1、Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
提高采样速度2种方法:schedular优化、蒸馏
本论文基于DDIM,DDPM训练出来的epsilon theta 可以直接用于DDIM。由于DDIM的降噪过程是确定的,但是step多,由此定义了一个确定的教师分布,因此训练一个学生模型使得最终分布和教师分布一样。
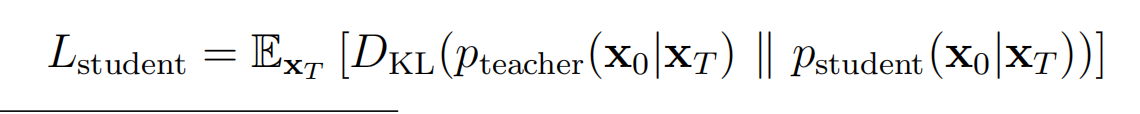
将2个分布视为高斯分布,学生分布为具有可训练参数的均值的分布,因此上式等价于:
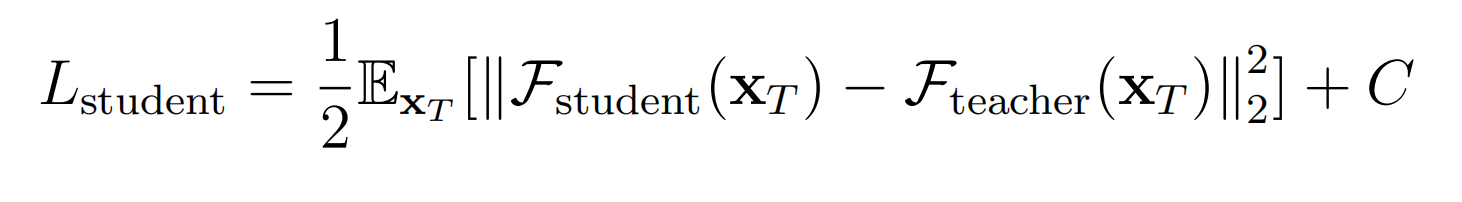
学生模型的网络可以是任意的,这里直接设置为和教师的 epsilon theta 的架构和权重一致,以便加速。
改进:由于 学生模型的网络 的初始化输出一般和噪声一样,所以用XT - 学生网络的输出 作为预测的样本X0,然后算loss。