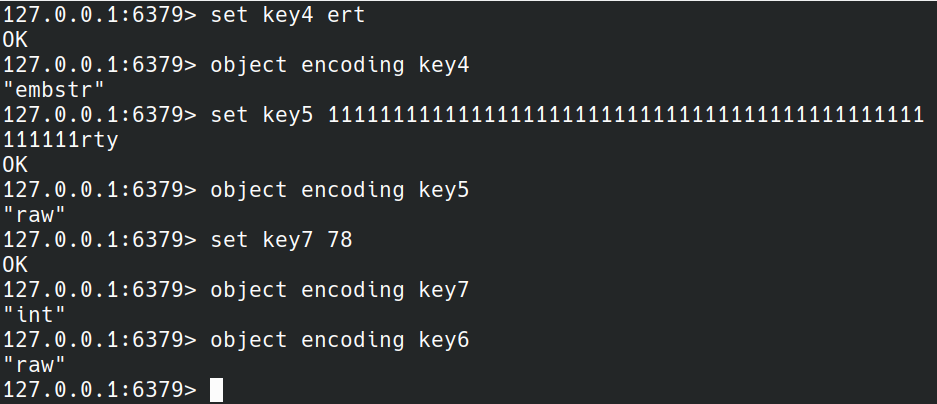
双向广搜
- 用途一:小优化
- BFS 的剪枝策略,分两侧展开分支,哪侧数量少就从哪侧展开
- 用途二:
- 特征:全量样本不允许递归完全展开,但是半量样本可以完全展开。(完全展开的过程中有可能能够进行分组,进行常数级优化)
- 过程:把数据分成两部分,每部分各自展开计算结果,然后设计两部分结果的整合逻辑
127. 单词接龙
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_set>using namespace std;class Solution {
public:int ladderLength(string beginWord, string endWord, vector<string> &wordList) {// 字符表unordered_set<string> dict;for (const auto &item: wordList)dict.emplace(item);if (dict.find(endWord) == dict.end()) return 0;// 数量小的一侧unordered_set<string> smallLevel;// 数量大的一侧unordered_set<string> bigLevel;// 由数量小的一侧,往外扩展出的下一层unordered_set<string> nextLevel;smallLevel.emplace(beginWord);bigLevel.emplace(endWord);int len = 2;while (!smallLevel.empty()) {// 从小侧扩展,查看这个单词能否通过改动一个字符变成字符表里的某个尚未处理过的字符for (string word: smallLevel) {string nw = word;// 对每个位置尝试换成所有的小写字母for (int i = 0; i < nw.length(); ++i) {char oldCh = nw[i];for (char ch = 'a'; ch <= 'z'; ch++) {// 跳过原本的字符if (ch == oldCh) continue;nw[i] = ch;// 两端碰头if (bigLevel.find(nw) != bigLevel.end()) return len;// 字符表中能找到,也就是说原始字符能变动成字符表中的某个尚未处理过的字符if (dict.find(nw) != dict.end()) {nextLevel.emplace(nw);// 已经处理过dict.erase(nw);}}// 回溯nw[i] = oldCh;}}if (nextLevel.size() > bigLevel.size()) {// 由 smallLevel 扩展出的 nextLevel 集合元素比 bigLevel 多auto newSmall = bigLevel;auto newBig = nextLevel;smallLevel = newSmall;bigLevel = newBig;} else {auto newSmall = nextLevel;smallLevel = newSmall;}nextLevel.clear();len++;}return 0;}
};
P4799 [CEOI2015 Day2] 世界冰球锦标赛
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_set>
#include <algorithm>using namespace std;long N, M;
vector<long> prices;// sums 中记录 prices 中从 left 到 right 为止,每个位置选或者不选所得到的结果中小于等于 M 的
void generate(int left, int right, long tempSum, vector<long> &sums) {if (tempSum > M) return;if (left > right) {sums.emplace_back(tempSum);return;};// 不要 prices[left]generate(left + 1, right, tempSum, sums);// 要 prices[left]generate(left + 1, right, tempSum + prices[left], sums);
}int main() {cin >> N >> M;prices.resize(N);for (int i = 0; i < N; ++i)cin >> prices[i];// 把数据分成两部分,每部分各自展开计算结果vector<long> leftSum;vector<long> rightSum;long mid = N >> 1;generate(0, mid - 1, 0, leftSum);generate(mid, N - 1, 0, rightSum);// 排序,方便整合两个部分的计算结果sort(leftSum.begin(), leftSum.end());sort(rightSum.begin(), rightSum.end());// 总的购买方案long res = 0;long lSize = leftSum.size();long rSize = rightSum.size();long left = 0;long right = rSize - 1;// 每次累加的是在以先选择左侧结果中总费用的情况下,从右侧结果中可选择的方案数while (left < lSize) {while (right >= 0 && leftSum[left] + rightSum[right] > M)right--;res += right + 1;left++;}cout << res;
}
1755. 最接近目标值的子序列和
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;class Solution {
