C#实现自己的Json解析器(LALR(1)+miniDFA)
Json是一个用处广泛、文法简单的数据格式。本文介绍如何用bitParser(拥有自己的解析器(C#实现LALR(1)语法解析器和miniDFA词法分析器的生成器))迅速实现一个简单高效的Json解析器。
读者可在(JsonFormat)查看、下载完整代码。
Json格式的文法
我们可以在(https://ecma-international.org/wp-content/uploads/ECMA-404_2nd_edition_december_2017.pdf )找到Json格式的详细说明。据此,可得如下文法:
// Json grammar according to ECMA-404 2nd Edition / December 2017
Json = Object | Array ;
Object = '{' '}' | '{' Members '}' ;
Array = '[' ']' | '[' Elements ']' ;
Members = Members ',' Member | Member ;
Elements = Elements ',' Element | Element ;
Member = 'string' ':' Value ;
Element = Value ;
Value = 'null' | 'true' | 'false' | 'number' | 'string'| Object | Array ;%%"([^"\\\u0000-\u001F]|\\["\\/bfnrt]|\\u[0-9A-Fa-f]{4})*"%% 'string'
%%[-]?(0|[1-9][0-9]*)([.][0-9]+)?([eE][+-]?[0-9]+)?%% 'number'
实际上这个文法是我用AI写出来后再整理成的。
此文法说明:
-
一个
Json要么是一个Object,要么是一个Array。 -
一个
Object包含0-多个键值对("key" : value),用{ }括起来。 -
一个
Array包含0-多个value,用[ ]括起来。 -
一个
value有如下几种类型:null、true、false、number、string、Object、Array。
其中:
null、true、false就是字面意思,因而可以省略不写。如果要在文法中显式地书写,就是这样:
%%null%% 'null'
%%true%% 'true'
%%false%% 'false'
{、}、[、]、,、:也都是字面意思,因而可以省略不写。如果要在文法中显式地书写,就是这样:
%%null%% 'null'
%%null%% 'null'
%%null%% 'null'
%%null%% 'null'
