CUDA编程 - 共享内存
- 共享内存
- 一、为什么要使用 shared memory?
- 1.1、从硬件出发理解:
- 1.2、从软件出发理解:
- 二、如何使用shared memory
- 2.1、静态共享内存
- 2.2、动态共享内存
- 三、实践 - 使用共享内存执行矩阵乘法
- 总结
共享内存
一、为什么要使用 shared memory?
1.1、从硬件出发理解:

如图,我们的计算单元在 Thread 中,距离 Thread 越远的访问时间要更久 ,一般都是在 global memory 中运行程序,但是为了 “更近”,我们会选择 shared memory。
1.2、从软件出发理解:
拿矩阵乘法来举例:

我们要计算得出矩阵C(红色)的每个元素,会发现不管是矩阵A还是矩阵B的元素,都不止用了一次。但是我们要取数据的时候,都会从 global memory (全局内存)中取数据,这样存在冗长的操作,会显得比较慢,因为访问 “距离” 都在累加。
所以应该把数据都放在共享内存中,会较快计算速度。
ps:
Global memory 的延迟是最高的,我们一般在cudaMalloc时都是在global memory上进行访问的
二、如何使用shared memory
2.1、静态共享内存
在核函数中,要将一个变量定义为共享内存变量,就要在定义语句中加上一个限定
符 __shared__。一般情况下,我们需要的是一个长度等于线程块大小的数组。
eg:__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];
如果没有限定符 __shared__,该语句将极有可能定义一个长度为 128 的局部数组
2.2、动态共享内存
在静态共享内存中,如果在定义共享内存变量时不小心把数组长度写错了,就有
可能引起错误或者降低核函数性能。而动态共享内存可以避免这种情况。
语法:
<<<grid_size, block_size, sizeof(real) * block_size>>>
- grid_size:网格大小
- block_size:线程块大小
- sizeof(real) * block_size:核函数中每个线程块需要定义的动态共享内存的字节数
动静态声明对比:
动态共享内存声明:extern __shared__ real s_y[]
对比静态共享内存声明:__shared__ real s_y[128];
有两点不同:第一,必须加上限定词 extern;第二,不能指定数组大小。
三、实践 - 使用共享内存执行矩阵乘法
写两个核函数,来对比一下使用共享内存的不同之处:
核函数1:常规的矩阵乘法
__global__ void MatmulKernel(float *M_device, float *N_device, float *P_device, int width){/* 我们设定每一个thread负责P中的一个坐标的matmul所以一共有width * width个thread并行处理P的计算*/int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;float P_element = 0;/* 对于每一个P的元素,我们只需要循环遍历width次M和N中的元素就可以了*/for (int k = 0; k < width; k ++){float M_element = M_device[y * width + k];float N_element = N_device[k * width + x];P_element += M_element * N_element;}P_device[y * width + x] = P_element;
}
核函数2:使用静态共享内存的核函数
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了*/for (int m = 0; m < width / BLOCKSIZE; m ++) {M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];__syncthreads();for (int k = 0; k < BLOCKSIZE; k ++) {P_element += M_deviceShared[ty][k] * N_deviceShared[k][tx];}__syncthreads();}P_device[y * width + x] = P_element;
}
两个核函数 主要看 for 循环,两者主要在遍历M(A), 和N(B)的方式不同。
如果使用共享内存的话,就不像上面的是一条条的访问数据了,是一块块同时访问的,所以在遍历的时候不一样

下面贴出完整的代码,来运行体验一下
文件分布如下:
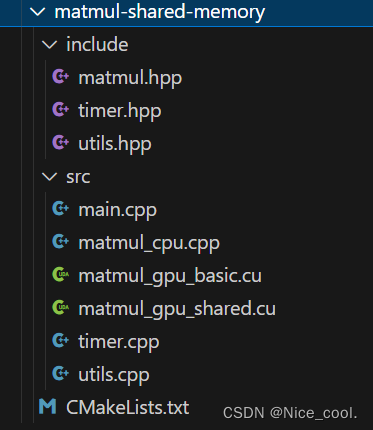
CMakeLists.txt
cmake_policy(SET CMP0048 NEW)
cmake_minimum_required(VERSION 3.16)#Cmake最低版本
project(demo VERSION 0.0.1 LANGUAGES C CXX CUDA)#设置语言标准
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
include_directories(${CUDA_INCLUDE_DIRS} ) # add cuda
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS} ) #添加项目自身的库和依赖
aux_source_directory(src SRC_LIST)#添加src目录下的所有源文件
include_directories(include)#添加头文件路径
include_directories(include/cubit)#添加头文件路径#编译列表
add_executable(${PROJECT_NAME} ${SRC_LIST} )
target_link_libraries(demo)
timer.hpp
#include <chrono>
#include <ratio>
#include <string>
#include "cuda_runtime.h"class Timer {
public:using s = std::ratio<1, 1>;using ms = std::ratio<1, 1000>;using us = std::ratio<1, 1000000>;using ns = std::ratio<1, 1000000000>;public:Timer();~Timer();public:void start_cpu();void start_gpu();void stop_cpu();void stop_gpu();template <typename span>void duration_cpu(std::string msg);void duration_gpu(std::string msg);private:std::chrono::time_point<std::chrono::high_resolution_clock> _cStart;std::chrono::time_point<std::chrono::high_resolution_clock> _cStop;cudaEvent_t _gStart;cudaEvent_t _gStop;float _timeElasped;
};template <typename span>