public:void generate(vector<int> &nums, int left, int right, long sum, vector<long> &sums) {if (left == right + 1) {sums.emplace_back(sum);return;}// 子序列中不包含 nums[left]generate(nums, left + 1, right, sum, sums);// 子序列中包含 nums[left]generate(nums, left + 1, right, sum + nums[left], sums);}int minAbsDifference(vector<int> &nums, int goal) {vector<long> leftSums;vector<long> rightSums;int mid = nums.size() >> 1;generate(nums, 0, mid - 1, 0, leftSums);generate(nums, mid, nums.size() - 1, 0, rightSums);sort(begin(leftSums), end(leftSums));sort(begin(rightSums), end(rightSums));long lSize = leftSums.size();long rSize = rightSums.size();long left = 0;long right = rSize - 1;long res = LONG_MAX;// 考察每种在 leftSums[left] 的方案下,rightSums 中最满足要求的方案 rightSums[right]// 这样就不会遗漏由于分成两个部分进行全排列所丢失的那部分方案// 优化就是在总和小于目标时,应该让方案得到的序列和变大,也就是 left++// 而不是继续固定死 left,去 right--,因为 right-- 只会让序列和更小while (left < lSize && right >= 0) {int t = leftSums[left] + rightSums[right];if (t == goal) {return 0;} else if (t < goal) {if (goal - t < res) res = goal - t;left++;} else if (t > goal) {if (t - goal < res) res = t - goal;right--;}}return res;}
};
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;class Solution {
public:// 常数级优化 2.2void generate(vector<int> &nums, int left, int right, long sum, vector<long> &sums) {if (left == right + 1) {sums.emplace_back(sum);return;}// left 作为这组相同数字的开头// 把 cur 移动到这组相同数字的末尾int cur = left;while (cur + 1 <= right && nums[cur + 1] == nums[cur])cur++;// 这组数字的长度int len = cur - left + 1;// 剪枝:这组数字选 i 个,选哪几个无所谓。从 2 ^ len 减少到 len + 1for (int i = 0; i <= len; ++i)generate(nums, cur + 1, right, sum + i * nums[left], sums);}int minAbsDifference(vector<int> &nums, int goal) {// 常数级优化 1// 负数累加和long negativeSum = 0;// 正数累加和long positiveSum = 0;for (int i = 0; i < nums.size(); ++i) {if (nums[i] > 0) positiveSum += nums[i];if (nums[i] < 0) negativeSum += nums[i];}if (negativeSum > goal) return negativeSum - goal;if (positiveSum < goal) return goal - positiveSum;// 常数级优化 2.1// 排序主要是为了将相同的数字靠在一起,在暴力递归的时候分组递归,而不是按照每个位置进行递归sort(nums.begin(), nums.end());vector<long> leftSums;vector<long> rightSums;int mid = nums.size() >> 1;generate(nums, 0, mid - 1, 0, leftSums);generate(nums, mid, nums.size() - 1, 0, rightSums);sort(begin(leftSums), end(leftSums));sort(begin(rightSums), end(rightSums));long lSize = leftSums.size();long rSize = rightSums.size();long left = 0;long right = rSize - 1;long res = LONG_MAX;// 考察每种在 leftSums[left] 的方案下,rightSums 中最满足要求的方案 rightSums[right]// 这样就不会遗漏由于分成两个部分进行全排列所丢失的那部分方案// 优化就是在总和小于目标时,应该让方案得到的序列和变大,也就是 left++// 而不是继续固定死 left,去 right--,因为 right-- 只会让序列和更小while (left < lSize && right >= 0) {int t = leftSums[left] + rightSums[right];if (t == goal) {return 0;} else if (t < goal) {if (goal - t < res) res = goal - t;left++;} else if (t > goal) {if (t - goal < res) res = t - goal;right--;}}return res;}
};