%%null%% 'null'
%%null%% 'null'number可由下图描述:
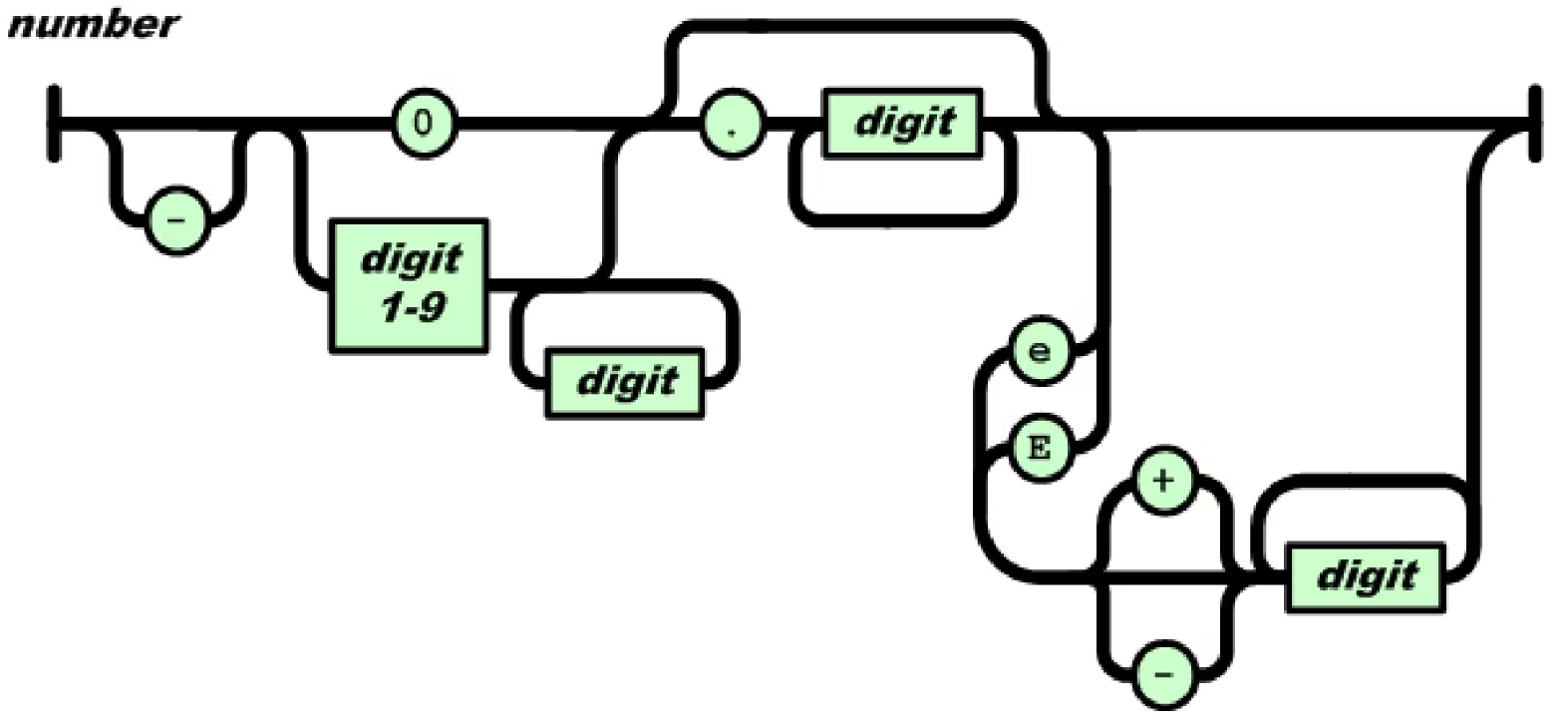
图上直观地说明了number这个token的正则表达式由4个依次排列的部分组成:
[-]? (0|[1-9][0-9]*) ([.][0-9]+)? ([eE][+-]?[0-9]+)?
string可由下图描述:

图上直观地说明了string这个token的正则表达式是用"包裹起来的某些字符或转义字符:
" ( [^"\\\u0000-\u001F] | \\["\\/bfnrt] | \\u[0-9A-Fa-f]{4} )* "
/*
实际含义为:
非"、非\、非控制字符(\u0000-\u001F)
\"、\\、\/、\b、\f、\n、\r、\t
\uNNNN
*/
Value = Object | Array;说明Json中的数据是可以嵌套的。
将此文法作为输入,提供给bitParser,就可以一键生成下述章节介绍的Json解析器代码和文档了。
生成的词法分析器代码

DFA
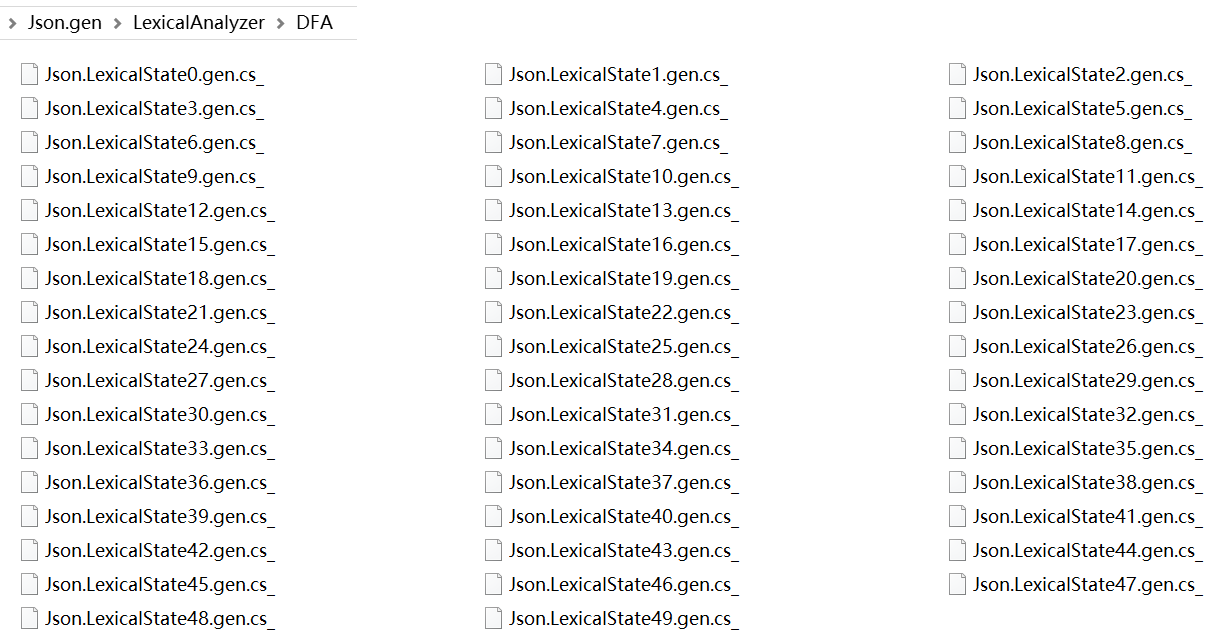
DFA文件夹下是依据确定的有限自动机原理生成的词法分析器的全部词法状态。
初始状态lexicalState0
。。。
DFA文件夹下的实现是最初的也是最直观的实现。它已经被更高效的实现方式取代了。现在此文件夹仅供学习参考用。因此我将C#文件的扩展名cs改为cs_,以免其被编译。
miniDFA

miniDFA文件夹下是依据Hopcroft算法得到的最小化的有限自动机的全部词法状态。它与DFA的区别仅在于词法状态数量可能减少了。
它是第二个实现,它也已经被更高效的实现方式取代了。现在此文件夹仅供学习参考用。因此我将C#文件的扩展名cs改为cs_,以免其被编译。
tableDFA

tableDFA文件夹下是二维数组形式(ElseIf[][])的miniDFA。它与miniDFA表示的内容相同,区别在于:它用一个数组(ElseIf[])表示一个词法状态,而miniDFA用一个函数(Action<LexicalContext, char, CurrentStateWrap>)表示一个词法状态。这样可以减少内存占用。
二维数组形式的miniDFA
。。。
它是第三个实现,它也已经被更高效的实现方式取代了。现在此文件夹仅供学习参考用。因此我将C#文件的扩展名cs改为cs_,以免其被编译。
Json.LexiTable.gen.bin

这是将二维数组形式(ElseIf[][])的miniDFA写入了一个二进制文件。加载JsonParser时,读取此文件即可得到二维数组形式(ElseIf[][])的miniDFA。这就不需要将整个ElseIf[][]硬编码到源代码中了,从而进一步减少了内存占用。