void Timer::duration_cpu(std::string msg){std::string str;if(std::is_same<span, s>::value) { str = "s"; }else if(std::is_same<span, ms>::value) { str = "ms"; }else if(std::is_same<span, us>::value) { str = "us"; }else if(std::is_same<span, ns>::value) { str = "ns"; }std::chrono::duration<double, span> time = _cStop - _cStart;LOG("%-40s uses %.6lf %s", msg.c_str(), time.count(), str.c_str());
}timer.cpp
#include <chrono>
#include <iostream>
#include <memory>
#include "timer.hpp"#include "utils.hpp"
#include "cuda_runtime.h"
#include "cuda_runtime_api.h"Timer::Timer(){_timeElasped = 0;_cStart = std::chrono::high_resolution_clock::now();_cStop = std::chrono::high_resolution_clock::now();cudaEventCreate(&_gStart);cudaEventCreate(&_gStop);
}Timer::~Timer(){cudaFree(_gStart);cudaFree(_gStop);
}void Timer::start_gpu() {cudaEventRecord(_gStart, 0);
}void Timer::stop_gpu() {cudaEventRecord(_gStop, 0);
}void Timer::start_cpu() {_cStart = std::chrono::high_resolution_clock::now();
}void Timer::stop_cpu() {_cStop = std::chrono::high_resolution_clock::now();
}void Timer::duration_gpu(std::string msg){CUDA_CHECK(cudaEventSynchronize(_gStart));CUDA_CHECK(cudaEventSynchronize(_gStop));cudaEventElapsedTime(&_timeElasped, _gStart, _gStop);// cudaDeviceSynchronize();// LAST_KERNEL_CHECK();LOG("%-60s uses %.6lf ms", msg.c_str(), _timeElasped);
}utils.hpp
#ifndef __UTILS_HPP__
#define __UTILS_HPP__#include <cuda_runtime.h>
#include <system_error>
#include <stdarg.h>#define CUDA_CHECK(call) __cudaCheck(call, __FILE__, __LINE__)
#define LAST_KERNEL_CHECK(call) __kernelCheck(__FILE__, __LINE__)
#define LOG(...) __log_info(__VA_ARGS__)#define BLOCKSIZE 16static void __cudaCheck(cudaError_t err, const char* file, const int line) {if (err != cudaSuccess) {printf("ERROR: %s:%d, ", file, line);printf("CODE:%s, DETAIL:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));exit(1);}
}static void __kernelCheck(const char* file, const int line) {cudaError_t err = cudaPeekAtLastError();if (err != cudaSuccess) {printf("ERROR: %s:%d, ", file, line);printf("CODE:%s, DETAIL:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));exit(1);}
}static void __log_info(const char* format, ...) {char msg[1000];va_list args;va_start(args, format);vsnprintf(msg, sizeof(msg), format, args);fprintf(stdout, "%s\n", msg);va_end(args);
}void initMatrix(float* data, int size, int low, int high, int seed);
void printMat(float* data, int size);
void compareMat(float* h_data, float* d_data, int size);#endif //__UTILS_HPP__//utils.cpp
#include "utils.hpp"
#include <math.h>
#include <random>void initMatrix(float* data, int size, int low, int high, int seed) {srand(seed);for (int i = 0; i < size; i ++) {data[i] = float(rand()) * float(high - low) / RAND_MAX;// data[i] = (float)i;}
}void printMat(float* data, int size) {for (int i = 0; i < size; i ++) {printf("%.8lf", data[i]);if (i != size - 1) {printf(", ");} else {printf("\n");}}
}void compareMat(float* h_data, float* d_data, int size) {double precision = 1.0E-4;/* * 这里注意,浮点数运算时CPU和GPU之间的计算结果是有误差的* 一般来说误差保持在1.0E-4之内是可以接受的*/for (int i = 0; i < size; i ++) {if (abs(h_data[i] - d_data[i]) > precision) {int y = i / size;int x = i % size;printf("Matmul result is different\n");printf("cpu: %.8lf, gpu: %.8lf, cord:[%d, %d]\n", h_data[i], d_data[i], x, y);break;}}
}matmul_cpu.cpp
#include "matmul.hpp"void MatmulOnHost(float *M, float *N, float *P, int width){for (int i = 0; i < width; i ++)for (int j = 0; j < width; j ++){float sum = 0;for (int k = 0; k < width; k++){float a = M[i * width + k];float b = N[k * width + j];sum += a * b;}P[i * width + j] = sum;}
