AMD CDNA介绍
AMD CDNA处理器采用并行微架构,旨在为通用数据并行应用提供一个出色的平台。需要高带宽或计算密集型的数据密集型应用程序,这是在AMD CDNA处理器上运行的候选者。
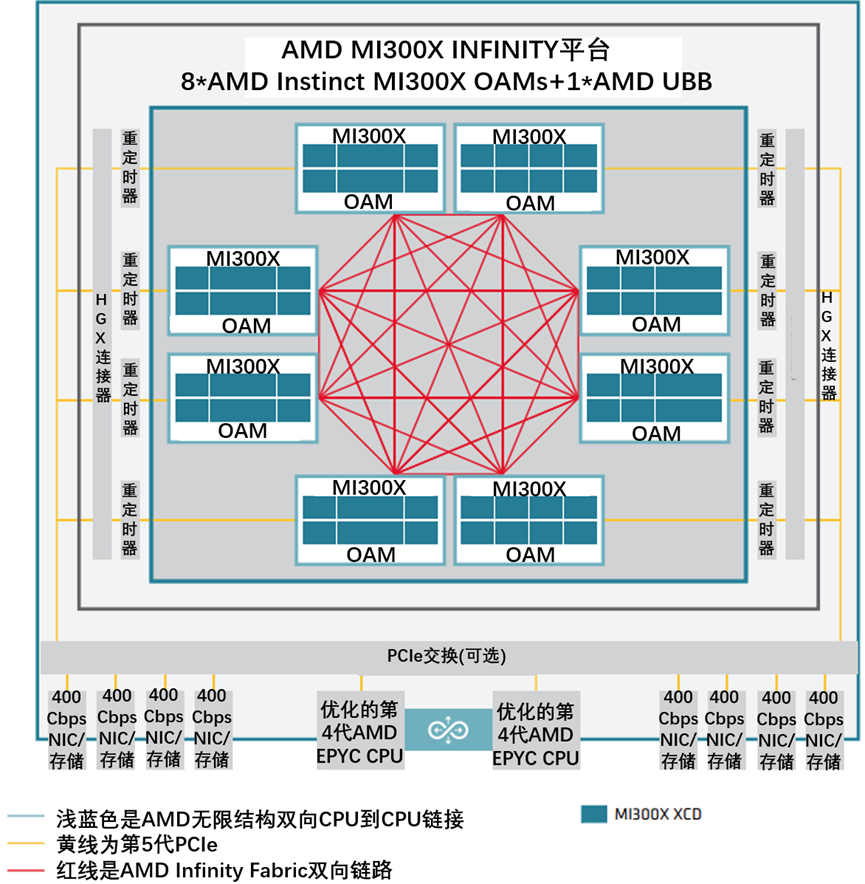
AMD CDNA生成系列处理器的框图,如图5-10所示。
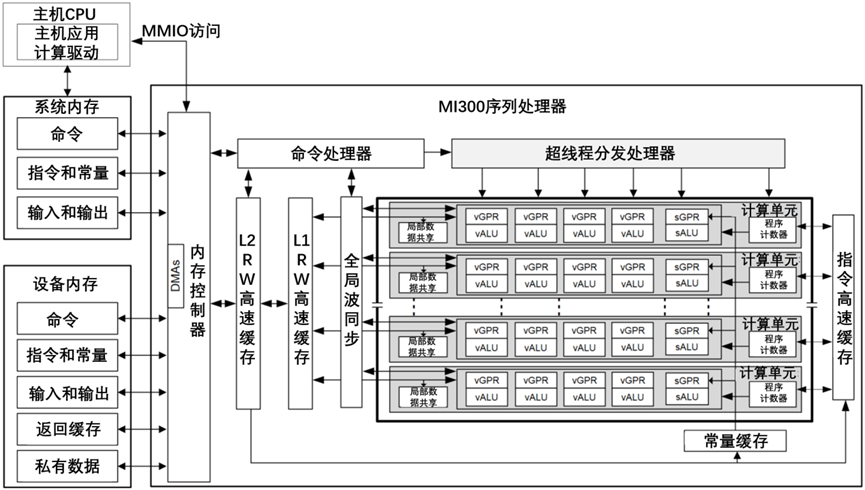
图5-10 AMD CDNA生成系列处理器的框图
CDNA设备包括数据并行处理器(DPP)阵列、命令处理器、存储器控制器和其他逻辑(未示出)。CDNA命令处理器读取主机系统内存映射的CDNA寄存器的命令。命令处理器在命令完成时,向主机发送硬件生成的中断。CDNA存储器控制器可以直接访问所有CDNA设备存储器,以及系统存储器的主机指定区域。为了满足读写请求,存储器控制器执行直接存储器存取(DMA)控制器的功能,包括基于存储器中请求数据的格式地址偏移。在CDNA环境中,一个完整的应用程序包括两部分:
1)在主处理器上运行的程序。
2)在CDNA处理器上运行的程序,称为内核。
CDNA程序由主机命令控制
1)设置CDNA内部基址和其他配置寄存器。
2)指定CDNA加速器要运行的数据域。
3)使CDNA加速器上的缓存无效并刷新缓存。
4)使CDNA加速器开始执行程序。