为了方便调试、参考,我为其准备了对应的文本格式:
Json.LexiTable.gen.txt
它是第四个实现,这是目前使用的实现方式。为了加载路径上的方便,我将其从Json.gen\LexicalAnalyzer文件夹挪到了Json.gen文件夹下。
Json.LexicalScripts.gen.cs
这是各个词法分析状态都可能用到的函数,包括3类:Begin、Extend、Accept。其作用是:记录一个token的起始位置(Begin)和结束位置(Extend),设置其类型、行数、列数等信息,将其加入List<Token> tokens数组(Accept)。
Json.LexicalScripts.gen.cs
Json.LexicalReservedWords.gen.cs
这里记录了Json文法的全部保留字(任何编程语言中的keyword),也就是{、}、[、]、,、:、null、true、false这些。显然这是辅助的东西,不必在意。
Json.LexicalReservedWords.gen.cs
README.gen.md
这是词法分析器的说明文档,用mermaid画出了各个token的状态机和整个文法的总状态机,如下图所示。
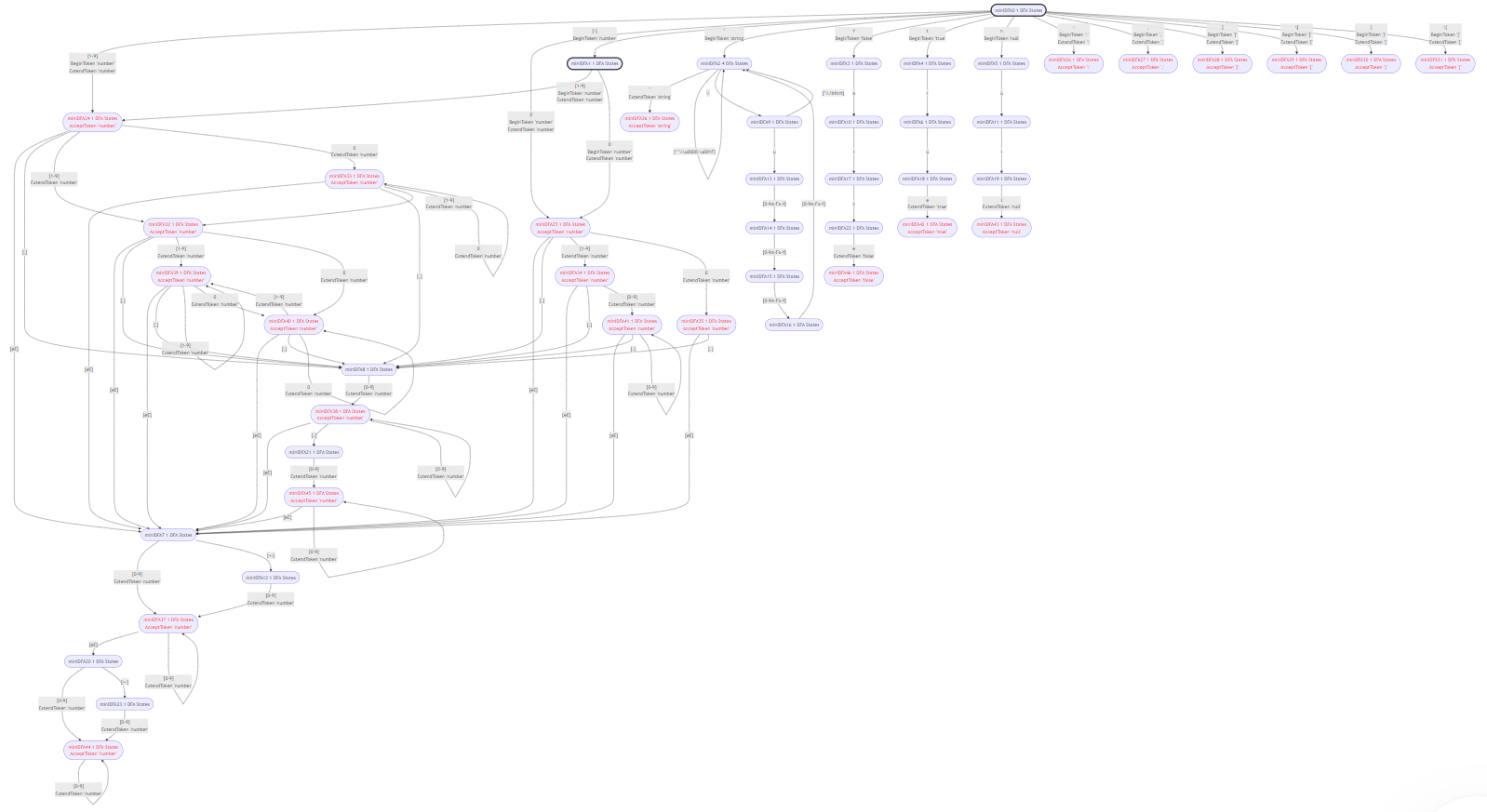
我知道你们看不清。我也看不清。找个大屏幕直接看README.gen.md文件吧。
生成的语法分析器代码

Dicitonary<int, LRParseAction>
Json.Dict.LALR(1).gen.cs_是LALR(1)的语法分析状态机,每个语法状态都是一个Dicitonary<int, LRParseAction>对象。
Json.Dict.LALR(1).gen.cs_
另外3个Json.Dict.*.gen.cs_分别是LR(0)、SLR(1)、LR(1)的语法分析状态机,不再赘述。
这是最初的也是最直观的实现,它已经被更高效的实现方式取代了。现在此文件夹仅供学习参考用。因此我将C#文件的扩展名cs改为cs_,以免其被编译。
int[]+LRParseAction[]
Json.Table.LALR(1).gen.cs_是LALR(1)的语法分析状态机,每个语法状态都是一个包含int[]和LRParseAction[]的对象。这里的每个int[t]和LRParseAction[t]合起来就代替了Dictionary<int, LRParseAction>对象的一个键值对(key/value),从而减少了内存占用,也稍微提升了运行效率。
Json.Table.LALR(1).gen.cs_
另外4个Json.Dict.*.gen.cs_分别是LL(1)、LR(0)、SLR(1)、LR(1)的语法分析状态机,不再赘述。
