教程链接 — https://youtu.be/w6wOhSThnoo
摘要是自然语言处理(NLP)的一个关键方面,它能够将大量文本浓缩成简洁的摘要。LangChain,作为NLP领域中的一个强大工具,提供了三种不同的摘要技术:stuff、map_reduce和refine。每种方法都有其独特的优点和局限性,使它们适用于不同的情况。本文深入探讨了这些技术的细节、它们的优缺点以及理想的应用场景。
教程中使用的完整实现代码和数据可在以下存储库中找到。
摘要技术
来自langchain
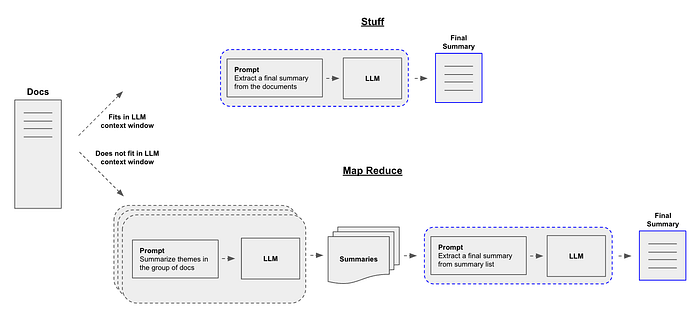
- Stuff Chain
stuff链特别适用于处理大型文档。它的工作原理是将文档转换为较小的块,分别处理每个块,然后将摘要组合起来生成最终摘要。这种方法适用于管理庞大的文件,并且可以通过递归字符文本分割器的帮助来实现。
优点:
- 高效处理大型文档。
- 允许逐块摘要,适合管理庞大的文件。
缺点:
- LLM上下文窗口
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate # 定义提示
prompt_template = """Write a concise summary of the following:
"{text}"
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
# 定义 LLM 链
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
llm_chain = LLMChain(llm=llm, prompt=prompt)
# 定义 StuffDocumentsChain
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
docs = loader.load()
print(stuff_chain.run(docs))
Map-Reduce 方法
映射-归约方法涉及分别对每个文档进行摘要(映射步骤),然后将这些摘要组合成最终摘要(归约步骤)。这种方法更可扩展,并且可以处理更大量的文本。map_reduce技术旨在摘要超出语言模型令牌限制的大型文档。它涉及将文档分成块,为每个块生成摘要,然后将这些摘要组合起来创建最终摘要。这种方法对处理大型文件高效,并且显著减少了处理时间。
优点:
- 通过将大型文档分成可管理的块来有效处理。
- 通过分别处理块来减少处理时间。
缺点:
- 需要额外的步骤来组合单独的摘要,这可能会增加过程的复杂性。
以下是如何实现映射-归约方法的示例:
from langchain.chains import MapReduceDocumentsChain, ReduceDocumentsChain
from langchain_text_splitters import CharacterTextSplitter # 映射
map_template = """The following is a set of documents
{docs}
Based on this list of docs, please identify the main themes
Helpful Answer:"""
map_prompt = PromptTemplate.from_template(map_template)
map_chain = LLMChain(llm=llm, prompt=map_prompt)
# 归约
reduce_template = """The following is set of summaries:
{docs}
Take these and distill it into a final, consolidated summary of the main themes.
Helpful Answer:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)
# 通过映射链组合文档,然后组合结果
map_reduce_chain = MapReduceDocumentsChain( llm_chain=map_chain, reduce_documents_chain=reduce_documents_chain, document_variable_name="docs", return_intermediate_steps=False,
)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
print(map_reduce_chain.run(split_docs))
Refine 方法
Refine方法通过循环遍历输入文档来迭代更新其答案。对于每个文档,它将所有非文档输入、当前文档和最新的中间答案传递给LLM链以获得新答案。这种方法适用于根据新上下文细化摘要。
refine技术是map_reduce技术的简单替代方案。它涉及为第一个块生成摘要,将其与第二个块组合,生成另一个摘要,并继续这个过程,直到最终摘要完成。这种方法适用于大型文档,但与map_reduce相比,需要的复杂性较小。
优点:
- 比
map_reduce技术更简单。 - 对于大型文档,以较小的复杂性实现了类似的结果。
缺点:
- 与其它技术相比,功能有限。
以下是如何实现Refine方法的示例:
from langchain.chains.summarize import load_summarize_chain
prompt = """Please provide a summary of the following text.TEXT: {text}SUMMARY:"""question_prompt = PromptTemplate(template=question_prompt_template, input_variables=["text"]
)refine_prompt_template = """Write a concise summary of the following text delimited by triple backquotes.Return your response in bullet points which covers the key points of the text.```{text}```BULLET POINT SUMMARY:"""refine_template = PromptTemplate(template=refine_prompt_template, input_variables=["text"]# Load refine chain
chain = load_summarize_chain(llm=llm,chain_type="refine",question_prompt=question_prompt,refine_prompt=refine_prompt,return_intermediate_steps=True,input_key="input_documents",output_key="output_text",
)
result = chain({"input_documents": split_docs}, return_only_outputs=True)
选择合适的技术
摘要技术的选择取决于当前任务的具体要求。对于大型文档,建议使用map_reduce和refine技术,因为它们能够有效地进行分块摘要。stuff链特别适合于太大而无法一次性处理的文档,为管理庞大的文件提供了实用的解决方案。
每种方法都有其优势,适用于不同场景。Stuff方法简单但可能不适用于处理大量文本。Map-Reduce方法更可扩展,可以处理更大的文档,但需要更多的设置。Refine方法适用于基于新上下文迭代细化摘要,使其成为动态摘要任务的良好选择。