看看批量梯度下降和小批量梯度下降的图形,与我们的理解是相符的
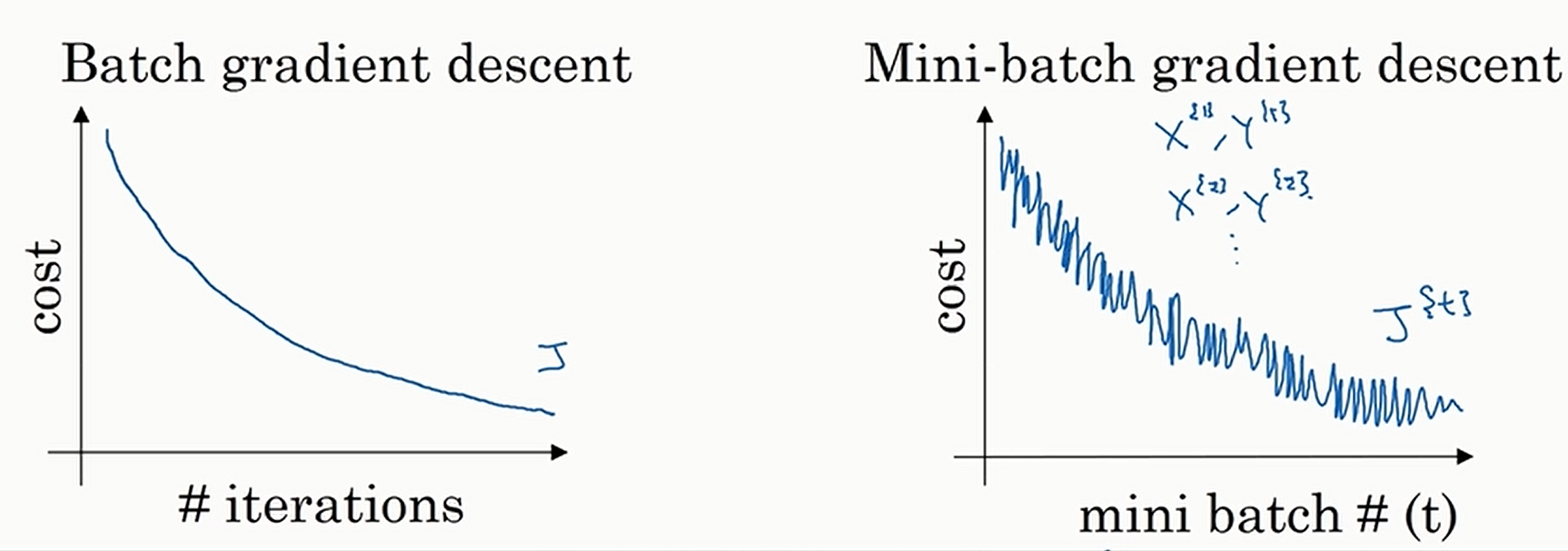
注意到小批量梯度下降不是严格单减的,只是趋势是单调减少的(图中的纵轴Cost指的是对于整个训练数据的损失)
每次的批量的大小显然是一个超参数。当批量大小为\(1\)的时候叫做随机梯度下降,当批量大小为\(m\)的时候叫做批量梯度下降。前者由于每次只运用一个样本计算,无法充分利用GPU的计算优势,后者则由于每次都要用整个数据集,每次迭代的时间太长了,所以实际中一般选择两个极端之间。三种梯度下降方法的迭代情况见下图
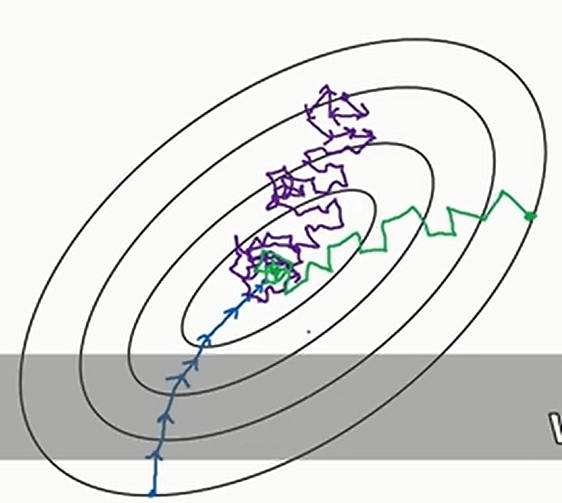
其中蓝色的线是批量梯度下降,紫色的线是随机梯度下降(最后不会收缩到最小值点,只会在附近摆动),绿色的线是小批量梯度下降
那么到底应该如何选择正确的批量梯度大小呢?如果数据量比较小(比如少于\(2000\))就用批量梯度下降,否则的话选择小批量梯度下降,批量大小选择\(64\)到\(512\)之间的任何一个\(2\)的整次幂即可(更多的是将批量大小当做一个超参数,尝试多个批量大小)
小批量梯度下降一般会打乱数据的顺序,这样会加速收敛,防止过拟合(可能类似的样本排在一起)。但是有些时候也不会打乱数据的顺序,比如时间序列等数据顺序matters的时候