Linux负载分析
1. 确认高负载的真实性:
- uptime 或 top:
- 首先,使用 uptime 或 top 命令再次确认系统负载情况。重点关注1分钟、5分钟和15分钟的平均负载,确保它们都持续处于高位。
- 注意:如果1分钟负载远高于15分钟负载,可能只是瞬间高峰,需要持续观察。
2. 识别资源瓶颈:
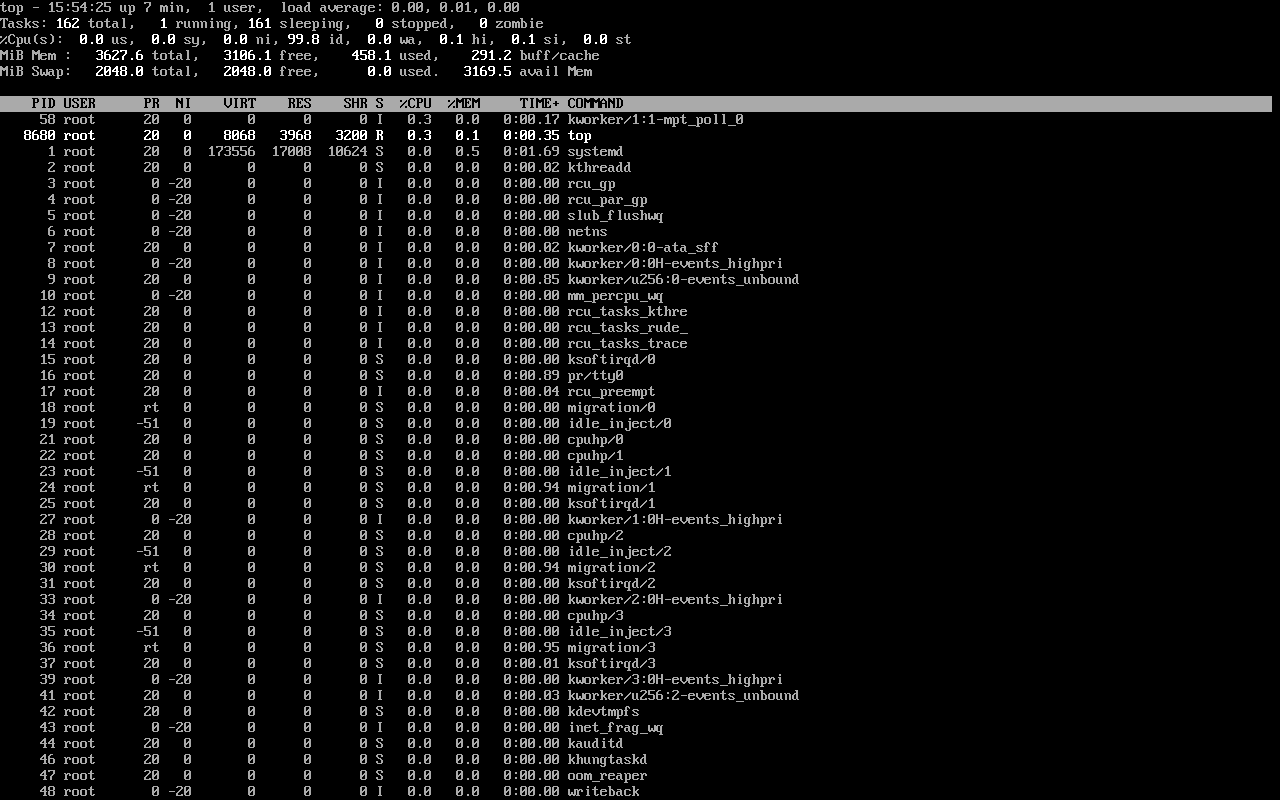
- top 或 htop:
- 使用 top 或 htop 实时监控进程资源占用情况。
- 按CPU使用率(%CPU)和内存使用率(%MEM)排序,找出占用资源最多的进程。
- 观察进程状态(S列),是否存在大量处于运行状态(R)的进程。
- vmstat:
- 使用 vmstat 1(每秒刷新一次)监控系统资源使用情况。
- 重点关注以下指标:
- r(运行队列):如果 r 值持续高于CPU核心数,表示CPU资源严重不足。
- swpd、si、so(交换空间):如果交换空间使用频繁,表示内存不足。
- io(I/O):如果 bi 和 bo 值很高,表示磁盘I/O存在瓶颈。
- us、sy、wa(CPU):分析CPU时间分配,确定是用户进程、系统进程还是I/O等待导致高负载。
- iostat:
- iostat -xz 1 监控磁盘I/O性能。
- 查看磁盘的 %util(磁盘利用率)和 await(平均I/O等待时间),判断磁盘I/O是否存在瓶颈。
- free -m:
- 查看内存使用情况。判断是否内存溢出,大量使用SWAP。
3. 分析具体进程:
- ps aux:
- 使用 ps aux 命令查看占用资源最多的进程的详细信息。
- 确定进程的完整命令和启动参数,了解其具体功能。
- netstat -antp:
- 如果怀疑是网络问题,使用 netstat -antp 查看网络连接情况。
- 找出是否存在大量连接或异常流量。
- lsof:
- 使用 lsof 命令查看进程打开的文件和网络连接。
- 找出是否存在文件句柄泄漏或网络连接泄漏。
- 应用程序日志:
- 查看相关应用程序的日志文件,寻找错误或异常信息。
- 常见高负载原因及排查方向:
- CPU密集型应用:
- 大量计算任务、视频处理、数据分析等。
- 排查方向:优化算法、增加CPU资源。
- 内存泄漏:
- 应用程序内存管理不当,导致内存持续增长。
- 排查方向:分析应用程序代码、使用内存分析工具。
- 磁盘I/O瓶颈:
- 大量磁盘读写操作、数据库查询、日志写入等。
- 排查方向:优化磁盘I/O、更换高性能磁盘。
- 网络攻击:
- DDoS攻击、网络爬虫等。
- 排查方向:使用防火墙、流量控制。
- 数据库问题:
- 慢查询,数据库锁,数据库链接数过多。
- 排查方向:优化SQL语句,优化数据库参数。
5. 应急处理:
- 终止异常进程:
- 如果确定是某个进程导致高负载,可以使用 kill 命令终止该进程。
- 重启服务:
- 如果无法确定具体原因,可以尝试重启相关服务或服务器。
- 关键提示:
- 高负载问题通常是多种因素综合作用的结果。
- 排查过程中需要综合分析各种系统指标和应用程序日志。
- 逐步排查,抽丝剥茧。