存储过程
存储过程(Stored Procedure)是一种在数据库中保存的SQL语句集合,它可以执行一系列的数据库操作,例如插入、更新、查询等。存储过程可以提高数据库操作的效率,减少网络流量,并且可以封装复杂的逻辑。
- 定义:
存储过程是一组为了完成特定功能的SQL语句集,这些语句被存储在数据库中,可以重复使用。 - 性能:
因为存储过程在数据库服务器上执行,减少了网络传输的数据量,提高了执行效率。 - 安全性:
通过限制对数据库的直接访问,增强了数据的安全性。 - 重用性:
相同的存储过程可以被多个应用程序调用,减少代码重复。
语法结构
CREATE DEFINER=`root`@`localhost` PROCEDURE Demo(IN START INT(10),IN max_num INT(10))
# DEFINER=`root`@`localhost` 指定所有者,标识【root用户】,【本地主机】才可以执行该存储过程,否则无法执行(可以不写)
# Demo为定义的存储过程名,()内为参数,可以没有参数
# 参数可以是输入(IN)、输出(OUT)或输入/输出(INOUT)类型的
BEGINSELECT 'Hello, World!'; # 过程体语句
END


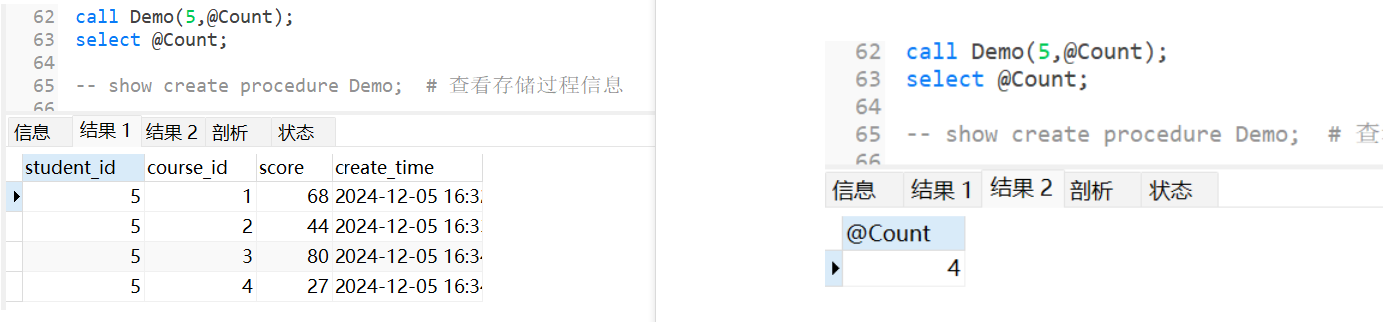
调用
call Demo(5,@Count); # 调用Demo存储过程,并传入参数5,并定义输出参数(根据参数位置进行定义,参数命名需要@开头名字任意字符进行定义)
select @Count; # 打印输出参数
执行结果
示例:批量插入多条数据
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_course`(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEATSET i = i + 1;INSERT INTO course (teacher_id,name) VALUES (i+1,"计算机");
UNTIL i = max_num
END REPEAT;
COMMIT;
END
调用
call insert_course(1,10);
执行结果

存储过程的应用场景
- 数据库事务处理
存储过程可以将多个SQL语句组合在一起,以实现事务处理。如果其中任何一个SQL语句失败,整个事务将被回滚,从而确保数据的一致性和完整性。 - 简化数据库操作
存储过程可以将复杂的SQL语句封装起来,客户端只需调用存储过程名即可执行复杂的操作,简化了客户端与数据库之间的交互。 - 提高性能
存储过程在数据库中编译后,可以被多个客户端共享,减少了网络传输的开销,提高了执行效率。此外,存储过程可以利用数据库的优化器和索引等特性,进一步提高查询性能。 - 保证数据一致性
存储过程可以封装业务逻辑和数据验证逻辑,确保只有符合规则的数据才能被插入或更新,从而保证了数据的一致性和安全性。 - 自动化和批处理
存储过程可以封装批量插入、更新和删除等操作,实现数据的自动化处理。此外,存储过程还可以与触发器、事件等结合使用,实现更高级别的自动化和批处理功能。 - 业务逻辑处理
当业务逻辑复杂时,可以将这些逻辑封装在存储过程中,提高代码的可读性和可维护性。(如:数据清洗、数据转移、批处理任务等。) - 安全控制
通过存储过程,可以对输入参数进行验证,提高数据的安全性。
函数
函数与存储过程类似,但与存储过程不同的是,函数必须返回一个值。函数通常用于计算或返回数据。
存储函数是有返回值的存储过程,存储函数的参数只能是in类型的。
存储函数必须要有返回值
CREATE FUNCTION function_name (parameter_list)
RETURNS return_datatype
[characteristic ...]
