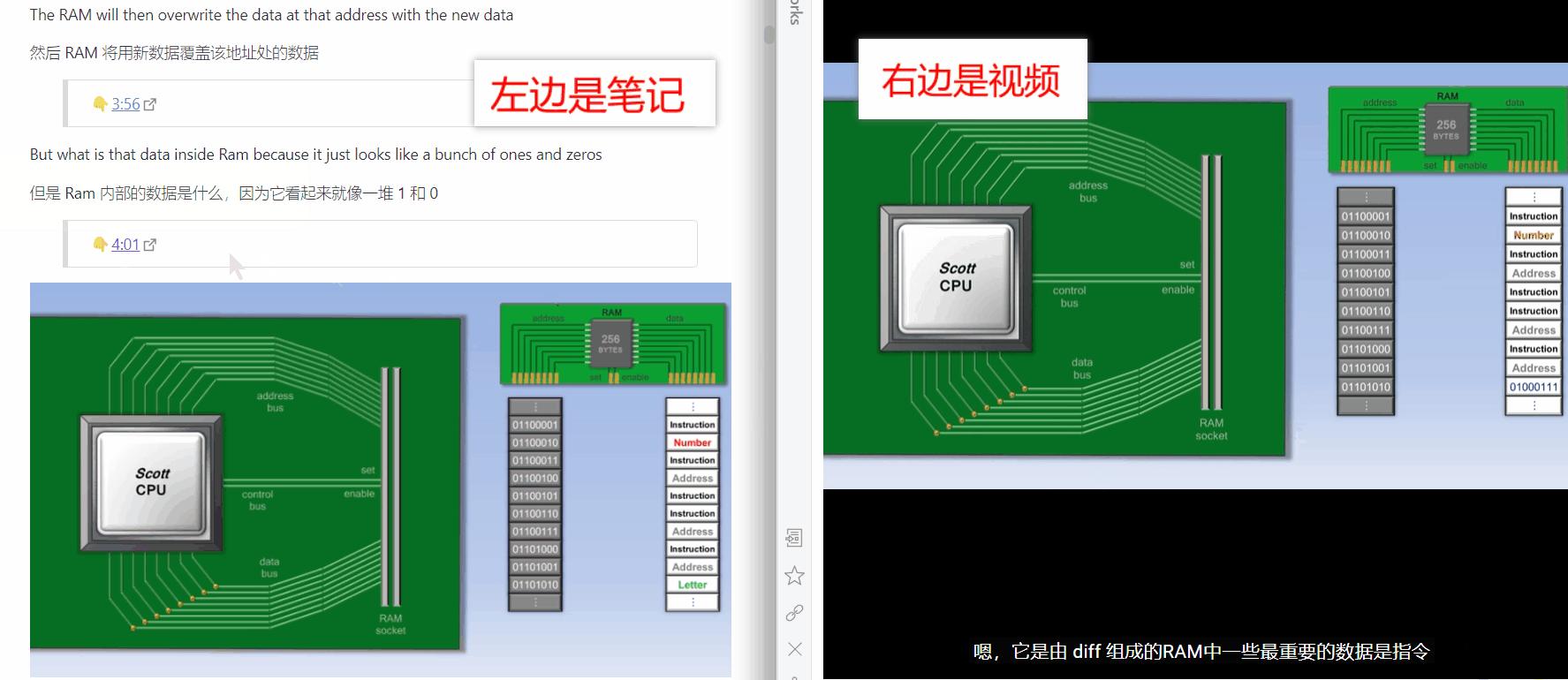
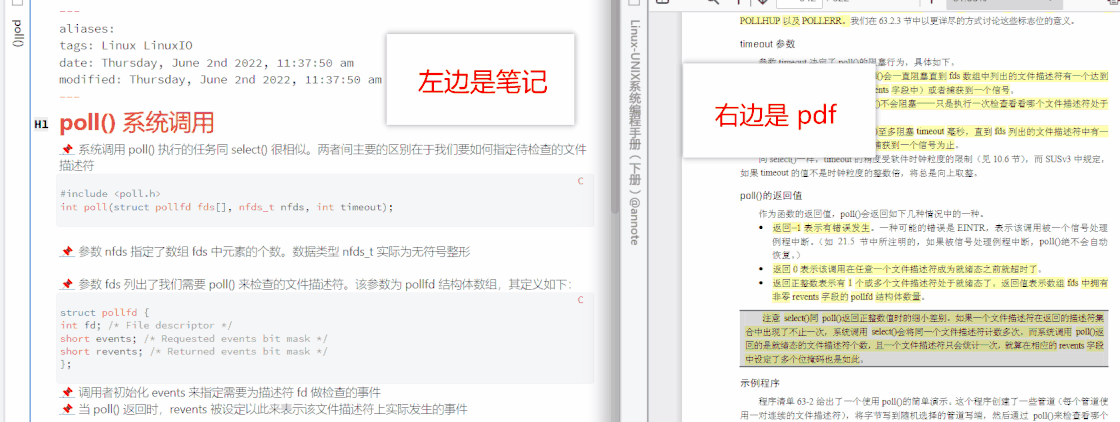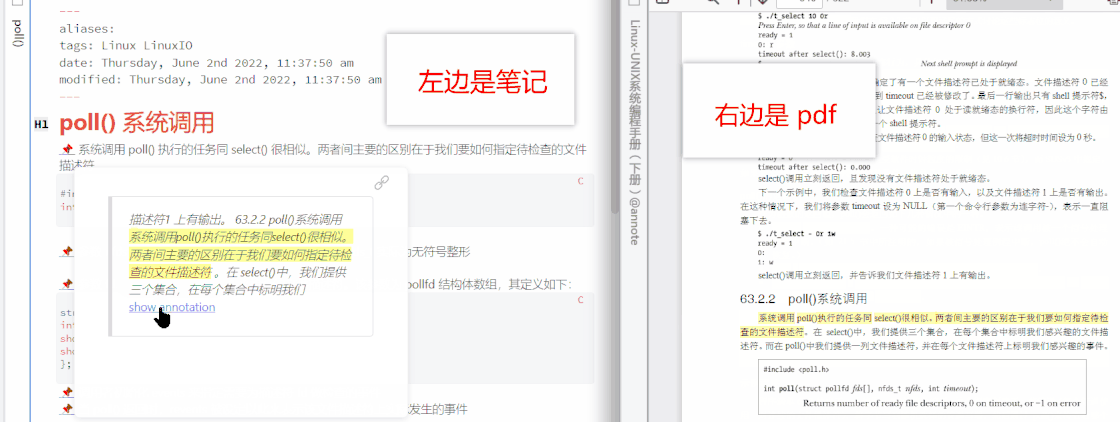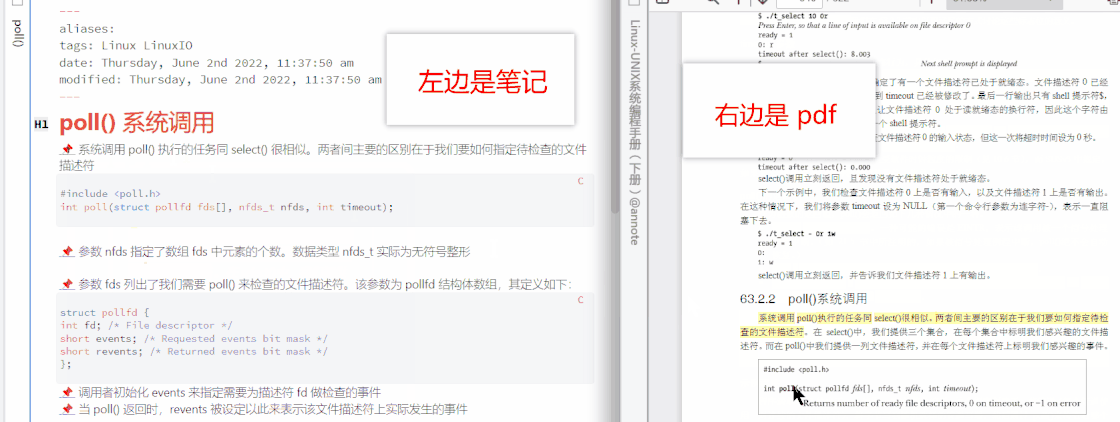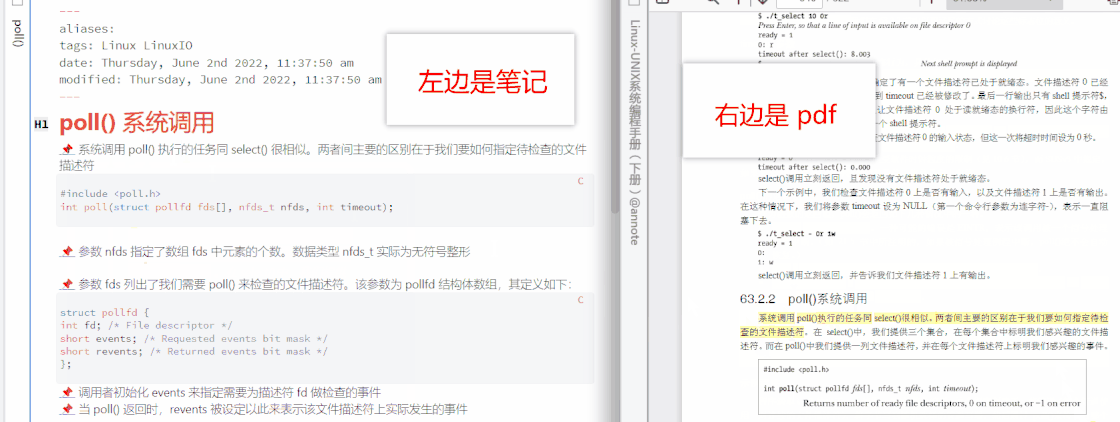
Obsidian 里还有一个很强大的插件,叫 Annotator,它可以实现笔记内跳转到 pdf 原文