它是第二个实现,它已经被更高效的实现方式取代了。现在此文件夹仅供学习参考用。因此我将C#文件的扩展名cs改为cs_,以免其被编译。
Json.Table.*.gen.bin
与词法分析器类似,这是将数组形式(int[]+LRParseAction[])的语法分析表写入了一个二进制文件。加载JsonParser时,读取此文件即可得到数组形式(int[]+LRParseAction[])的语法分析表。这就不需要将整个语法分析表硬编码到源代码中了,从而进一步减少了内存占用。
为了方便调试、参考,我为其准备了对应的文本格式,例如LALR(1)的语法分析表:
Json.Table.LALR(1).gen.txt
它是第三个实现,这是目前使用的实现方式。为了加载路径上的方便,我将其从Json.gen\SyntaxParser文件夹挪到了Json.gen文件夹下。

生成的提取器代码
所谓提取,就是按后序优先遍历的顺序访问语法树的各个结点,在访问时提取出语义信息。
例如,{ "a": 0.3, "b": true, "a": "again" }的语法树是这样的:
R[0] Json = Object ;⛪T[0->12]└─R[3] Object = '{' Members '}' ;⛪T[0->12]├─T[0]='{' {├─R[6] Members = Members ',' Member ;⛪T[1->11]│ ├─R[6] Members = Members ',' Member ;⛪T[1->7]│ │ ├─R[7] Members = Member ;⛪T[1->3]│ │ │ └─R[10] Member = 'string' ':' Value ;⛪T[1->3]│ │ │ ├─T[1]='string' "a"│ │ │ ├─T[2]=':' :│ │ │ └─R[15] Value = 'number' ;⛪T[3]│ │ │ └─T[3]='number' 0.3│ │ ├─T[4]=',' ,│ │ └─R[10] Member = 'string' ':' Value ;⛪T[5->7]│ │ ├─T[5]='string' "b"│ │ ├─T[6]=':' :│ │ └─R[13] Value = 'true' ;⛪T[7]│ │ └─T[7]='true' true│ ├─T[8]=',' ,│ └─R[10] Member = 'string' ':' Value ;⛪T[9->11]│ ├─T[9]='string' "a"│ ├─T[10]=':' :│ └─R[16] Value = 'string' ;⛪T[11]│ └─T[11]='string' "again"└─T[12]='}' }