BEGIN-- 函数体RETURN value;
END;参数说明:
function_name: 函数的名称。
parameter_list: 函数的参数列表,可以有多个参数,每个参数由参数名和数据类型组成。
return_datatype: 函数返回的数据类型。
characteristic: 函数的特性,例如 DETERMINISTIC(表示函数对于给定的输入总是返回相同的结果)。
BEGIN ... END;: 函数体,其中包含了函数的 SQL 语句和逻辑。
RETURN value;: 函数返回一个值。
示例:定义一个返回字符串长度的函数
DELIMITER $$CREATE FUNCTION get_string_length(input_string VARCHAR(255))
RETURNS INT
DETERMINISTIC
BEGINRETURN CHAR_LENGTH(input_string);
END$$DELIMITER ;
示例:定义一个计算两个数字和的函数
DELIMITER $$CREATE FUNCTION add_numbers(num1 INT, num2 INT)
RETURNS INT
DETERMINISTIC
BEGINRETURN num1 + num2;
END$$DELIMITER ;
调用函数
select add_numbers(1,3);
函数删除操作
drop function add_numbers;
函数的应用场景
- 数据清洗和格式化
- 日期格式化
使用DATE_FORMAT函数可以将系统时间转化成指定格式的字符串。例如,查询2019年12月份的数据可以使用DATE_FORMAT(clock_time,'%Y-%m')='2019-12'。 - 字符串拼接
使用CONCAT函数可以将多个字符串连接在一起。例如,CONCAT('Hello', ' ', 'MySQL')可以生成Hello MySQL。 - 字符串截取
使用SUBSTRING函数可以截取字符串的一部分。例如,SUBSTRING('Hello MySQL', 1, 5)会返回Hello。
- 日期格式化
- 数据分析
- 日期计算
使用DATEDIFF函数计算两个日期之间的天数差,例如计算入职天数。使用DATEDIFF(current_date, hire_date)可以计算当前日期与入职日期之间的天数。 - 聚合函数
使用COUNT()、SUM()、AVG()、MAX()和MIN()等聚合函数进行数据汇总和统计分析。例如,计算表中的行数可以使用COUNT(*),计算某列的总和可以使用SUM(column)。
- 日期计算
- 数据处理和转换
- 条件判断
使用IF()和CASE WHEN...THEN...ELSE...END进行条件判断和数据转换。例如,根据条件返回不同的值可以使用IF(condition, value_if_true, value_if_false)。 - 数值处理
使用ABS()、ROUND()、RAND()等函数进行数值处理。例如,四舍五入数字到指定的小数位数可以使用ROUND(num, dec)。
- 条件判断
- 特定业务场景的应用
- 员工入职天数计算
在企业的OA系统中,可以使用MySQL函数计算员工入职天数。例如,使用DATEDIFF(current_date, hire_date)计算当前日期与入职日期之间的天数差。 - 分数等级判定
在做报表时,可以使用MySQL函数快速判定分数的等级。例如,使用条件判断函数根据分数值判定等级。
- 员工入职天数计算
触发器
触发器(Trigger)是一种特殊的存储过程。
它与表有关,当表上的特定事件(insert,update,delete)发生时,触发器会自动执行。
可以使用触发器来实现数据约束,数据验证,数据复制等功能。
create trigger 触发器名称
{before | after } {insert | update | delete} -- 触发器类型和事件
on 表名称
for each row -- 触发器的作用范围
begin-- 触发器执行的操作
end;参数说明:
before / after : 表示触发器的类型,分别表示发生前/发生后执行
insert / update / delete : 表示触发器的事件类型,分别表示插入 / 更新 / 删除操作
on 表名称 : 为触发器所在的表名
for each row : 表示触发器作用的范围,即每一行记录都会触发该触发器
begin 和 end之间是触发器执行的操作,可以是一条或者多条SQL语句
调用方式
触发器是自动执行的,无需手动调用。
当表上的特定事件(insert , update, delete) 发生时,触发器会自动执行。
在创建触发器时,可以定义触发器的类型和事件,从而控制触发器的时机和条件。
示例:添加事件
-- 创建一个触发器,当向表中插入一条记录时,自动向另一个表中插入一条记录
create trigger insert_trigger_1
after insert on table1for each rowbegin-- 触发器的具体事件insert into table2(id,name) values (NEW.id,New.name);end;
添加数据
insert into table1(id,name) values (1,'kobe'),(2,'lebron'),(3,'curry'),(4,'durant'),(5,'paul'),(6,'westbrook');
向table1表中添加数据时,会触发insert_trigger_1触发器,自动向table2表中添加数据
同理删除事件/修改事件,则将触发器事件类型
insert改为delete/update,sql语句改为删除语句
删除触发器
drop trigger 触发器名称;
触发器的应用场景
- 强制实施业务规则
- 通过在触发器中编写逻辑,可以在特定的表上自动执行业务规则,例如检查输入的数据是否符合要求,或者限制某些操作的执行。
- 记录日志变更
- 通过在触发器中编写逻辑,可以在特定的表上自动记录数据的变更情况,例如记录数据的修改时间、修改人等信息。
- 复杂的默认值计算