5.3.2 项目组织
CDNA内核是由CDNA处理器执行的程序。从概念上讲,内核在每个工作项上独立执行,但实际上CDNA处理器将64个工作项分组到一个波阵面中,波阵面在一次过程中对所有64个工作项目执行内核。
CDNA处理器由以下部分组成:
1)标量ALU,每个波阵面处理一个值(所有工作项都有)。
2)向量ALU,对每个工作项的唯一值进行运算。
3)本地数据存储,允许工作组内的工作项进行通信和共享数据。
4)标量内存,可以通过缓存在SGPR和内存之间传输数据。
5)向量存储器,可以在VGPR和存储器之间传输数据,包括采样纹理贴图。
1. 计算着色器
计算内核(着色器)是可以在CDNA处理器上运行的通用程序,从内存中获取数据,对其进行处理,并将结果写回内存。计算内核由调度创建,这会导致CDNA处理器在1D、2D或3D数据网格中的所有工作项上运行内核。CDNA处理器遍历这个网格并生成波前,然后运行计算内核。每个工作项都使用其在网格中的唯一地址(索引)进行初始化。基于此索引,工作项计算需要处理的数据的地址以及如何处理结果。
2. 数据共享
AMD CDNA流处理器可以在不同的工作项之间共享数据。数据共享可以显著提高性能。显示了每个工作项可用的内存层次结构,如图5-11所示。
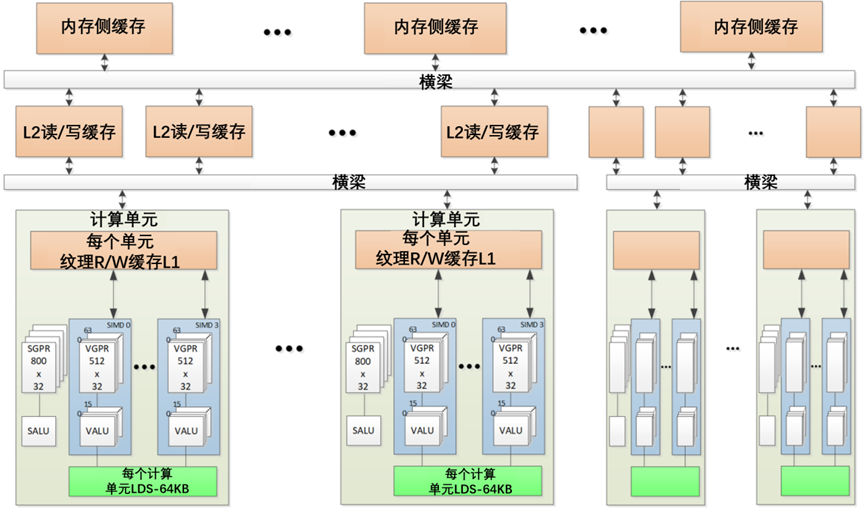
图5-11 共享内存层次结构