按后序优先遍历的顺序,提取器会依次访问T[0]、T[1]、T[2]、T[3]并将其入栈,然后访问R[15] Value = 'number' ;⛪T[3],此时应当:
// [15] Value = 'number' ;
var r0 = (Token)context.rightStack.Pop();// T[3]出栈
var left = new JsonValue(JsonValue.Kind.Number, r0.value);
context.rightStack.Push(left);// Value入栈
之后会访问R[10] Member = 'string' ':' Value ;⛪T[1->3],此时应当:
// [10] Member = 'string' ':' Value ;
var r0 = (JsonValue)context.rightStack.Pop();// Value出栈
var r1 = (Token)context.rightStack.Pop();// :出栈
var r2 = (Token)context.rightStack.Pop();// string出栈
var left = new JsonMember(key: r2.value, value: r0);
context.rightStack.Push(left);// Member入栈
这样逐步地访问到根节点R[0] Json = Object ;⛪T[0->12],此时应当:
var r0 = (List<JsonMember>)context.rightStack.Pop();// Member列表出栈
var left = new Json(r0);
context.rightStack.Push(left);// Json入栈
这样,语法树访问完毕了,栈context.rightStack中有且只有1个对象,即最终的Json。此时应当:
// [-1] Json' = Json ;
context.result = (Json)context.rightStack.Pop();
提取器的完整代码InitializeExtractorItems
不同的应用场景会要求不同的语义信息,因而一键生成的提取器代码不是这样的,而是仅仅将语法树压平了,并且保留了尽可能多的源代码信息,如下所示:
一键生成的提取器代码
这是步子最小的保守式代码,程序员可以在此基础上继续开发,也可以自行编写访问各类型结点的提取动作。本应用场景的目的是尽可能高效地解析Json文本文件,因而完全自行编写了访问各类型结点的提取动作。
测试
测试用例0
测试用例1
测试用例2
测试用例3
测试用例4
测试用例5
上述测试用例都能够被JsonParser正确解析,也可以在(https://jsonlint.com/)验证。