现在,使用 Obsidian 自带的双链功能,可以实现笔记间相互跳转,结合上述两个插件,可以实现笔记到多媒体的跳转,信息的处理过程已经完备。一般我们学习的过程相当于上山和下山,刚学的时候就好像上山,很陌生、吃力,所谓学而时习之,复习或练习的过程就像下山,没有陌生感,不见得轻松,但非走不可。那么如何把复习这一过程纳入工作流的环节里呢?
复习
Obsidian 内已经有一个连接 Anki 的插件,Anki 就是大名鼎鼎的、基于间隔重复的记忆软件。使用该插件可以截取笔记的片段导出到 Anki 并变成一张卡片,卡片内也有跳转回笔记原文的链接

小结
结合上述的 处理信息 以及 复习,可以得出
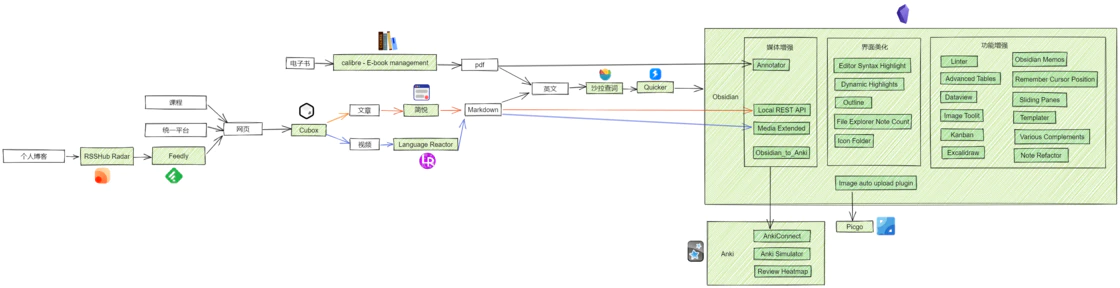
总结
这个工作流是在我这两年业余时间学习时所慢慢形成的,在学习过程中因为对一些重复性的过程而感到厌倦,正是这种厌倦产生了某种特定的需求,恰好在平时网上冲浪时了解到的一些工具满足了我这些需求。不要为了虚无的满足感而将工具强行拼凑到自己的工作流中,人生苦短,做实事最紧要。
btw,此篇文章是讲解工作流的演化思路,如果对此工作流的实现细节感兴趣,建议阅读完本文后再按顺序阅读以下文章
- 3000+小时积累的学习工作流
- Obsidian 的高级玩法|打造能跳转到任何格式文件的笔记