- 通过在触发器中编写逻辑,可以在特定的表上自动计算默认值,例如根据其他字段的值计算出一个新的字段的值。
- 数据同步
- 通过在触发器中编写逻辑,可以在多个表之间自动同步数据,例如在一个表中插入一条数据时,自动在另一个表中插入相应的数据。
- 数据校验
- 通过在触发器中编写逻辑,可以在特定的表上自动校验数据的正确性,例如检查数据的唯一性、完整性等。
存储过程/函数/触发器区别
定义和用途
- 触发器(Trigger)
触发器是一种特殊的存储过程,它不是由程序调用,而是通过事件(如INSERT、UPDATE、DELETE操作)自动触发执行。触发器主要用于数据验证、审计、日志记录和自动更新等场景,确保数据的一致性和完整性。 - 存储过程(Stored Procedure)
存储过程是一组为了完成特定功能的SQL语句和控制结构的集合,存储在数据库中。它们可以被外部程序调用,用于执行复杂的数据库操作,如数据转换、数据迁移和报表生成。存储过程可以接受参数、返回结果,并且可以隐藏数据库的复杂性,简化应用开发。 - 存储函数(Stored Function)
存储函数与存储过程类似,但必须返回一个值。它们通常用于计算字段值或执行需要返回结果的数据库操作。
存储过程/函数/触发器 语法
# 查看存储过程的定义
show create procedure 存储过程名;
# 查询指定数据库的存储过程及状态信息
select * from information_schema.routines where routine_schema='数据库名';
# 删除存储过程
drop procedure 存储过程名;
变量
系统变量
系统变量是mysql服务器提供的,分为全局变量(global)、会话变量(session)
show global variables; # 查看所有变量(不写global是检索当前会话的变量,写global是检索mysql全局的变量)show global variables like '匹配内容'; # 通过like模糊匹配查找变量,_匹配单字符,%匹配多字符用户变量
用户可以自定义变量,不需提前声明。
用户变量的使用只限于当前会话(当前查询会话)。
# 赋值语句
set @变量名=值;
select 字段名 into @变量名 from 表名; # 直接把表内字段的数据作为变量的值,方式一
select 字段名 from 表名 into @变量名;# 直接把表内字段的数据作为变量的值,方式二# 查看变量的值
select @变量名;
示例
# 定义用户变量
set @aaa="123",@ccc="333";
select count(*) INTO @bbb from score where student_id = 4 ;
# 查看用户变量
select @aaa,@bbb,@ccc;
局部变量
局部变量需要declare声明,其范围是在一个存储过程/函数/触发器的begin到end之间。
declare 变量名 变量类型[default 默认值]; # 在声明的时候可以直接设置一个默认值(变量类型有int、char、varchar等等)
示例:定义变量
DELIMITER //
CREATE DEFINER=`root`@`localhost` PROCEDURE `Demo1`(IN id INT(10),OUT subject_count INT)
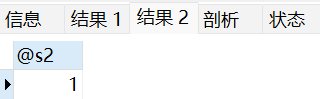
BEGINdeclare s1 int default 0; # stu局部变量默认值为0set @s2=1; # 会话变量stsselect count(*) into s1 from score where student_id = 3 ;select @s2,s1;
END //
DELIMITER ;
call Demo1(1,@ss);
select @s2;
执行结果

declare应用场景:可以定义变量、条件处理器、游标。
delimiter 分隔符
DELIMITER命令是为了改变MySQL命令结束的标识符。在这个例子中,我们将命令的结束符设置为//以便在存储过程中处理多条语句。
begin...end
主要用于定义一个代码块,这个代码块可以用于存储过程、函数和触发器中。
BEGIN...END在存储过程中起到了定义代码块的作用,帮助组织和管理存储过程中的逻辑。
存储过程中可以有多个begin...end
if...else
if判断是在begin与end间使用
语法:if 条件1 then代码1elseif 条件2 then #可选代码2else #可选代码3end if;# 如果 符合条件1 则进入代码1,否则如果符合条件2则进入代码2,否则进入代码3
# 示例:
create procedure p(in sc char(10),in sc2 char(10))
begin declare result varchar(10);declare sum int;select grade into sum from score where sno = sc and cno = sc2; if sum >= 85 thenset result = '优秀';elseif sum>=60 thenset result = '及格';elseset result = '不及格';end if;select result;
end;-- call p('2015001','c02');case语句
方式一:值(1/2)
case 值when 值1 then 语句1when 值2 then 语句2...else 语句3
end else;# case后的值是值1就执行语句1,是值2就执行语句2
方式二:表达式
casewhen 条件表达式1 then 语句1when 条件表达式2 then 语句2...else 语句3
end else;# 条件表达式1为true就执行语句1,条件表达式2为true就执行语句2,否则执行语句3示例:
create PROCEDURE p2(in month int)
begin
declare result varchar(10);