}void MataddOnHost(float *M, float *N, float *P, int width){for (int i = 0; i < width; i ++)for (int j = 0; j < width; j ++){int idx = j * width + i;P[idx] = M[idx] + N[idx];}
}matmul_gpu_basic.cu
#include "cuda_runtime_api.h"
#include "stdio.h"
#include <iostream>#include "utils.hpp"/* matmul的函数实现*/
__global__ void MatmulKernel(float *M_device, float *N_device, float *P_device, int width){/* 我们设定每一个thread负责P中的一个坐标的matmul所以一共有width * width个thread并行处理P的计算*/int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;float P_element = 0;/* 对于每一个P的元素,我们只需要循环遍历width次M和N中的元素就可以了*/for (int k = 0; k < width; k ++){float M_element = M_device[y * width + k];float N_element = N_device[k * width + x];P_element += M_element * N_element;}P_device[y * width + x] = P_element;
}/*这个实现的问题点:只有一个block因为只有一个block,并且又因为SM中的sp数量是有限的,所以不能够全部放下。想要全部放下的话需要缩小矩阵的大小有很多次读写,但具体的执行很少(两次读和一次写,一次计算)解决办法:使用tile
*/
void MatmulOnDevice(float *M_host, float *N_host, float* P_host, int width, int blockSize){/* 设置矩阵大小 */int size = width * width * sizeof(float);/* 分配M, N在GPU上的空间*/float *M_device;float *N_device;CUDA_CHECK(cudaMalloc(&M_device, size));CUDA_CHECK(cudaMalloc(&N_device, size));/* 分配M, N拷贝到GPU上*/CUDA_CHECK(cudaMemcpy(M_device, M_host, size, cudaMemcpyHostToDevice));CUDA_CHECK(cudaMemcpy(N_device, N_host, size, cudaMemcpyHostToDevice));/* 分配P在GPU上的空间*/float *P_device;CUDA_CHECK(cudaMalloc(&P_device, size));/* 调用kernel来进行matmul计算, 在这个例子中我们用的方案是:使用一个grid,一个grid里有width*width个线程 */dim3 dimBlock(blockSize, blockSize);dim3 dimGrid(width / blockSize, width / blockSize);MatmulKernel <<<dimGrid, dimBlock>>> (M_device, N_device, P_device, width);/* 将结果从device拷贝回host*/CUDA_CHECK(cudaMemcpy(P_host, P_device, size, cudaMemcpyDeviceToHost));CUDA_CHECK(cudaDeviceSynchronize());/* 注意要在synchronization结束之后排查kernel的错误 */LAST_KERNEL_CHECK(); /* Free */cudaFree(P_device);cudaFree(N_device);cudaFree(M_device);
}matmul_gpu_shared.cu
#include "cuda_runtime_api.h"
#include "utils.hpp"#define BLOCKSIZE 16/* 使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/for (int m = 0; m < width / BLOCKSIZE; m ++) {M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];__syncthreads();for (int k = 0; k < BLOCKSIZE; k ++) {P_element += M_deviceShared[ty][k] * N_deviceShared[k][tx];}__syncthreads();}P_device[y * width + x] = P_element;
}__global__ void MatmulSharedDynamicKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){/* 声明动态共享变量的时候需要加extern,同时需要是一维的 注意这里有个坑, 不能够像这样定义: __shared__ float M_deviceShared[];__shared__ float N_deviceShared[];因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行*/extern __shared__ float deviceShared[];int stride = blockSize * blockSize;/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockSize + threadIdx.x;int y = blockIdx.y * blockSize + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */for (int m = 0; m < width / blockSize; m ++) {deviceShared[ty * blockSize + tx] = M_device[y * width + (m * blockSize + tx)];deviceShared[stride + (ty * blockSize + tx)] = N_device[(m * blockSize + ty)* width + x];__syncthreads();for (int k = 0; k < blockSize; k ++) {P_element += deviceShared[ty * blockSize + k] * deviceShared[stride + (k * blockSize + tx)];}__syncthreads();}if (y < width && x < width) {P_device[y * width + x] = P_element;}
}/*使用Tiling技术一个tile处理的就是block, 将一个矩阵分为多个小的tile,这些tile之间的执行独立,并且可以并行