casewhen month>=1 and month<=3 thenset result = '第一季度';when month>=4 and month<=6 thenset result = '第二季度';when month>=7 and month<=9 thenset result = '第三季度';when month>=10 and month<=12 thenset result = '第四季度';elseset result = '非法参数';end case;select concat('您输入的月份为:',month,'所属的季度为:',result);
end;
-- call p2(1);
while循环语句
# 先判断条件,如果条件为true,则执行逻辑,否则,不执行
while 条件 dosql逻辑代码
end while;# 示例
create procedure p7(in n int)
begindeclare total int default 0;while n>0 doset total :=total + n;set n :=n - 1;end while;select total;
end;# 计算从1累加到n的值,n为入参值
# 通过局部变量total,进行循环累加,直到n等于0时,则退出循环
repeat循环语句
与while语句的区别是:while是符合条件才进行循环,repeat是满足条件才跳出循环
# 先判断条件,当满足条件时退出循环
# 先执行一次逻辑,然后判定逻辑是否满足,如果满足则退出,否则继续
repeatsql逻辑代码until 条件
end repeat;# 示例
create procedure p7(in n int)
begindeclare total int default 0;repeatset total :=total + n;set n :=n - 1;until n<=0end repeat;select total;
end;
loop循环语句
loop可实现简单的循环,如果不在SQL逻辑中增加退出循环的条件,可以实现简单的死循环。
loop循环本身是没有退出条件,需要自行添加退出语句:
- leave:配合循环使用,退出循环。
- iterate:必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环。
语法:标记名:loopSQL逻辑代码end loop 标记名;leave lable; #退出指定标记的循环体iterate label; #直接进入下一次循环# 示例
create procedure p7(in n int)
begindeclare total int default 0;sum:loopif n<=0 thenleave sum;end if;set total :=total + n;set n :=n - 1;end loop sum;select total;
end;
游标cursor
游标是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。
游标的使用包括游标游标(CURSOR)的声明、OPEN、FETCH和 CLOSE,其语法如下:
DECLARE 游标名称 CURSOR FOR 查询语句; # 声明游标
OPEN 游标名称; # 打开游标
FETCH 游标名称 INTO 变量,变量...; # 获取游标记录
CLOSE 游标名称; # 关闭游标# 示例
# 根据传入的参数age,查询students表中,所有学生出生日期小于age的用户姓名和专业,并将用户的姓名和专业插入到一个新表中
# 思路:A:声明游标,B:创建表,C:开启游标,D:获取游标中的记录,E:插入数据到新表,F:关闭游标
create PROCEDURE p7(
in uage date #传入出生日期
)
begindeclare usname varchar(100); #保存符合条件的学生信息的两个局部变量declare upro varchar(100);declare u_cursor cursor for #声明游标,select sname,smajor from students where sbirthday<uage; #找出 出生日期大于uage的#如果存在则删除,这样的话就保证表中只显示比uage大的学生信息drop table if exists tb_user; create table if not exists tb_user( #创建表id int primary key auto_increment, #id设置自增主键uname varchar(100),sdapt varchar(100));open u_cursor; #打开游标while true do #进入while循环fetch u_cursor into usname,upro; # 把游标中的记录存入两个局部变量insert into tb_user values(null,usname,upro); #插入新表end while;close u_cursor; #关闭游标
end;
call p7('1999-03-1');
条件处理程序handler
handler可以用来定义在流程执行中遇到问题时的处理步骤。分为继续、停止2种。其语法如下:
declare continue handler for 状态1,状态2... SQL语句; # 当出现语句中的状态时,继续执行当前程序
declare exit handler for 状态1,状态2... SQL语句; # 当出现语句中的状态时,停止执行当前程序
语句中的状态有4种:
- sqlstate: 状态码
状态码比如02000,代表没得到数据 - sqlwaring:所有以01开头的状态码
- not found:所有以02开头的状态码
- sqlexception:01、02开头以外的其他状态码

![[Tools] GitHub Action 部署文档网站](https://resource.duyiedu.com/xiejie/2023-06-09-063500.png)
![[Tools] VitePress搭建文档网站](https://resource.duyiedu.com/xiejie/2023-06-09-024255.jpg)