*/
void MatmulSharedOnDevice(float *M_host, float *N_host, float* P_host, int width, int blockSize, bool staticMem){/* 设置矩阵大小 */int size = width * width * sizeof(float);long int sMemSize = blockSize * blockSize * sizeof(float) * 2;/* 分配M, N在GPU上的空间*/float *M_device;float *N_device;CUDA_CHECK(cudaMalloc((void**)&M_device, size));CUDA_CHECK(cudaMalloc((void**)&N_device, size));/* 分配M, N拷贝到GPU上*/CUDA_CHECK(cudaMemcpy(M_device, M_host, size, cudaMemcpyHostToDevice));CUDA_CHECK(cudaMemcpy(N_device, N_host, size, cudaMemcpyHostToDevice));/* 分配P在GPU上的空间*/float *P_device;CUDA_CHECK(cudaMalloc((void**)&P_device, size));;/* 调用kernel来进行matmul计算, 在这个例子中我们用的方案是:使用一个grid,一个grid里有width*width个线程 */dim3 dimBlock(blockSize, blockSize);dim3 dimGrid(width / blockSize, width / blockSize);if (staticMem) {MatmulSharedStaticKernel <<<dimGrid, dimBlock>>> (M_device, N_device, P_device, width);} else {MatmulSharedDynamicKernel <<<dimGrid, dimBlock, sMemSize, nullptr>>> (M_device, N_device, P_device, width, blockSize);}/* 将结果从device拷贝回host*/CUDA_CHECK(cudaMemcpy(P_host, P_device, size, cudaMemcpyDeviceToHost));CUDA_CHECK(cudaDeviceSynchronize());/* 注意要在synchronization结束之后排查kernel的错误 */LAST_KERNEL_CHECK(); /* Free */cudaFree(P_device);cudaFree(N_device);cudaFree(M_device);
}main.cpp
#include <stdio.h>
#include <cuda_runtime.h>#include "utils.hpp"
#include "timer.hpp"
#include "matmul.hpp"int seed;
int main(){Timer timer;int width = 1<<12; // 4,096int low = 0;int high = 1;int size = width * width;int blockSize = 16;bool statMem = true;char str[100];float* h_matM = (float*)malloc(size * sizeof(float));float* h_matN = (float*)malloc(size * sizeof(float));float* h_matP = (float*)malloc(size * sizeof(float));float* d_matP = (float*)malloc(size * sizeof(float));// seed = (unsigned)time(NULL);seed = 1;initMatrix(h_matM, size, low, high, seed);seed += 1;initMatrix(h_matN, size, low, high, seed);LOG("Input size is %d x %d", width, width);/* GPU warmup */timer.start_gpu();MatmulOnDevice(h_matM, h_matN, h_matP, width, blockSize);timer.stop_gpu();timer.duration_gpu("matmul in gpu(warmup)");/* GPU general implementation <<<256, 16>>>*/timer.start_gpu();MatmulOnDevice(h_matM, h_matN, d_matP, width, blockSize);timer.stop_gpu();std::sprintf(str, "matmul in gpu(without shared memory)<<<%d, %d>>>", width / blockSize, blockSize);timer.duration_gpu(str);compareMat(h_matP, d_matP, size);// /* GPU general implementation <<<256, 16>>>*/timer.start_gpu();MatmulSharedOnDevice(h_matM, h_matN, d_matP, width, blockSize, statMem);timer.stop_gpu();std::sprintf(str, "matmul in gpu(with shared memory(static))<<<%d, %d>>>", width / blockSize, blockSize);timer.duration_gpu(str);compareMat(h_matP, d_matP, size);/* GPU general implementation <<<256, 16>>>*/statMem = false;timer.start_gpu();MatmulSharedOnDevice(h_matM, h_matN, d_matP, width, blockSize, statMem);timer.stop_gpu();std::sprintf(str, "matmul in gpu(with shared memory(dynamic))<<<%d, %d>>>", width / blockSize, blockSize);timer.duration_gpu(str);compareMat(h_matP, d_matP, size);return 0;
}编译和运行指令:
mkdir build
cd build
cmake ..
make
./demo
运行结果:

这里为了计时更加的准确,使用了 stream 和 event,详细的相关内容主要看 .cu 文件
可以看到使用共享内存会比不使用的时候快。
总结
1、共享内存是可受用户控制的一级缓存。
2、共享内存是基于存储体切换的架构。所以我们必须要解决存储体冲突的问题
3、适合用共享内存的场景:
- 数据重复利用
- 全局内存合并
- 线程之间有共享数据
4、线程访问共享内存的时候需要排队等候
5、以行的方式访问全局内存的时候,性能最好
6、在GPU上线程块的大小或者线程束的大小可以理想地映射为数据集的大小。对于一个长为N的数据,我们可以最多用N/2个线程来进行。
7、共享内存的主要作用是减少对全局内存的访问,或者改善对全局内存的访问模式